 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Local vs. External: A Game-Theoretic Framework for Trustworthy Knowledge Acquisition
Apr 25, 2026Cloud-hosted Large Language Models (LLMs) offer unmatched reasoning capabilities and dynamic knowledge, yet submitting raw queries to these external services risks exposing sensitive user intent. Conversely, relying exclusively on trusted local models preserves privacy but often compromises answer quality due to limited parameter scale and knowledge. To resolve this dilemma, we propose Game-theoretic Trustworthy Knowledge Acquisition (GTKA), a framework that formulates the trade-off between knowledge utility and privacy as a strategic game. GTKA consists of three components: (i) a privacy-aware sub-query generator that decomposes sensitive intent into generalized, low-risk fragments; (ii) an adversarial reconstruction attacker that attempts to infer the original query from these fragments, providing adaptive leakage signals; and (iii) a trusted local integrator that synthesizes external responses within a secure boundary. By training the generator and attacker in an alternating adversarial manner, GTKA optimizes the sub-query generation policy to maximize knowledge acquisition accuracy while minimizing the reconstructability of the original sensitive intent. To validate our approach, we construct two sensitive-domain benchmarks in the biomedical and legal fields. Extensive experiments demonstrate that GTKA significantly reduces intent leakage compared to state-of-the-art baselines while maintaining high-fidelity answer quality.
EpiPersona: Persona Projection and Episode Coupling for Pluralistic Preference Modeling
Mar 30, 2026Pluralistic alignment is essential for adapting large language models (LLMs) to the diverse preferences of individuals and minority groups. However, existing approaches often mix stable personal traits with episode-specific factors, limiting their ability to generalize across episodes. To address this challenge, we introduce EpiPersona, a framework for explicit persona-episode coupling. EpiPersona first projects noisy preference feedback into a low-dimensional persona space, where similar personas are aggregated into shared discrete codes. This process separates enduring personal characteristics from situational signals without relying on predefined preference dimensions. The inferred persona representation is then coupled with the current episode, enabling episode-aware preference prediction. Extensive experiments show that EpiPersona consistently outperforms the baselines. It achieves notable performance gains in hard episodic-shift scenarios, while remaining effective with sparse preference data.
VitalDiagnosis: AI-Driven Ecosystem for 24/7 Vital Monitoring and Chronic Disease Management
Jan 22, 2026Chronic diseases have become the leading cause of death worldwide, a challenge intensified by strained medical resources and an aging population. Individually, patients often struggle to interpret early signs of deterioration or maintain adherence to care plans. In this paper, we introduce VitalDiagnosis, an LLM-driven ecosystem designed to shift chronic disease management from passive monitoring to proactive, interactive engagement. By integrating continuous data from wearable devices with the reasoning capabilities of LLMs, the system addresses both acute health anomalies and routine adherence. It analyzes triggers through context-aware inquiries, produces provisional insights within a collaborative patient-clinician workflow, and offers personalized guidance. This approach aims to promote a more proactive and cooperative care paradigm, with the potential to enhance patient self-management and reduce avoidable clinical workload.
Teaching According to Students' Aptitude: Personalized Mathematics Tutoring via Persona-, Memory-, and Forgetting-Aware LLMs
Nov 19, 2025Large Language Models (LLMs) are increasingly integrated into intelligent tutoring systems to provide human-like and adaptive instruction. However, most existing approaches fail to capture how students' knowledge evolves dynamically across their proficiencies, conceptual gaps, and forgetting patterns. This challenge is particularly acute in mathematics tutoring, where effective instruction requires fine-grained scaffolding precisely calibrated to each student's mastery level and cognitive retention. To address this issue, we propose TASA (Teaching According to Students' Aptitude), a student-aware tutoring framework that integrates persona, memory, and forgetting dynamics for personalized mathematics learning. Specifically, TASA maintains a structured student persona capturing proficiency profiles and an event memory recording prior learning interactions. By incorporating a continuous forgetting curve with knowledge tracing, TASA dynamically updates each student's mastery state and generates contextually appropriate, difficulty-calibrated questions and explanations. Empirical results demonstrate that TASA achieves superior learning outcomes and more adaptive tutoring behavior compared to representative baselines, underscoring the importance of modeling temporal forgetting and learner profiles in LLM-based tutoring systems.
AlignSurvey: A Comprehensive Benchmark for Human Preferences Alignment in Social Surveys
Nov 13, 2025Understanding human attitudes, preferences, and behaviors through social surveys is essential for academic research and policymaking. Yet traditional surveys face persistent challenges, including fixed-question formats, high costs, limited adaptability, and difficulties ensuring cross-cultural equivalence. While recent studies explore large language models (LLMs) to simulate survey responses, most are limited to structured questions, overlook the entire survey process, and risks under-representing marginalized groups due to training data biases. We introduce AlignSurvey, the first benchmark that systematically replicates and evaluates the full social survey pipeline using LLMs. It defines four tasks aligned with key survey stages: social role modeling, semi-structured interview modeling, attitude stance modeling and survey response modeling. It also provides task-specific evaluation metrics to assess alignment fidelity, consistency, and fairness at both individual and group levels, with a focus on demographic diversity. To support AlignSurvey, we construct a multi-tiered dataset architecture: (i) the Social Foundation Corpus, a cross-national resource with 44K+ interview dialogues and 400K+ structured survey records; and (ii) a suite of Entire-Pipeline Survey Datasets, including the expert-annotated AlignSurvey-Expert (ASE) and two nationally representative surveys for cross-cultural evaluation. We release the SurveyLM family, obtained through two-stage fine-tuning of open-source LLMs, and offer reference models for evaluating domain-specific alignment. All datasets, models, and tools are available at github and huggingface to support transparent and socially responsible research.
LeCoDe: A Benchmark Dataset for Interactive Legal Consultation Dialogue Evaluation
May 26, 2025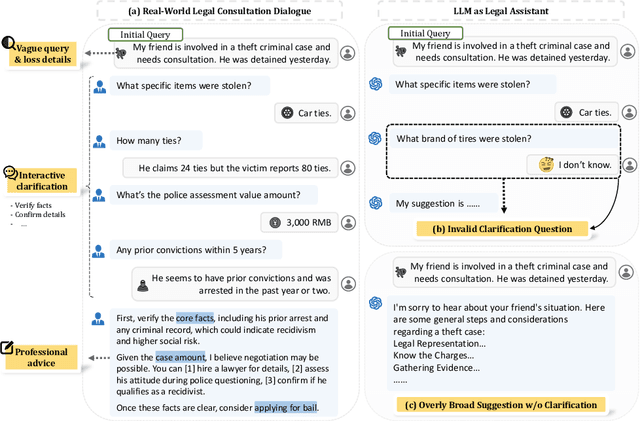


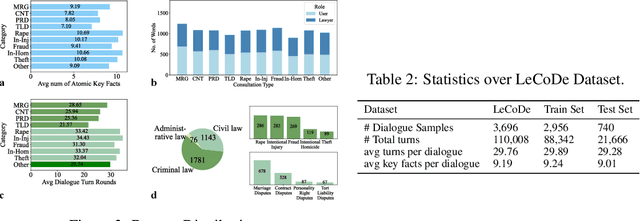
Legal consultation is essential for safeguarding individual rights and ensuring access to justice, yet remains costly and inaccessible to many individuals due to the shortage of professionals. While recent advances in Large Language Models (LLMs) offer a promising path toward scalable, low-cost legal assistance, current systems fall short in handling the interactive and knowledge-intensive nature of real-world consultations. To address these challenges, we introduce LeCoDe, a real-world multi-turn benchmark dataset comprising 3,696 legal consultation dialogues with 110,008 dialogue turns, designed to evaluate and improve LLMs' legal consultation capability. With LeCoDe, we innovatively collect live-streamed consultations from short-video platforms, providing authentic multi-turn legal consultation dialogues. The rigorous annotation by legal experts further enhances the dataset with professional insights and expertise. Furthermore, we propose a comprehensive evaluation framework that assesses LLMs' consultation capabilities in terms of (1) clarification capability and (2) professional advice quality. This unified framework incorporates 12 metrics across two dimensions. Through extensive experiments on various general and domain-specific LLMs, our results reveal significant challenges in this task, with even state-of-the-art models like GPT-4 achieving only 39.8% recall for clarification and 59% overall score for advice quality, highlighting the complexity of professional consultation scenarios. Based on these findings, we further explore several strategies to enhance LLMs' legal consultation abilities. Our benchmark contributes to advancing research in legal domain dialogue systems, particularly in simulating more real-world user-expert interactions.
LangGFM: A Large Language Model Alone Can be a Powerful Graph Foundation Model
Oct 19, 2024



Graph foundation models (GFMs) have recently gained significant attention. However, the unique data processing and evaluation setups employed by different studies hinder a deeper understanding of their progress. Additionally, current research tends to focus on specific subsets of graph learning tasks, such as structural tasks, node-level tasks, or classification tasks. As a result, they often incorporate specialized modules tailored to particular task types, losing their applicability to other graph learning tasks and contradicting the original intent of foundation models to be universal. Therefore, to enhance consistency, coverage, and diversity across domains, tasks, and research interests within the graph learning community in the evaluation of GFMs, we propose GFMBench-a systematic and comprehensive benchmark comprising 26 datasets. Moreover, we introduce LangGFM, a novel GFM that relies entirely on large language models. By revisiting and exploring the effective graph textualization principles, as well as repurposing successful techniques from graph augmentation and graph self-supervised learning within the language space, LangGFM achieves performance on par with or exceeding the state of the art across GFMBench, which can offer us new perspectives, experiences, and baselines to drive forward the evolution of GFMs.
Can Large Language Models Grasp Legal Theories? Enhance Legal Reasoning with Insights from Multi-Agent Collaboration
Oct 03, 2024



Large Language Models (LLMs) could struggle to fully understand legal theories and perform complex legal reasoning tasks. In this study, we introduce a challenging task (confusing charge prediction) to better evaluate LLMs' understanding of legal theories and reasoning capabilities. We also propose a novel framework: Multi-Agent framework for improving complex Legal Reasoning capability (MALR). MALR employs non-parametric learning, encouraging LLMs to automatically decompose complex legal tasks and mimic human learning process to extract insights from legal rules, helping LLMs better understand legal theories and enhance their legal reasoning abilities. Extensive experiments on multiple real-world datasets demonstrate that the proposed framework effectively addresses complex reasoning issues in practical scenarios, paving the way for more reliable applications in the legal domain.
Evolving Knowledge Distillation with Large Language Models and Active Learning
Mar 11, 2024



Large language models (LLMs) have demonstrated remarkable capabilities across various NLP tasks. However, their computational costs are prohibitively high. To address this issue, previous research has attempted to distill the knowledge of LLMs into smaller models by generating annotated data. Nonetheless, these works have mainly focused on the direct use of LLMs for text generation and labeling, without fully exploring their potential to comprehend the target task and acquire valuable knowledge. In this paper, we propose EvoKD: Evolving Knowledge Distillation, which leverages the concept of active learning to interactively enhance the process of data generation using large language models, simultaneously improving the task capabilities of small domain model (student model). Different from previous work, we actively analyze the student model's weaknesses, and then synthesize labeled samples based on the analysis. In addition, we provide iterative feedback to the LLMs regarding the student model's performance to continuously construct diversified and challenging samples. Experiments and analysis on different NLP tasks, namely, text classification and named entity recognition show the effectiveness of EvoKD.
Tree-Based Hard Attention with Self-Motivation for Large Language Models
Feb 14, 2024



While large language models (LLMs) excel at understanding and generating plain text, they are not specifically tailored to handle hierarchical text structures. Extracting the task-desired property from their natural language responses typically necessitates additional processing steps. In fact, selectively comprehending the hierarchical structure of large-scale text is pivotal to understanding its substance. Aligning LLMs more closely with the classification or regression values of specific task through prompting also remains challenging. To this end, we propose a novel framework called Tree-Based Hard Attention with Self-Motivation for Large Language Models (TEAROOM). TEAROOM incorporates a tree-based hard attention mechanism for LLMs to process hierarchically structured text inputs. By leveraging prompting, it enables a frozen LLM to selectively focus on relevant leaves in relation to the root, generating a tailored symbolic representation of their relationship. Moreover, TEAROOM comprises a self-motivation strategy for another LLM equipped with a trainable adapter and a linear layer. The selected symbolic outcomes are integrated into another prompt, along with the predictive value of the task. We iteratively feed output values back into the prompt, enabling the trainable LLM to progressively approximate the golden truth. TEAROOM outperforms existing state-of-the-art methods in experimental evaluations across three benchmark datasets, showing its effectiveness in estimating task-specific properties. Through comprehensive experiments and analysis, we have validated the ability of TEAROOM to gradually approach the underlying golden truth through multiple inferences.