 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS2ST-Omni: An Efficient and Scalable Multilingual Speech-to-Speech Translation Framework via Seamlessly Speech-Text Alignment and Streaming Speech Decoder
Paper and Code
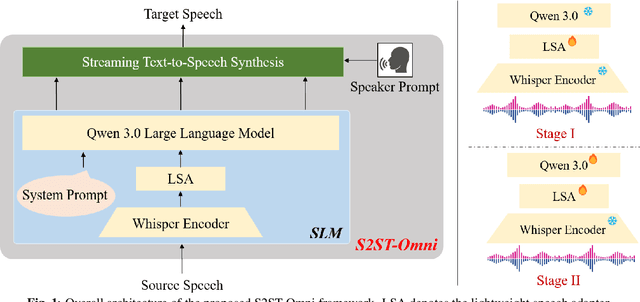
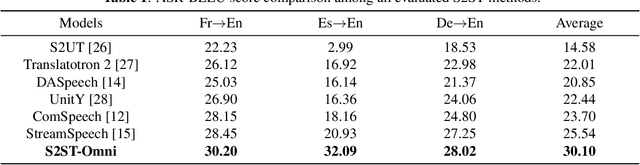
Multilingual speech-to-speech translation (S2ST) aims to directly convert spoken utterances from multiple source languages into fluent and intelligible speech in a target language. Despite recent progress, several critical challenges persist: 1) achieving high-quality and low-latency S2ST remains a significant obstacle; 2) most existing S2ST methods rely heavily on large-scale parallel speech corpora, which are difficult and resource-intensive to obtain. To tackle these challenges, we introduce S2ST-Omni, a novel, efficient, and scalable framework tailored for multilingual speech-to-speech translation. To enable high-quality S2TT while mitigating reliance on large-scale parallel speech corpora, we leverage powerful pretrained models: Whisper for robust audio understanding and Qwen 3.0 for advanced text comprehension. A lightweight speech adapter is introduced to bridge the modality gap between speech and text representations, facilitating effective utilization of pretrained multimodal knowledge. To ensure both translation accuracy and real-time responsiveness, we adopt a streaming speech decoder in the TTS stage, which generates the target speech in an autoregressive manner. Extensive experiments conducted on the CVSS benchmark demonstrate that S2ST-Omni consistently surpasses several state-of-the-art S2ST baselines in translation quality, highlighting its effectiveness and superiority.