 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal- and Holistic- Structure Preserving Image Super Resolution via Deep Joint Component Learning
Paper and Code
Jul 25, 2016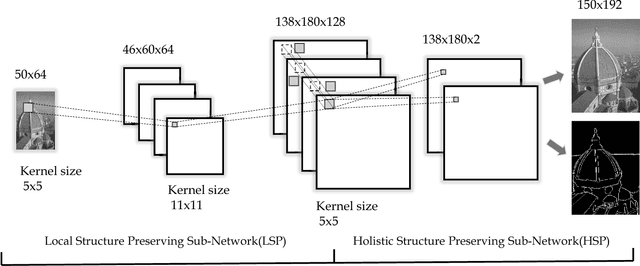
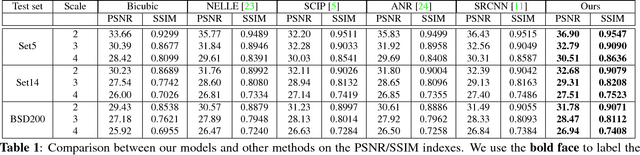
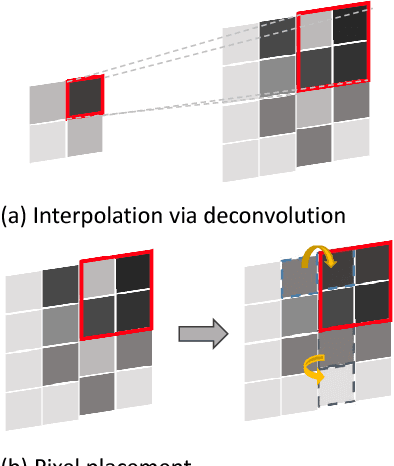
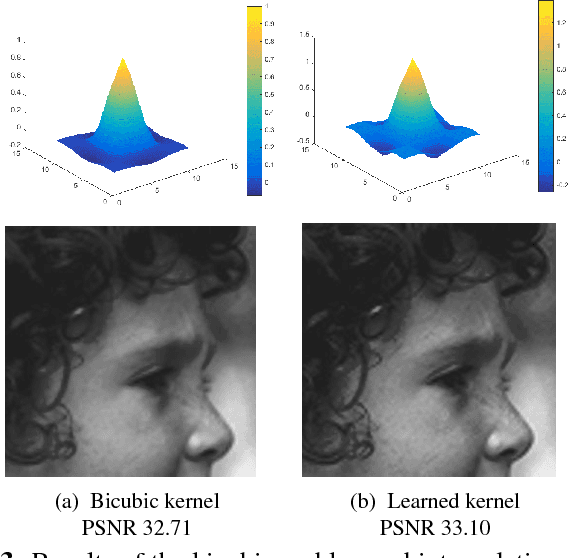
Recently, machine learning based single image super resolution (SR) approaches focus on jointly learning representations for high-resolution (HR) and low-resolution (LR) image patch pairs to improve the quality of the super-resolved images. However, due to treat all image pixels equally without considering the salient structures, these approaches usually fail to produce visual pleasant images with sharp edges and fine details. To address this issue, in this work we present a new novel SR approach, which replaces the main building blocks of the classical interpolation pipeline by a flexible, content-adaptive deep neural networks. In particular, two well-designed structure-aware components, respectively capturing local- and holistic- image contents, are naturally incorporated into the fully-convolutional representation learning to enhance the image sharpness and naturalness. Extensively evaluations on several standard benchmarks (e.g., Set5, Set14 and BSD200) demonstrate that our approach can achieve superior results, especially on the image with salient structures, over many existing state-of-the-art SR methods under both quantitative and qualitative measures.