 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS2ST-Omni: An Efficient and Scalable Multilingual Speech-to-Speech Translation Framework via Seamlessly Speech-Text Alignment and Streaming Speech Decoder
Jun 16, 2025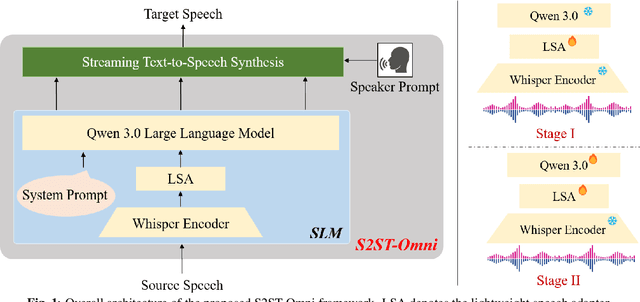
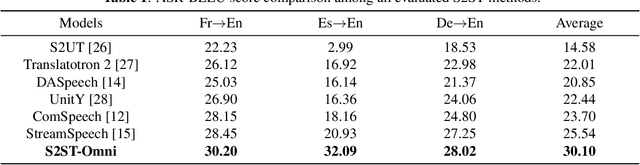
Multilingual speech-to-speech translation (S2ST) aims to directly convert spoken utterances from multiple source languages into fluent and intelligible speech in a target language. Despite recent progress, several critical challenges persist: 1) achieving high-quality and low-latency S2ST remains a significant obstacle; 2) most existing S2ST methods rely heavily on large-scale parallel speech corpora, which are difficult and resource-intensive to obtain. To tackle these challenges, we introduce S2ST-Omni, a novel, efficient, and scalable framework tailored for multilingual speech-to-speech translation. To enable high-quality S2TT while mitigating reliance on large-scale parallel speech corpora, we leverage powerful pretrained models: Whisper for robust audio understanding and Qwen 3.0 for advanced text comprehension. A lightweight speech adapter is introduced to bridge the modality gap between speech and text representations, facilitating effective utilization of pretrained multimodal knowledge. To ensure both translation accuracy and real-time responsiveness, we adopt a streaming speech decoder in the TTS stage, which generates the target speech in an autoregressive manner. Extensive experiments conducted on the CVSS benchmark demonstrate that S2ST-Omni consistently surpasses several state-of-the-art S2ST baselines in translation quality, highlighting its effectiveness and superiority.
CreatiPoster: Towards Editable and Controllable Multi-Layer Graphic Design Generation
Jun 12, 2025Graphic design plays a crucial role in both commercial and personal contexts, yet creating high-quality, editable, and aesthetically pleasing graphic compositions remains a time-consuming and skill-intensive task, especially for beginners. Current AI tools automate parts of the workflow, but struggle to accurately incorporate user-supplied assets, maintain editability, and achieve professional visual appeal. Commercial systems, like Canva Magic Design, rely on vast template libraries, which are impractical for replicate. In this paper, we introduce CreatiPoster, a framework that generates editable, multi-layer compositions from optional natural-language instructions or assets. A protocol model, an RGBA large multimodal model, first produces a JSON specification detailing every layer (text or asset) with precise layout, hierarchy, content and style, plus a concise background prompt. A conditional background model then synthesizes a coherent background conditioned on this rendered foreground layers. We construct a benchmark with automated metrics for graphic-design generation and show that CreatiPoster surpasses leading open-source approaches and proprietary commercial systems. To catalyze further research, we release a copyright-free corpus of 100,000 multi-layer designs. CreatiPoster supports diverse applications such as canvas editing, text overlay, responsive resizing, multilingual adaptation, and animated posters, advancing the democratization of AI-assisted graphic design. Project homepage: https://github.com/graphic-design-ai/creatiposter
ClapFM-EVC: High-Fidelity and Flexible Emotional Voice Conversion with Dual Control from Natural Language and Speech
May 20, 2025



Despite great advances, achieving high-fidelity emotional voice conversion (EVC) with flexible and interpretable control remains challenging. This paper introduces ClapFM-EVC, a novel EVC framework capable of generating high-quality converted speech driven by natural language prompts or reference speech with adjustable emotion intensity. We first propose EVC-CLAP, an emotional contrastive language-audio pre-training model, guided by natural language prompts and categorical labels, to extract and align fine-grained emotional elements across speech and text modalities. Then, a FuEncoder with an adaptive intensity gate is presented to seamless fuse emotional features with Phonetic PosteriorGrams from a pre-trained ASR model. To further improve emotion expressiveness and speech naturalness, we propose a flow matching model conditioned on these captured features to reconstruct Mel-spectrogram of source speech. Subjective and objective evaluations validate the effectiveness of ClapFM-EVC.
The Tower of Babel Revisited: Multilingual Jailbreak Prompts on Closed-Source Large Language Models
May 18, 2025



Large language models (LLMs) have seen widespread applications across various domains, yet remain vulnerable to adversarial prompt injections. While most existing research on jailbreak attacks and hallucination phenomena has focused primarily on open-source models, we investigate the frontier of closed-source LLMs under multilingual attack scenarios. We present a first-of-its-kind integrated adversarial framework that leverages diverse attack techniques to systematically evaluate frontier proprietary solutions, including GPT-4o, DeepSeek-R1, Gemini-1.5-Pro, and Qwen-Max. Our evaluation spans six categories of security contents in both English and Chinese, generating 38,400 responses across 32 types of jailbreak attacks. Attack success rate (ASR) is utilized as the quantitative metric to assess performance from three dimensions: prompt design, model architecture, and language environment. Our findings suggest that Qwen-Max is the most vulnerable, while GPT-4o shows the strongest defense. Notably, prompts in Chinese consistently yield higher ASRs than their English counterparts, and our novel Two-Sides attack technique proves to be the most effective across all models. This work highlights a dire need for language-aware alignment and robust cross-lingual defenses in LLMs, and we hope it will inspire researchers, developers, and policymakers toward more robust and inclusive AI systems.
Risk Assessment Framework for Code LLMs via Leveraging Internal States
Apr 20, 2025The pre-training paradigm plays a key role in the success of Large Language Models (LLMs), which have been recognized as one of the most significant advancements of AI recently. Building on these breakthroughs, code LLMs with advanced coding capabilities bring huge impacts on software engineering, showing the tendency to become an essential part of developers' daily routines. However, the current code LLMs still face serious challenges related to trustworthiness, as they can generate incorrect, insecure, or unreliable code. Recent exploratory studies find that it can be promising to detect such risky outputs by analyzing LLMs' internal states, akin to how the human brain unconsciously recognizes its own mistakes. Yet, most of these approaches are limited to narrow sub-domains of LLM operations and fall short of achieving industry-level scalability and practicability. To address these challenges, in this paper, we propose PtTrust, a two-stage risk assessment framework for code LLM based on internal state pre-training, designed to integrate seamlessly with the existing infrastructure of software companies. The core idea is that the risk assessment framework could also undergo a pre-training process similar to LLMs. Specifically, PtTrust first performs unsupervised pre-training on large-scale unlabeled source code to learn general representations of LLM states. Then, it uses a small, labeled dataset to train a risk predictor. We demonstrate the effectiveness of PtTrust through fine-grained, code line-level risk assessment and demonstrate that it generalizes across tasks and different programming languages. Further experiments also reveal that PtTrust provides highly intuitive and interpretable features, fostering greater user trust. We believe PtTrust makes a promising step toward scalable and trustworthy assurance for code LLMs.
* To appear in the 33rd ACM International Conference on the Foundations of Software Engineering (FSE Companion'25 Industry Track), June 23-28, 2025, Trondheim, Norway. This work was supported by Fujitsu Limited
PathOrchestra: A Comprehensive Foundation Model for Computational Pathology with Over 100 Diverse Clinical-Grade Tasks
Mar 31, 2025The complexity and variability inherent in high-resolution pathological images present significant challenges in computational pathology. While pathology foundation models leveraging AI have catalyzed transformative advancements, their development demands large-scale datasets, considerable storage capacity, and substantial computational resources. Furthermore, ensuring their clinical applicability and generalizability requires rigorous validation across a broad spectrum of clinical tasks. Here, we present PathOrchestra, a versatile pathology foundation model trained via self-supervised learning on a dataset comprising 300K pathological slides from 20 tissue and organ types across multiple centers. The model was rigorously evaluated on 112 clinical tasks using a combination of 61 private and 51 public datasets. These tasks encompass digital slide preprocessing, pan-cancer classification, lesion identification, multi-cancer subtype classification, biomarker assessment, gene expression prediction, and the generation of structured reports. PathOrchestra demonstrated exceptional performance across 27,755 WSIs and 9,415,729 ROIs, achieving over 0.950 accuracy in 47 tasks, including pan-cancer classification across various organs, lymphoma subtype diagnosis, and bladder cancer screening. Notably, it is the first model to generate structured reports for high-incidence colorectal cancer and diagnostically complex lymphoma-areas that are infrequently addressed by foundational models but hold immense clinical potential. Overall, PathOrchestra exemplifies the feasibility and efficacy of a large-scale, self-supervised pathology foundation model, validated across a broad range of clinical-grade tasks. Its high accuracy and reduced reliance on extensive data annotation underline its potential for clinical integration, offering a pathway toward more efficient and high-quality medical services.
Pre-trained Models Succeed in Medical Imaging with Representation Similarity Degradation
Mar 11, 2025



This paper investigates the critical problem of representation similarity evolution during cross-domain transfer learning, with particular focus on understanding why pre-trained models maintain effectiveness when adapted to medical imaging tasks despite significant domain gaps. The study establishes a rigorous problem definition centered on quantifying and analyzing representation similarity trajectories throughout the fine-tuning process, while carefully delineating the scope to encompass both medical image analysis and broader cross-domain adaptation scenarios. Our empirical findings reveal three critical discoveries: the potential existence of high-performance models that preserve both task accuracy and representation similarity to their pre-trained origins; a robust linear correlation between layer-wise similarity metrics and representation quality indicators; and distinct adaptation patterns that differentiate supervised versus self-supervised pre-training paradigms. The proposed similarity space framework not only provides mechanistic insights into knowledge transfer dynamics but also raises fundamental questions about optimal utilization of pre-trained models. These results advance our understanding of neural network adaptation processes while offering practical implications for transfer learning strategies that extend beyond medical imaging applications. The code will be available once accepted.
Keeping Representation Similarity in Finetuning for Medical Image Analysis
Mar 10, 2025



Foundation models pretrained on large-scale natural images have been widely used to adapt to medical image analysis through finetuning. This is largely attributed to pretrained representations capturing universal, robust, and generalizable features, which can be reutilized by downstream tasks. However, these representations are later found to gradually vanish during finetuning, accompanied by a degradation of foundation model's original abilities, e.g., generalizability. In this paper, we argue that pretrained representations can be well preserved while still effectively adapting to downstream tasks. We study this by proposing a new finetuning method RepSim, which minimizes the distance between pretrained and finetuned representations via constraining learnable orthogonal manifold based on similarity invariance. Compared to standard finetuning methods, e.g., full finetuning, our method improves representation similarity by over 30% while maintaining competitive accuracy, and reduces sharpness by 42% across five medical image classification datasets. The code will be released.
From Dataset to Real-world: General 3D Object Detection via Generalized Cross-domain Few-shot Learning
Mar 08, 2025LiDAR-based 3D object detection datasets have been pivotal for autonomous driving, yet they cover a limited range of objects, restricting the model's generalization across diverse deployment environments. To address this, we introduce the first generalized cross-domain few-shot (GCFS) task in 3D object detection, which focuses on adapting a source-pretrained model for high performance on both common and novel classes in a target domain with few-shot samples. Our solution integrates multi-modal fusion and contrastive-enhanced prototype learning within one framework, holistically overcoming challenges related to data scarcity and domain adaptation in the GCFS setting. The multi-modal fusion module utilizes 2D vision-language models to extract rich, open-set semantic knowledge. To address biases in point distributions across varying structural complexities, we particularly introduce a physically-aware box searching strategy that leverages laser imaging principles to generate high-quality 3D box proposals from 2D insights, enhancing object recall. To effectively capture domain-specific representations for each class from limited target data, we further propose a contrastive-enhanced prototype learning, which strengthens the model's adaptability. We evaluate our approach with three GCFS benchmark settings, and extensive experiments demonstrate the effectiveness of our solution for GCFS tasks. The code will be publicly available.
Aligning Instruction Tuning with Pre-training
Jan 16, 2025



Instruction tuning enhances large language models (LLMs) to follow human instructions across diverse tasks, relying on high-quality datasets to guide behavior. However, these datasets, whether manually curated or synthetically generated, are often narrowly focused and misaligned with the broad distributions captured during pre-training, limiting LLM generalization and effective use of pre-trained knowledge. We propose *Aligning Instruction Tuning with Pre-training* (AITP), a method that bridges this gap by identifying coverage shortfalls in instruction-tuning datasets and rewriting underrepresented pre-training data into high-quality instruction-response pairs. This approach enriches dataset diversity while preserving task-specific objectives. Evaluations on three fully open LLMs across eight benchmarks demonstrate consistent performance improvements with AITP. Ablations highlight the benefits of adaptive data selection, controlled rewriting, and balanced integration, emphasizing the importance of aligning instruction tuning with pre-training distributions to unlock the full potential of LLMs.