 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEpiPersona: Persona Projection and Episode Coupling for Pluralistic Preference Modeling
Mar 30, 2026Pluralistic alignment is essential for adapting large language models (LLMs) to the diverse preferences of individuals and minority groups. However, existing approaches often mix stable personal traits with episode-specific factors, limiting their ability to generalize across episodes. To address this challenge, we introduce EpiPersona, a framework for explicit persona-episode coupling. EpiPersona first projects noisy preference feedback into a low-dimensional persona space, where similar personas are aggregated into shared discrete codes. This process separates enduring personal characteristics from situational signals without relying on predefined preference dimensions. The inferred persona representation is then coupled with the current episode, enabling episode-aware preference prediction. Extensive experiments show that EpiPersona consistently outperforms the baselines. It achieves notable performance gains in hard episodic-shift scenarios, while remaining effective with sparse preference data.
AlignSurvey: A Comprehensive Benchmark for Human Preferences Alignment in Social Surveys
Nov 13, 2025Understanding human attitudes, preferences, and behaviors through social surveys is essential for academic research and policymaking. Yet traditional surveys face persistent challenges, including fixed-question formats, high costs, limited adaptability, and difficulties ensuring cross-cultural equivalence. While recent studies explore large language models (LLMs) to simulate survey responses, most are limited to structured questions, overlook the entire survey process, and risks under-representing marginalized groups due to training data biases. We introduce AlignSurvey, the first benchmark that systematically replicates and evaluates the full social survey pipeline using LLMs. It defines four tasks aligned with key survey stages: social role modeling, semi-structured interview modeling, attitude stance modeling and survey response modeling. It also provides task-specific evaluation metrics to assess alignment fidelity, consistency, and fairness at both individual and group levels, with a focus on demographic diversity. To support AlignSurvey, we construct a multi-tiered dataset architecture: (i) the Social Foundation Corpus, a cross-national resource with 44K+ interview dialogues and 400K+ structured survey records; and (ii) a suite of Entire-Pipeline Survey Datasets, including the expert-annotated AlignSurvey-Expert (ASE) and two nationally representative surveys for cross-cultural evaluation. We release the SurveyLM family, obtained through two-stage fine-tuning of open-source LLMs, and offer reference models for evaluating domain-specific alignment. All datasets, models, and tools are available at github and huggingface to support transparent and socially responsible research.
LeCoDe: A Benchmark Dataset for Interactive Legal Consultation Dialogue Evaluation
May 26, 2025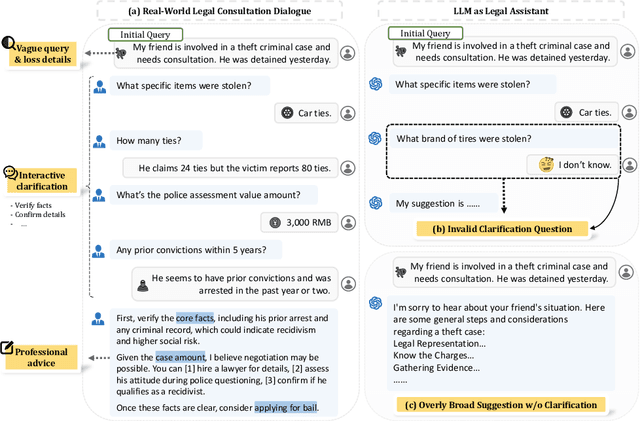


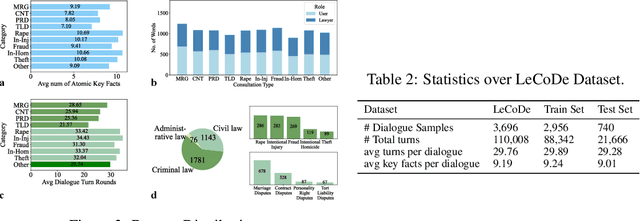
Legal consultation is essential for safeguarding individual rights and ensuring access to justice, yet remains costly and inaccessible to many individuals due to the shortage of professionals. While recent advances in Large Language Models (LLMs) offer a promising path toward scalable, low-cost legal assistance, current systems fall short in handling the interactive and knowledge-intensive nature of real-world consultations. To address these challenges, we introduce LeCoDe, a real-world multi-turn benchmark dataset comprising 3,696 legal consultation dialogues with 110,008 dialogue turns, designed to evaluate and improve LLMs' legal consultation capability. With LeCoDe, we innovatively collect live-streamed consultations from short-video platforms, providing authentic multi-turn legal consultation dialogues. The rigorous annotation by legal experts further enhances the dataset with professional insights and expertise. Furthermore, we propose a comprehensive evaluation framework that assesses LLMs' consultation capabilities in terms of (1) clarification capability and (2) professional advice quality. This unified framework incorporates 12 metrics across two dimensions. Through extensive experiments on various general and domain-specific LLMs, our results reveal significant challenges in this task, with even state-of-the-art models like GPT-4 achieving only 39.8% recall for clarification and 59% overall score for advice quality, highlighting the complexity of professional consultation scenarios. Based on these findings, we further explore several strategies to enhance LLMs' legal consultation abilities. Our benchmark contributes to advancing research in legal domain dialogue systems, particularly in simulating more real-world user-expert interactions.
LangGFM: A Large Language Model Alone Can be a Powerful Graph Foundation Model
Oct 19, 2024



Graph foundation models (GFMs) have recently gained significant attention. However, the unique data processing and evaluation setups employed by different studies hinder a deeper understanding of their progress. Additionally, current research tends to focus on specific subsets of graph learning tasks, such as structural tasks, node-level tasks, or classification tasks. As a result, they often incorporate specialized modules tailored to particular task types, losing their applicability to other graph learning tasks and contradicting the original intent of foundation models to be universal. Therefore, to enhance consistency, coverage, and diversity across domains, tasks, and research interests within the graph learning community in the evaluation of GFMs, we propose GFMBench-a systematic and comprehensive benchmark comprising 26 datasets. Moreover, we introduce LangGFM, a novel GFM that relies entirely on large language models. By revisiting and exploring the effective graph textualization principles, as well as repurposing successful techniques from graph augmentation and graph self-supervised learning within the language space, LangGFM achieves performance on par with or exceeding the state of the art across GFMBench, which can offer us new perspectives, experiences, and baselines to drive forward the evolution of GFMs.
Can Large Language Models Grasp Legal Theories? Enhance Legal Reasoning with Insights from Multi-Agent Collaboration
Oct 03, 2024



Large Language Models (LLMs) could struggle to fully understand legal theories and perform complex legal reasoning tasks. In this study, we introduce a challenging task (confusing charge prediction) to better evaluate LLMs' understanding of legal theories and reasoning capabilities. We also propose a novel framework: Multi-Agent framework for improving complex Legal Reasoning capability (MALR). MALR employs non-parametric learning, encouraging LLMs to automatically decompose complex legal tasks and mimic human learning process to extract insights from legal rules, helping LLMs better understand legal theories and enhance their legal reasoning abilities. Extensive experiments on multiple real-world datasets demonstrate that the proposed framework effectively addresses complex reasoning issues in practical scenarios, paving the way for more reliable applications in the legal domain.
Towards Human-like Perception: Learning Structural Causal Model in Heterogeneous Graph
Dec 10, 2023



Heterogeneous graph neural networks have become popular in various domains. However, their generalizability and interpretability are limited due to the discrepancy between their inherent inference flows and human reasoning logic or underlying causal relationships for the learning problem. This study introduces a novel solution, HG-SCM (Heterogeneous Graph as Structural Causal Model). It can mimic the human perception and decision process through two key steps: constructing intelligible variables based on semantics derived from the graph schema and automatically learning task-level causal relationships among these variables by incorporating advanced causal discovery techniques. We compared HG-SCM to seven state-of-the-art baseline models on three real-world datasets, under three distinct and ubiquitous out-of-distribution settings. HG-SCM achieved the highest average performance rank with minimal standard deviation, substantiating its effectiveness and superiority in terms of both predictive power and generalizability. Additionally, the visualization and analysis of the auto-learned causal diagrams for the three tasks aligned well with domain knowledge and human cognition, demonstrating prominent interpretability. HG-SCM's human-like nature and its enhanced generalizability and interpretability make it a promising solution for special scenarios where transparency and trustworthiness are paramount.
* 28 pages, 10 figures, 6 tables, accepted by Information Processing & Management