 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRisk Assessment Framework for Code LLMs via Leveraging Internal States
Apr 20, 2025The pre-training paradigm plays a key role in the success of Large Language Models (LLMs), which have been recognized as one of the most significant advancements of AI recently. Building on these breakthroughs, code LLMs with advanced coding capabilities bring huge impacts on software engineering, showing the tendency to become an essential part of developers' daily routines. However, the current code LLMs still face serious challenges related to trustworthiness, as they can generate incorrect, insecure, or unreliable code. Recent exploratory studies find that it can be promising to detect such risky outputs by analyzing LLMs' internal states, akin to how the human brain unconsciously recognizes its own mistakes. Yet, most of these approaches are limited to narrow sub-domains of LLM operations and fall short of achieving industry-level scalability and practicability. To address these challenges, in this paper, we propose PtTrust, a two-stage risk assessment framework for code LLM based on internal state pre-training, designed to integrate seamlessly with the existing infrastructure of software companies. The core idea is that the risk assessment framework could also undergo a pre-training process similar to LLMs. Specifically, PtTrust first performs unsupervised pre-training on large-scale unlabeled source code to learn general representations of LLM states. Then, it uses a small, labeled dataset to train a risk predictor. We demonstrate the effectiveness of PtTrust through fine-grained, code line-level risk assessment and demonstrate that it generalizes across tasks and different programming languages. Further experiments also reveal that PtTrust provides highly intuitive and interpretable features, fostering greater user trust. We believe PtTrust makes a promising step toward scalable and trustworthy assurance for code LLMs.
* To appear in the 33rd ACM International Conference on the Foundations of Software Engineering (FSE Companion'25 Industry Track), June 23-28, 2025, Trondheim, Norway. This work was supported by Fujitsu Limited
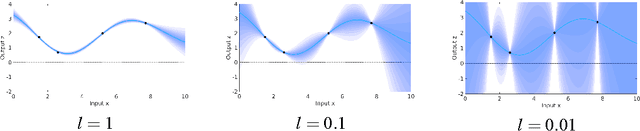
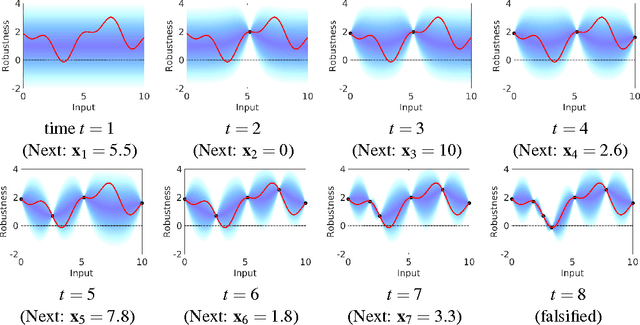
Falsification of Cyber-Physical Systems Using Deep Reinforcement Learning
May 01, 2018

With the rapid development of software and distributed computing, Cyber-Physical Systems (CPS) are widely adopted in many application areas, e.g., smart grid, autonomous automobile. It is difficult to detect defects in CPS models due to the complexities involved in the software and physical systems. To find defects in CPS models efficiently, robustness guided falsification of CPS is introduced. Existing methods use several optimization techniques to generate counterexamples, which falsify the given properties of a CPS. However those methods may require a large number of simulation runs to find the counterexample and is far from practical. In this work, we explore state-of-the-art Deep Reinforcement Learning (DRL) techniques to reduce the number of simulation runs required to find such counterexamples. We report our method and the preliminary evaluation results.
* 9 pages, 1 figure, to be presented at FM2018
Causality-Aided Falsification
Sep 08, 2017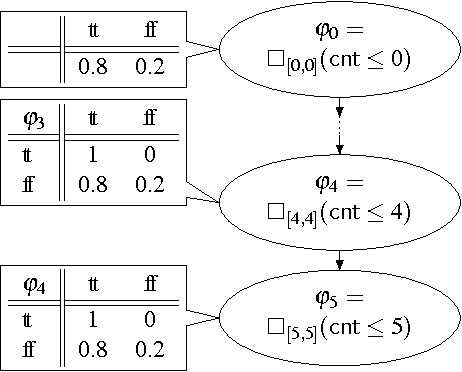
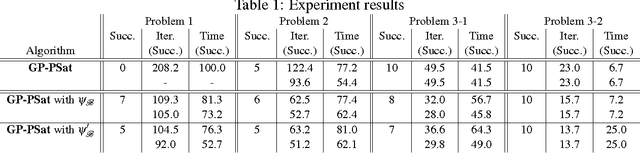
Falsification is drawing attention in quality assurance of heterogeneous systems whose complexities are beyond most verification techniques' scalability. In this paper we introduce the idea of causality aid in falsification: by providing a falsification solver -- that relies on stochastic optimization of a certain cost function -- with suitable causal information expressed by a Bayesian network, search for a falsifying input value can be efficient. Our experiment results show the idea's viability.
* In Proceedings FVAV 2017, arXiv:1709.02126