 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Action Reparameterization for Efficient Agent Inference
May 19, 2026Large language model (LLM) agents often rely on long sequences of low-level textual actions, resulting in large effective decision horizons and high inference cost. While prior work has focused on improving inference efficiency through system-level optimizations or prompt engineering, we argue that a key bottleneck lies in the representation of the action space itself. We propose Latent Action Reparameterization (LAR), a framework that learns a compact latent action space in which each latent action corresponds to a multi-step semantic behavior. By reparameterizing agent actions into latent units, LAR enables decision making over a shorter effective horizon while preserving the expressiveness of the original action space. Unlike hand-crafted macros or hierarchical controllers, latent actions are learned from agent trajectories and integrated directly into the model, allowing both planning and execution to operate over abstract action representations. Across a range of LLM-based agent benchmarks, LAR significantly reduces the effective action horizon and improves inference efficiency under fixed compute budgets. As a consequence, our approach achieves substantial reductions in action tokens and corresponding wall-clock inference time, while maintaining or improving task success rates. These results suggest that action representation learning is a critical and underexplored factor in scaling efficient LLM agent inference, complementary to advances in model architecture and hardware.
ScioMind: Cognitively Grounded Multi-Agent Social Simulation with Anchoring-Based Belief Dynamics and Dynamic Profiles
May 13, 2026Large language model (LLM)-based multi-agent simulation offers a powerful testbed for studying social opinion dynamics. Yet current approaches often adopt two contrasting methods: either relying on fixed update rules with limited cognitive grounding or delegating belief change largely to unconstrained LLM interaction. We introduce ScioMind, a cognitively grounded simulation framework that bridges these paradigms by combining structured opinion dynamics with LLM-based agent reasoning. ScioMind integrates three key components: 1) a memory-anchored belief update rule that modulates susceptibility to influence via personality-conditioned anchoring strength; 2) a hierarchical memory architecture that supports persistent, experience-driven belief formation; and 3) dynamic agent profiles derived from a corpus-grounded retrieval pipeline, enabling heterogeneous personalities, rationales, and evolving internal states. We evaluate ScioMind on multiple case studies in a real-world policy debate scenario. Across metrics including polarisation, diversity, extremization, and trajectory stability, the proposed components consistently yield improvements in behavioural realism. In particular, dynamic profiles increase opinion diversity, memory and reflection reduce unstable oscillation, and anchoring induces persistent belief trajectories that better align with patterns reported in political psychology. These results suggest that our cognitively grounded design provides a novel solution to LLM-based social simulation that improves both stable and behavioural realism
Are LLMs Reliable Code Reviewers? Systematic Overcorrection in Requirement Conformance Judgement
Feb 28, 2026Large language models (LLMs) have become essential tools in software development, widely used for requirements engineering, code generation and review tasks. Software engineers often rely on LLMs to verify if code implementation satisfy task requirements, thereby ensuring code robustness and accuracy. However, it remains unclear whether LLMs can reliably determine code against the given task descriptions, which is usually in a form of natural language specifications. In this paper, we uncover a systematic failure of LLMs in matching code to natural language requirements. Specifically, with widely adopted benchmarks and unified prompts design, we demonstrate that LLMs frequently misclassify correct code implementation as non-compliant or defective. Surprisingly, we find that more detailed prompt design, particularly with those requiring explanations and proposed corrections, leads to higher misjudgment rates, highlighting critical reliability issues for LLM-based code assistants. We further analyze the mechanisms driving these failures and evaluate the reliability of rationale-required judgments. Building on these findings, we propose a Fix-guided Verification Filter that treats the model proposed fix as executable counterfactual evidence, and validates the original and revised implementations using benchmark tests and spec-constrained augmented tests. Our results expose previously under-explored limitations in LLM-based code review capabilities, and provide practical guidance for integrating LLM-based reviewers with safeguards in automated review and development pipelines.
Learning to Fuse and Reconstruct Multi-View Graphs for Diabetic Retinopathy Grading
Feb 25, 2026Diabetic retinopathy (DR) is one of the leading causes of vision loss worldwide, making early and accurate DR grading critical for timely intervention. Recent clinical practices leverage multi-view fundus images for DR detection with a wide coverage of the field of view (FOV), motivating deep learning methods to explore the potential of multi-view learning for DR grading. However, existing methods often overlook the inter-view correlations when fusing multi-view fundus images, failing to fully exploit the inherent consistency across views originating from the same patient. In this work, we present MVGFDR, an end-to-end Multi-View Graph Fusion framework for DR grading. Different from existing methods that directly fuse visual features from multiple views, MVGFDR is equipped with a novel Multi-View Graph Fusion (MVGF) module to explicitly disentangle the shared and view-specific visual features. Specifically, MVGF comprises three key components: (1) Multi-view Graph Initialization, which constructs visual graphs via residual-guided connections and employs Discrete Cosine Transform (DCT) coefficients as frequency-domain anchors; (2) Multi-view Graph Fusion, which integrates selective nodes across multi-view graphs based on frequency-domain relevance to capture complementary view-specific information; and (3) Masked Cross-view Reconstruction, which leverages masked reconstruction of shared information across views to facilitate view-invariant representation learning. Extensive experimental results on MFIDDR, by far the largest multi-view fundus image dataset, demonstrate the superiority of our proposed approach over existing state-of-the-art approaches in diabetic retinopathy grading.
Trust in One Round: Confidence Estimation for Large Language Models via Structural Signals
Feb 01, 2026Large language models (LLMs) are increasingly deployed in domains where errors carry high social, scientific, or safety costs. Yet standard confidence estimators, such as token likelihood, semantic similarity and multi-sample consistency, remain brittle under distribution shift, domain-specialised text, and compute limits. In this work, we present Structural Confidence, a single-pass, model-agnostic framework that enhances output correctness prediction based on multi-scale structural signals derived from a model's final-layer hidden-state trajectory. By combining spectral, local-variation, and global shape descriptors, our method captures internal stability patterns that are missed by probabilities and sentence embeddings. We conduct extensive, cross-domain evaluation across four heterogeneous benchmarks-FEVER (fact verification), SciFact (scientific claims), WikiBio-hallucination (biographical consistency), and TruthfulQA (truthfulness-oriented QA). Our Structural Confidence framework demonstrates strong performance compared with established baselines in terms of AUROC and AUPR. More importantly, unlike sampling-based consistency methods which require multiple stochastic generations and an auxiliary model, our approach uses a single deterministic forward pass, offering a practical basis for efficient, robust post-hoc confidence estimation in socially impactful, resource-constrained LLM applications.
Feature-Selective Representation Misdirection for Machine Unlearning
Dec 18, 2025



As large language models (LLMs) are increasingly adopted in safety-critical and regulated sectors, the retention of sensitive or prohibited knowledge introduces escalating risks, ranging from privacy leakage to regulatory non-compliance to to potential misuse, and so on. Recent studies suggest that machine unlearning can help ensure deployed models comply with evolving legal, safety, and governance requirements. However, current unlearning techniques assume clean separation between forget and retain datasets, which is challenging in operational settings characterized by highly entangled distributions. In such scenarios, perturbation-based methods often degrade general model utility or fail to ensure safety. To address this, we propose Selective Representation Misdirection for Unlearning (SRMU), a novel principled activation-editing framework that enforces feature-aware and directionally controlled perturbations. Unlike indiscriminate model weights perturbations, SRMU employs a structured misdirection vector with an activation importance map. The goal is to allow SRMU selectively suppresses harmful representations while preserving the utility on benign ones. Experiments are conducted on the widely used WMDP benchmark across low- and high-entanglement configurations. Empirical results reveal that SRMU delivers state-of-the-art unlearning performance with minimal utility losses, and remains effective under 20-30\% overlap where existing baselines collapse. SRMU provides a robust foundation for safety-driven model governance, privacy compliance, and controlled knowledge removal in the emerging LLM-based applications. We release the replication package at https://figshare.com/s/d5931192a8824de26aff.
GuardFed: A Trustworthy Federated Learning Framework Against Dual-Facet Attacks
Nov 12, 2025Federated learning (FL) enables privacy-preserving collaborative model training but remains vulnerable to adversarial behaviors that compromise model utility or fairness across sensitive groups. While extensive studies have examined attacks targeting either objective, strategies that simultaneously degrade both utility and fairness remain largely unexplored. To bridge this gap, we introduce the Dual-Facet Attack (DFA), a novel threat model that concurrently undermines predictive accuracy and group fairness. Two variants, Synchronous DFA (S-DFA) and Split DFA (Sp-DFA), are further proposed to capture distinct real-world collusion scenarios. Experimental results show that existing robust FL defenses, including hybrid aggregation schemes, fail to resist DFAs effectively. To counter these threats, we propose GuardFed, a self-adaptive defense framework that maintains a fairness-aware reference model using a small amount of clean server data augmented with synthetic samples. In each training round, GuardFed computes a dual-perspective trust score for every client by jointly evaluating its utility deviation and fairness degradation, thereby enabling selective aggregation of trustworthy updates. Extensive experiments on real-world datasets demonstrate that GuardFed consistently preserves both accuracy and fairness under diverse non-IID and adversarial conditions, achieving state-of-the-art performance compared with existing robust FL methods.
Foe for Fraud: Transferable Adversarial Attacks in Credit Card Fraud Detection
Aug 20, 2025Credit card fraud detection (CCFD) is a critical application of Machine Learning (ML) in the financial sector, where accurately identifying fraudulent transactions is essential for mitigating financial losses. ML models have demonstrated their effectiveness in fraud detection task, in particular with the tabular dataset. While adversarial attacks have been extensively studied in computer vision and deep learning, their impacts on the ML models, particularly those trained on CCFD tabular datasets, remains largely unexplored. These latent vulnerabilities pose significant threats to the security and stability of the financial industry, especially in high-value transactions where losses could be substantial. To address this gap, in this paper, we present a holistic framework that investigate the robustness of CCFD ML model against adversarial perturbations under different circumstances. Specifically, the gradient-based attack methods are incorporated into the tabular credit card transaction data in both black- and white-box adversarial attacks settings. Our findings confirm that tabular data is also susceptible to subtle perturbations, highlighting the need for heightened awareness among financial technology practitioners regarding ML model security and trustworthiness. Furthermore, the experiments by transferring adversarial samples from gradient-based attack method to non-gradient-based models also verify our findings. Our results demonstrate that such attacks remain effective, emphasizing the necessity of developing robust defenses for CCFD algorithms.
Uncovering Systematic Failures of LLMs in Verifying Code Against Natural Language Specifications
Aug 17, 2025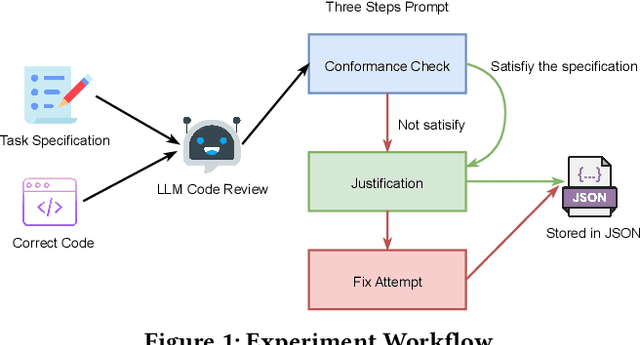
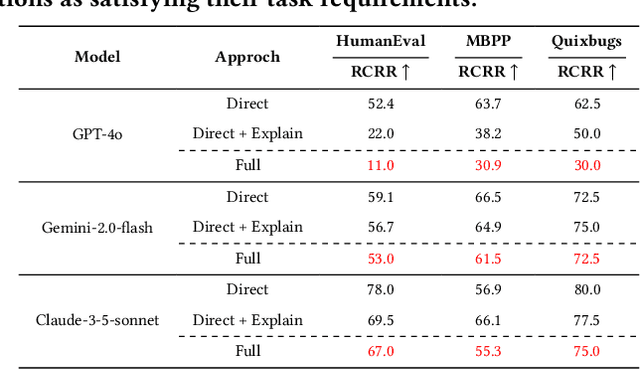
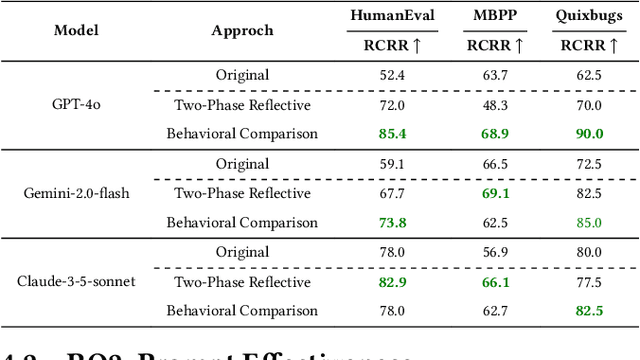
Large language models (LLMs) have become essential tools in software development, widely used for requirements engineering, code generation and review tasks. Software engineers often rely on LLMs to assess whether system code implementation satisfy task requirements, thereby enhancing code robustness and accuracy. However, it remains unclear whether LLMs can reliably determine whether the code complies fully with the given task descriptions, which is usually natural language specifications. In this paper, we uncover a systematic failure of LLMs in evaluating whether code aligns with natural language requirements. Specifically, with widely used benchmarks, we employ unified prompts to judge code correctness. Our results reveal that LLMs frequently misclassify correct code implementations as either ``not satisfying requirements'' or containing potential defects. Surprisingly, more complex prompting, especially when leveraging prompt engineering techniques involving explanations and proposed corrections, leads to higher misjudgment rate, which highlights the critical reliability issues in using LLMs as code review assistants. We further analyze the root causes of these misjudgments, and propose two improved prompting strategies for mitigation. For the first time, our findings reveals unrecognized limitations in LLMs to match code with requirements. We also offer novel insights and practical guidance for effective use of LLMs in automated code review and task-oriented agent scenarios.
FedDifRC: Unlocking the Potential of Text-to-Image Diffusion Models in Heterogeneous Federated Learning
Jul 09, 2025



Federated learning aims at training models collaboratively across participants while protecting privacy. However, one major challenge for this paradigm is the data heterogeneity issue, where biased data preferences across multiple clients, harming the model's convergence and performance. In this paper, we first introduce powerful diffusion models into the federated learning paradigm and show that diffusion representations are effective steers during federated training. To explore the possibility of using diffusion representations in handling data heterogeneity, we propose a novel diffusion-inspired Federated paradigm with Diffusion Representation Collaboration, termed FedDifRC, leveraging meaningful guidance of diffusion models to mitigate data heterogeneity. The key idea is to construct text-driven diffusion contrasting and noise-driven diffusion regularization, aiming to provide abundant class-related semantic information and consistent convergence signals. On the one hand, we exploit the conditional feedback from the diffusion model for different text prompts to build a text-driven contrastive learning strategy. On the other hand, we introduce a noise-driven consistency regularization to align local instances with diffusion denoising representations, constraining the optimization region in the feature space. In addition, FedDifRC can be extended to a self-supervised scheme without relying on any labeled data. We also provide a theoretical analysis for FedDifRC to ensure convergence under non-convex objectives. The experiments on different scenarios validate the effectiveness of FedDifRC and the efficiency of crucial components.