 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEduAgentQG: A Multi-Agent Workflow Framework for Personalized Question Generation
Nov 08, 2025High-quality personalized question banks are crucial for supporting adaptive learning and individualized assessment. Manually designing questions is time-consuming and often fails to meet diverse learning needs, making automated question generation a crucial approach to reduce teachers' workload and improve the scalability of educational resources. However, most existing question generation methods rely on single-agent or rule-based pipelines, which still produce questions with unstable quality, limited diversity, and insufficient alignment with educational goals. To address these challenges, we propose EduAgentQG, a multi-agent collaborative framework for generating high-quality and diverse personalized questions. The framework consists of five specialized agents and operates through an iterative feedback loop: the Planner generates structured design plans and multiple question directions to enhance diversity; the Writer produces candidate questions based on the plan and optimizes their quality and diversity using feedback from the Solver and Educator; the Solver and Educator perform binary scoring across multiple evaluation dimensions and feed the evaluation results back to the Writer; the Checker conducts final verification, including answer correctness and clarity, ensuring alignment with educational goals. Through this multi-agent collaboration and iterative feedback loop, EduAgentQG generates questions that are both high-quality and diverse, while maintaining consistency with educational objectives. Experiments on two mathematics question datasets demonstrate that EduAgentQG outperforms existing single-agent and multi-agent methods in terms of question diversity, goal consistency, and overall quality.
OmniEduBench: A Comprehensive Chinese Benchmark for Evaluating Large Language Models in Education
Oct 30, 2025With the rapid development of large language models (LLMs), various LLM-based works have been widely applied in educational fields. However, most existing LLMs and their benchmarks focus primarily on the knowledge dimension, largely neglecting the evaluation of cultivation capabilities that are essential for real-world educational scenarios. Additionally, current benchmarks are often limited to a single subject or question type, lacking sufficient diversity. This issue is particularly prominent within the Chinese context. To address this gap, we introduce OmniEduBench, a comprehensive Chinese educational benchmark. OmniEduBench consists of 24.602K high-quality question-answer pairs. The data is meticulously divided into two core dimensions: the knowledge dimension and the cultivation dimension, which contain 18.121K and 6.481K entries, respectively. Each dimension is further subdivided into 6 fine-grained categories, covering a total of 61 different subjects (41 in the knowledge and 20 in the cultivation). Furthermore, the dataset features a rich variety of question formats, including 11 common exam question types, providing a solid foundation for comprehensively evaluating LLMs' capabilities in education. Extensive experiments on 11 mainstream open-source and closed-source LLMs reveal a clear performance gap. In the knowledge dimension, only Gemini-2.5 Pro surpassed 60\% accuracy, while in the cultivation dimension, the best-performing model, QWQ, still trailed human intelligence by nearly 30\%. These results highlight the substantial room for improvement and underscore the challenges of applying LLMs in education.
Asynchronous Denoising Diffusion Models for Aligning Text-to-Image Generation
Oct 06, 2025Diffusion models have achieved impressive results in generating high-quality images. Yet, they often struggle to faithfully align the generated images with the input prompts. This limitation arises from synchronous denoising, where all pixels simultaneously evolve from random noise to clear images. As a result, during generation, the prompt-related regions can only reference the unrelated regions at the same noise level, failing to obtain clear context and ultimately impairing text-to-image alignment. To address this issue, we propose asynchronous diffusion models -- a novel framework that allocates distinct timesteps to different pixels and reformulates the pixel-wise denoising process. By dynamically modulating the timestep schedules of individual pixels, prompt-related regions are denoised more gradually than unrelated regions, thereby allowing them to leverage clearer inter-pixel context. Consequently, these prompt-related regions achieve better alignment in the final images. Extensive experiments demonstrate that our asynchronous diffusion models can significantly improve text-to-image alignment across diverse prompts. The code repository for this work is available at https://github.com/hu-zijing/AsynDM.
Universal Legal Article Prediction via Tight Collaboration between Supervised Classification Model and LLM
Sep 26, 2025Legal Article Prediction (LAP) is a critical task in legal text classification, leveraging natural language processing (NLP) techniques to automatically predict relevant legal articles based on the fact descriptions of cases. As a foundational step in legal decision-making, LAP plays a pivotal role in determining subsequent judgments, such as charges and penalties. Despite its importance, existing methods face significant challenges in addressing the complexities of LAP. Supervised classification models (SCMs), such as CNN and BERT, struggle to fully capture intricate fact patterns due to their inherent limitations. Conversely, large language models (LLMs), while excelling in generative tasks, perform suboptimally in predictive scenarios due to the abstract and ID-based nature of legal articles. Furthermore, the diversity of legal systems across jurisdictions exacerbates the issue, as most approaches are tailored to specific countries and lack broader applicability. To address these limitations, we propose Uni-LAP, a universal framework for legal article prediction that integrates the strengths of SCMs and LLMs through tight collaboration. Specifically, in Uni-LAP, the SCM is enhanced with a novel Top-K loss function to generate accurate candidate articles, while the LLM employs syllogism-inspired reasoning to refine the final predictions. We evaluated Uni-LAP on datasets from multiple jurisdictions, and empirical results demonstrate that our approach consistently outperforms existing baselines, showcasing its effectiveness and generalizability.
ClaimGen-CN: A Large-scale Chinese Dataset for Legal Claim Generation
Aug 24, 2025Legal claims refer to the plaintiff's demands in a case and are essential to guiding judicial reasoning and case resolution. While many works have focused on improving the efficiency of legal professionals, the research on helping non-professionals (e.g., plaintiffs) remains unexplored. This paper explores the problem of legal claim generation based on the given case's facts. First, we construct ClaimGen-CN, the first dataset for Chinese legal claim generation task, from various real-world legal disputes. Additionally, we design an evaluation metric tailored for assessing the generated claims, which encompasses two essential dimensions: factuality and clarity. Building on this, we conduct a comprehensive zero-shot evaluation of state-of-the-art general and legal-domain large language models. Our findings highlight the limitations of the current models in factual precision and expressive clarity, pointing to the need for more targeted development in this domain. To encourage further exploration of this important task, we will make the dataset publicly available.
OS Agents: A Survey on MLLM-based Agents for General Computing Devices Use
Aug 06, 2025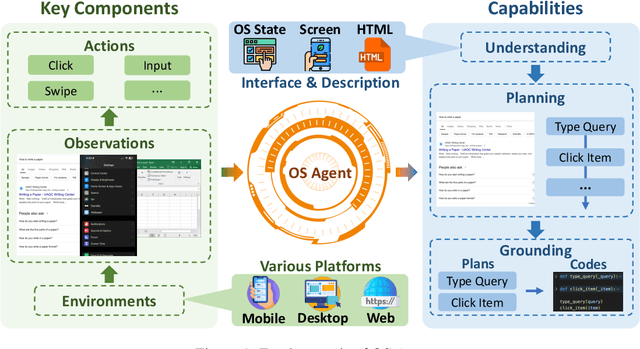
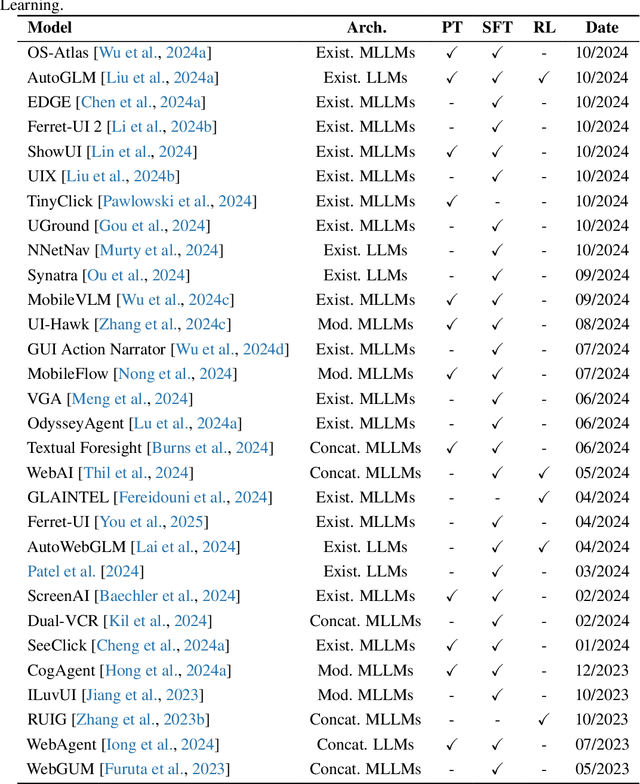
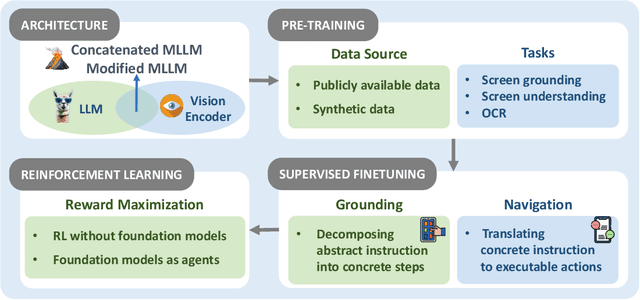
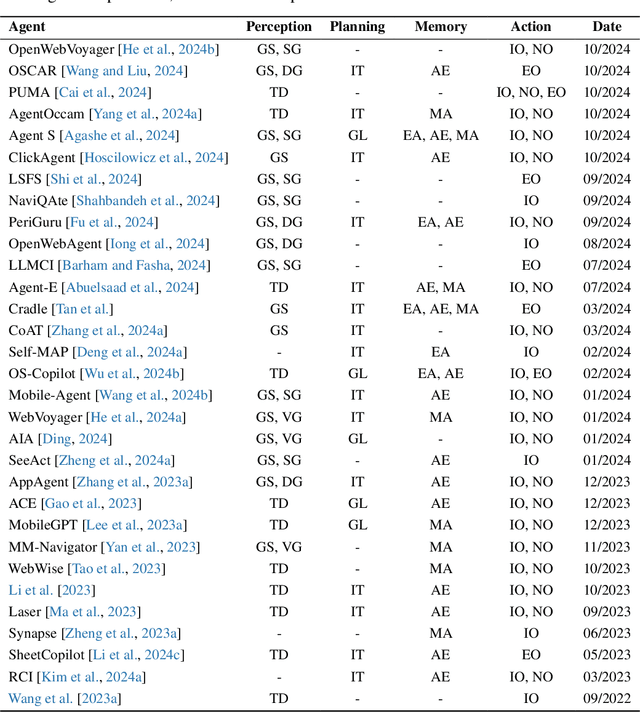
The dream to create AI assistants as capable and versatile as the fictional J.A.R.V.I.S from Iron Man has long captivated imaginations. With the evolution of (multi-modal) large language models ((M)LLMs), this dream is closer to reality, as (M)LLM-based Agents using computing devices (e.g., computers and mobile phones) by operating within the environments and interfaces (e.g., Graphical User Interface (GUI)) provided by operating systems (OS) to automate tasks have significantly advanced. This paper presents a comprehensive survey of these advanced agents, designated as OS Agents. We begin by elucidating the fundamentals of OS Agents, exploring their key components including the environment, observation space, and action space, and outlining essential capabilities such as understanding, planning, and grounding. We then examine methodologies for constructing OS Agents, focusing on domain-specific foundation models and agent frameworks. A detailed review of evaluation protocols and benchmarks highlights how OS Agents are assessed across diverse tasks. Finally, we discuss current challenges and identify promising directions for future research, including safety and privacy, personalization and self-evolution. This survey aims to consolidate the state of OS Agents research, providing insights to guide both academic inquiry and industrial development. An open-source GitHub repository is maintained as a dynamic resource to foster further innovation in this field. We present a 9-page version of our work, accepted by ACL 2025, to provide a concise overview to the domain.
D-Fusion: Direct Preference Optimization for Aligning Diffusion Models with Visually Consistent Samples
May 28, 2025
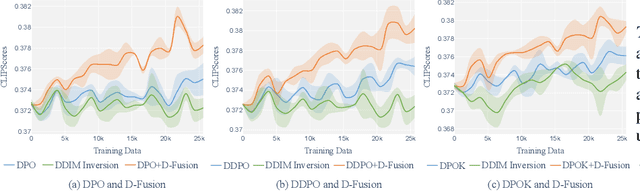
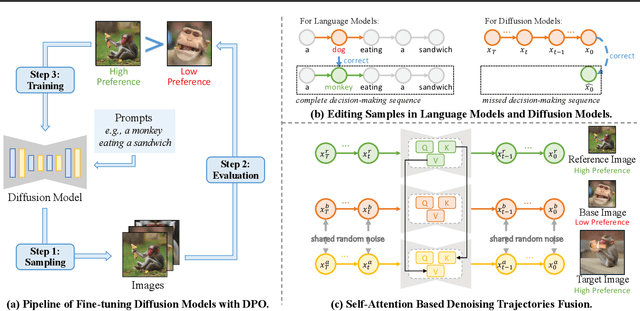
The practical applications of diffusion models have been limited by the misalignment between generated images and corresponding text prompts. Recent studies have introduced direct preference optimization (DPO) to enhance the alignment of these models. However, the effectiveness of DPO is constrained by the issue of visual inconsistency, where the significant visual disparity between well-aligned and poorly-aligned images prevents diffusion models from identifying which factors contribute positively to alignment during fine-tuning. To address this issue, this paper introduces D-Fusion, a method to construct DPO-trainable visually consistent samples. On one hand, by performing mask-guided self-attention fusion, the resulting images are not only well-aligned, but also visually consistent with given poorly-aligned images. On the other hand, D-Fusion can retain the denoising trajectories of the resulting images, which are essential for DPO training. Extensive experiments demonstrate the effectiveness of D-Fusion in improving prompt-image alignment when applied to different reinforcement learning algorithms.
LeCoDe: A Benchmark Dataset for Interactive Legal Consultation Dialogue Evaluation
May 26, 2025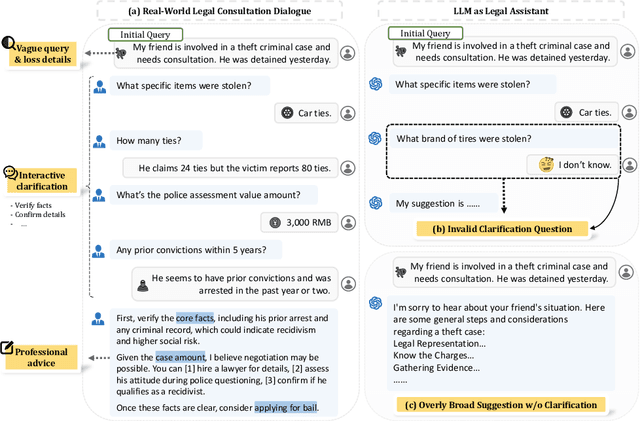


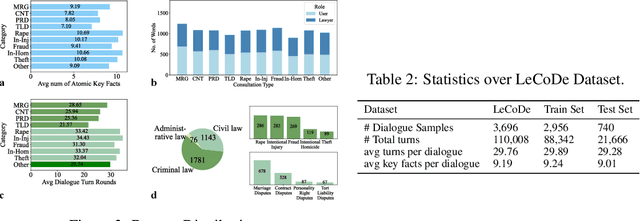
Legal consultation is essential for safeguarding individual rights and ensuring access to justice, yet remains costly and inaccessible to many individuals due to the shortage of professionals. While recent advances in Large Language Models (LLMs) offer a promising path toward scalable, low-cost legal assistance, current systems fall short in handling the interactive and knowledge-intensive nature of real-world consultations. To address these challenges, we introduce LeCoDe, a real-world multi-turn benchmark dataset comprising 3,696 legal consultation dialogues with 110,008 dialogue turns, designed to evaluate and improve LLMs' legal consultation capability. With LeCoDe, we innovatively collect live-streamed consultations from short-video platforms, providing authentic multi-turn legal consultation dialogues. The rigorous annotation by legal experts further enhances the dataset with professional insights and expertise. Furthermore, we propose a comprehensive evaluation framework that assesses LLMs' consultation capabilities in terms of (1) clarification capability and (2) professional advice quality. This unified framework incorporates 12 metrics across two dimensions. Through extensive experiments on various general and domain-specific LLMs, our results reveal significant challenges in this task, with even state-of-the-art models like GPT-4 achieving only 39.8% recall for clarification and 59% overall score for advice quality, highlighting the complexity of professional consultation scenarios. Based on these findings, we further explore several strategies to enhance LLMs' legal consultation abilities. Our benchmark contributes to advancing research in legal domain dialogue systems, particularly in simulating more real-world user-expert interactions.
Embracing Imperfection: Simulating Students with Diverse Cognitive Levels Using LLM-based Agents
May 26, 2025Large language models (LLMs) are revolutionizing education, with LLM-based agents playing a key role in simulating student behavior. A major challenge in student simulation is modeling the diverse learning patterns of students at various cognitive levels. However, current LLMs, typically trained as ``helpful assistants'', target at generating perfect responses. As a result, they struggle to simulate students with diverse cognitive abilities, as they often produce overly advanced answers, missing the natural imperfections that characterize student learning and resulting in unrealistic simulations. To address this issue, we propose a training-free framework for student simulation. We begin by constructing a cognitive prototype for each student using a knowledge graph, which captures their understanding of concepts from past learning records. This prototype is then mapped to new tasks to predict student performance. Next, we simulate student solutions based on these predictions and iteratively refine them using a beam search method to better replicate realistic mistakes. To validate our approach, we construct the \texttt{Student\_100} dataset, consisting of $100$ students working on Python programming and $5,000$ learning records. Experimental results show that our method consistently outperforms baseline models, achieving $100\%$ improvement in simulation accuracy.
AppealCase: A Dataset and Benchmark for Civil Case Appeal Scenarios
May 22, 2025



Recent advances in LegalAI have primarily focused on individual case judgment analysis, often overlooking the critical appellate process within the judicial system. Appeals serve as a core mechanism for error correction and ensuring fair trials, making them highly significant both in practice and in research. To address this gap, we present the AppealCase dataset, consisting of 10,000 pairs of real-world, matched first-instance and second-instance documents across 91 categories of civil cases. The dataset also includes detailed annotations along five dimensions central to appellate review: judgment reversals, reversal reasons, cited legal provisions, claim-level decisions, and whether there is new information in the second instance. Based on these annotations, we propose five novel LegalAI tasks and conduct a comprehensive evaluation across 20 mainstream models. Experimental results reveal that all current models achieve less than 50% F1 scores on the judgment reversal prediction task, highlighting the complexity and challenge of the appeal scenario. We hope that the AppealCase dataset will spur further research in LegalAI for appellate case analysis and contribute to improving consistency in judicial decision-making.