 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrecise Verification of Transformers through ReLU-Catalyzed Abstraction Refinement
May 14, 2026Formal verification of transformers has become increasingly important due to their widespread deployment in safety-critical applications. Compared to classic neural networks, the inferences of transformers involve highly complex computations, such as dot products in self-attention layers, rendering their verification extremely difficult. Existing approaches explored over-approximation methods by constructing convex constraints to bound the output ranges of transformers, which can achieve high efficiency. However, they may sacrifice verification precision, and consequently introduce significant approximation error that leads to frequent occurrences of false alarms. In this paper, we propose a transformer verification approach that can achieve improved precision. At the core of our approach is a novel usage of ReLU, by which we represent a precise but non-linear bound for dot products such that we can further exploit the rich body of literature for convex relaxation of ReLU to derive precise bounds. We extend two classic approaches to the context of transformers, a rule-based one and an optimization-based one, resulting in two new frameworks for efficient and precise verification. We evaluate our approaches on different model architectures and robustness properties derived from two datasets about sentiment analysis, and compare with the state-of-the-art baseline approach. Compared to the baseline, our approach can achieve significant precision improvement for most of the verification tasks with acceptable compromise of efficiency, which demonstrates the effectiveness of our approach.
QuanForge: A Mutation Testing Framework for Quantum Neural Networks
Apr 22, 2026With the growing synergy between deep learning and quantum computing, Quantum Neural Networks (QNNs) have emerged as a promising paradigm by leveraging quantum parallelism and entanglement. However, testing QNNs remains underexplored due to their complex quantum dynamics and limited interpretability. Developing a mutation testing technique for QNNs is promising while requires addressing stochastic factors, including the inherent randomness of mutation operators and quantum measurements. To tackle these challenges, we propose QuanForge, a mutation testing framework specifically designed for QNNs. We first introduce statistical mutation killing to provide a more reliable criterion. QuanForge incorporates nine post-training mutation operators at both gate and parameter levels, capable of simulating various potential errors in quantum circuits. Finally, a mutant generation algorithm is formalized that systematically produces effective mutants, thereby enabling a robust and reliable mutation analysis. Through extensive experiments on benchmark datasets and QNN architectures, we show that QuanForge can effectively distinguish different test suites and localize vulnerable circuit regions, providing insights for data enhancement and structural assessment of QNNs. We also analyze the generation capabilities of different operators and evaluate performance under simulated noisy conditions to assess the practical feasibility of QuanForge for future quantum devices.
A Comprehensive Study of Deep Learning Model Fixing Approaches
Dec 26, 2025Deep Learning (DL) has been widely adopted in diverse industrial domains, including autonomous driving, intelligent healthcare, and aided programming. Like traditional software, DL systems are also prone to faults, whose malfunctioning may expose users to significant risks. Consequently, numerous approaches have been proposed to address these issues. In this paper, we conduct a large-scale empirical study on 16 state-of-the-art DL model fixing approaches, spanning model-level, layer-level, and neuron-level categories, to comprehensively evaluate their performance. We assess not only their fixing effectiveness (their primary purpose) but also their impact on other critical properties, such as robustness, fairness, and backward compatibility. To ensure comprehensive and fair evaluation, we employ a diverse set of datasets, model architectures, and application domains within a uniform experimental setup for experimentation. We summarize several key findings with implications for both industry and academia. For example, model-level approaches demonstrate superior fixing effectiveness compared to others. No single approach can achieve the best fixing performance while improving accuracy and maintaining all other properties. Thus, academia should prioritize research on mitigating these side effects. These insights highlight promising directions for future exploration in this field.
Efficient Neural Network Verification via Order Leading Exploration of Branch-and-Bound Trees
Jul 23, 2025The vulnerability of neural networks to adversarial perturbations has necessitated formal verification techniques that can rigorously certify the quality of neural networks. As the state-of-the-art, branch and bound (BaB) is a "divide-and-conquer" strategy that applies off-the-shelf verifiers to sub-problems for which they perform better. While BaB can identify the sub-problems that are necessary to be split, it explores the space of these sub-problems in a naive "first-come-first-serve" manner, thereby suffering from an issue of inefficiency to reach a verification conclusion. To bridge this gap, we introduce an order over different sub-problems produced by BaB, concerning with their different likelihoods of containing counterexamples. Based on this order, we propose a novel verification framework Oliva that explores the sub-problem space by prioritizing those sub-problems that are more likely to find counterexamples, in order to efficiently reach the conclusion of the verification. Even if no counterexample can be found in any sub-problem, it only changes the order of visiting different sub-problem and so will not lead to a performance degradation. Specifically, Oliva has two variants, including $Oliva^{GR}$, a greedy strategy that always prioritizes the sub-problems that are more likely to find counterexamples, and $Oliva^{SA}$, a balanced strategy inspired by simulated annealing that gradually shifts from exploration to exploitation to locate the globally optimal sub-problems. We experimentally evaluate the performance of Oliva on 690 verification problems spanning over 5 models with datasets MNIST and CIFAR10. Compared to the state-of-the-art approaches, we demonstrate the speedup of Oliva for up to 25X in MNIST, and up to 80X in CIFAR10.
AR2: Attention-Guided Repair for the Robustness of CNNs Against Common Corruptions
Jul 08, 2025Deep neural networks suffer from significant performance degradation when exposed to common corruptions such as noise, blur, weather, and digital distortions, limiting their reliability in real-world applications. In this paper, we propose AR2 (Attention-Guided Repair for Robustness), a simple yet effective method to enhance the corruption robustness of pretrained CNNs. AR2 operates by explicitly aligning the class activation maps (CAMs) between clean and corrupted images, encouraging the model to maintain consistent attention even under input perturbations. Our approach follows an iterative repair strategy that alternates between CAM-guided refinement and standard fine-tuning, without requiring architectural changes. Extensive experiments show that AR2 consistently outperforms existing state-of-the-art methods in restoring robustness on standard corruption benchmarks (CIFAR-10-C, CIFAR-100-C and ImageNet-C), achieving a favorable balance between accuracy on clean data and corruption robustness. These results demonstrate that AR2 provides a robust and scalable solution for enhancing model reliability in real-world environments with diverse corruptions.
S2ST-Omni: An Efficient and Scalable Multilingual Speech-to-Speech Translation Framework via Seamlessly Speech-Text Alignment and Streaming Speech Decoder
Jun 16, 2025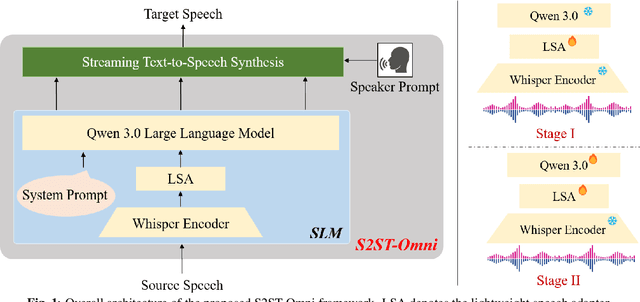
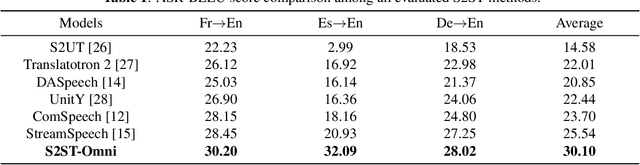
Multilingual speech-to-speech translation (S2ST) aims to directly convert spoken utterances from multiple source languages into fluent and intelligible speech in a target language. Despite recent progress, several critical challenges persist: 1) achieving high-quality and low-latency S2ST remains a significant obstacle; 2) most existing S2ST methods rely heavily on large-scale parallel speech corpora, which are difficult and resource-intensive to obtain. To tackle these challenges, we introduce S2ST-Omni, a novel, efficient, and scalable framework tailored for multilingual speech-to-speech translation. To enable high-quality S2TT while mitigating reliance on large-scale parallel speech corpora, we leverage powerful pretrained models: Whisper for robust audio understanding and Qwen 3.0 for advanced text comprehension. A lightweight speech adapter is introduced to bridge the modality gap between speech and text representations, facilitating effective utilization of pretrained multimodal knowledge. To ensure both translation accuracy and real-time responsiveness, we adopt a streaming speech decoder in the TTS stage, which generates the target speech in an autoregressive manner. Extensive experiments conducted on the CVSS benchmark demonstrate that S2ST-Omni consistently surpasses several state-of-the-art S2ST baselines in translation quality, highlighting its effectiveness and superiority.
ClapFM-EVC: High-Fidelity and Flexible Emotional Voice Conversion with Dual Control from Natural Language and Speech
May 20, 2025



Despite great advances, achieving high-fidelity emotional voice conversion (EVC) with flexible and interpretable control remains challenging. This paper introduces ClapFM-EVC, a novel EVC framework capable of generating high-quality converted speech driven by natural language prompts or reference speech with adjustable emotion intensity. We first propose EVC-CLAP, an emotional contrastive language-audio pre-training model, guided by natural language prompts and categorical labels, to extract and align fine-grained emotional elements across speech and text modalities. Then, a FuEncoder with an adaptive intensity gate is presented to seamless fuse emotional features with Phonetic PosteriorGrams from a pre-trained ASR model. To further improve emotion expressiveness and speech naturalness, we propose a flow matching model conditioned on these captured features to reconstruct Mel-spectrogram of source speech. Subjective and objective evaluations validate the effectiveness of ClapFM-EVC.
Adaptive Branch-and-Bound Tree Exploration for Neural Network Verification
May 02, 2025Formal verification is a rigorous approach that can provably ensure the quality of neural networks, and to date, Branch and Bound (BaB) is the state-of-the-art that performs verification by splitting the problem as needed and applying off-the-shelf verifiers to sub-problems for improved performance. However, existing BaB may not be efficient, due to its naive way of exploring the space of sub-problems that ignores the \emph{importance} of different sub-problems. To bridge this gap, we first introduce a notion of ``importance'' that reflects how likely a counterexample can be found with a sub-problem, and then we devise a novel verification approach, called ABONN, that explores the sub-problem space of BaB adaptively, in a Monte-Carlo tree search (MCTS) style. The exploration is guided by the ``importance'' of different sub-problems, so it favors the sub-problems that are more likely to find counterexamples. As soon as it finds a counterexample, it can immediately terminate; even though it cannot find, after visiting all the sub-problems, it can still manage to verify the problem. We evaluate ABONN with 552 verification problems from commonly-used datasets and neural network models, and compare it with the state-of-the-art verifiers as baseline approaches. Experimental evaluation shows that ABONN demonstrates speedups of up to $15.2\times$ on MNIST and $24.7\times$ on CIFAR-10. We further study the influences of hyperparameters to the performance of ABONN, and the effectiveness of our adaptive tree exploration.
CTEFM-VC: Zero-Shot Voice Conversion Based on Content-Aware Timbre Ensemble Modeling and Flow Matching
Nov 04, 2024



Zero-shot voice conversion (VC) aims to transform the timbre of a source speaker into any previously unseen target speaker, while preserving the original linguistic content. Despite notable progress, attaining a degree of speaker similarity and naturalness on par with ground truth recordings continues to pose great challenge. In this paper, we propose CTEFM-VC, a zero-shot VC framework that leverages Content-aware Timbre Ensemble modeling and Flow Matching. Specifically, CTEFM-VC disentangles utterances into linguistic content and timbre representations, subsequently utilizing a conditional flow matching model and a vocoder to reconstruct the mel-spectrogram and waveform. To enhance its timbre modeling capability and the naturalness of generated speech, we propose a context-aware timbre ensemble modeling approach that adaptively integrates diverse speaker verification embeddings and enables the joint utilization of linguistic and timbre features through a cross-attention module. Experiments show that our CTEFM-VC system surpasses state-of-the-art VC methods in both speaker similarity and naturalness by at least 18.5% and 7.0%.
A Coverage-Guided Testing Framework for Quantum Neural Networks
Nov 03, 2024Quantum Neural Networks (QNNs) combine quantum computing and neural networks, leveraging quantum properties such as superposition and entanglement to improve machine learning models. These quantum characteristics enable QNNs to potentially outperform classical neural networks in tasks such as quantum chemistry simulations, optimization problems, and quantum-enhanced machine learning. However, they also introduce significant challenges in verifying the correctness and reliability of QNNs. To address this, we propose QCov, a set of test coverage criteria specifically designed for QNNs to systematically evaluate QNN state exploration during testing, focusing on superposition and entanglement. These criteria help detect quantum-specific defects and anomalies. Extensive experiments on benchmark datasets and QNN models validate QCov's effectiveness in identifying quantum-specific defects and guiding fuzz testing, thereby improving QNN robustness and reliability.