 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuFIA: Language-Guided Augmented Dexterity for Robotic Surgical Assistants
May 08, 2024



In this work, we present SuFIA, the first framework for natural language-guided augmented dexterity for robotic surgical assistants. SuFIA incorporates the strong reasoning capabilities of large language models (LLMs) with perception modules to implement high-level planning and low-level control of a robot for surgical sub-task execution. This enables a learning-free approach to surgical augmented dexterity without any in-context examples or motion primitives. SuFIA uses a human-in-the-loop paradigm by restoring control to the surgeon in the case of insufficient information, mitigating unexpected errors for mission-critical tasks. We evaluate SuFIA on four surgical sub-tasks in a simulation environment and two sub-tasks on a physical surgical robotic platform in the lab, demonstrating its ability to perform common surgical sub-tasks through supervised autonomous operation under challenging physical and workspace conditions. Project website: orbit-surgical.github.io/sufia
IntervenGen: Interventional Data Generation for Robust and Data-Efficient Robot Imitation Learning
May 02, 2024Imitation learning is a promising paradigm for training robot control policies, but these policies can suffer from distribution shift, where the conditions at evaluation time differ from those in the training data. A popular approach for increasing policy robustness to distribution shift is interactive imitation learning (i.e., DAgger and variants), where a human operator provides corrective interventions during policy rollouts. However, collecting a sufficient amount of interventions to cover the distribution of policy mistakes can be burdensome for human operators. We propose IntervenGen (I-Gen), a novel data generation system that can autonomously produce a large set of corrective interventions with rich coverage of the state space from a small number of human interventions. We apply I-Gen to 4 simulated environments and 1 physical environment with object pose estimation error and show that it can increase policy robustness by up to 39x with only 10 human interventions. Videos and more results are available at https://sites.google.com/view/intervengen2024.
ORBIT-Surgical: An Open-Simulation Framework for Learning Surgical Augmented Dexterity
Apr 24, 2024



Physics-based simulations have accelerated progress in robot learning for driving, manipulation, and locomotion. Yet, a fast, accurate, and robust surgical simulation environment remains a challenge. In this paper, we present ORBIT-Surgical, a physics-based surgical robot simulation framework with photorealistic rendering in NVIDIA Omniverse. We provide 14 benchmark surgical tasks for the da Vinci Research Kit (dVRK) and Smart Tissue Autonomous Robot (STAR) which represent common subtasks in surgical training. ORBIT-Surgical leverages GPU parallelization to train reinforcement learning and imitation learning algorithms to facilitate study of robot learning to augment human surgical skills. ORBIT-Surgical also facilitates realistic synthetic data generation for active perception tasks. We demonstrate ORBIT-Surgical sim-to-real transfer of learned policies onto a physical dVRK robot. Project website: orbit-surgical.github.io
STITCH: Augmented Dexterity for Suture Throws Including Thread Coordination and Handoffs
Apr 08, 2024



We present STITCH: an augmented dexterity pipeline that performs Suture Throws Including Thread Coordination and Handoffs. STITCH iteratively performs needle insertion, thread sweeping, needle extraction, suture cinching, needle handover, and needle pose correction with failure recovery policies. We introduce a novel visual 6D needle pose estimation framework using a stereo camera pair and new suturing motion primitives. We compare STITCH to baselines, including a proprioception-only and a policy without visual servoing. In physical experiments across 15 trials, STITCH achieves an average of 2.93 sutures without human intervention and 4.47 sutures with human intervention. See https://sites.google.com/berkeley.edu/stitch for code and supplemental materials.
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Mar 19, 2024



The creation of large, diverse, high-quality robot manipulation datasets is an important stepping stone on the path toward more capable and robust robotic manipulation policies. However, creating such datasets is challenging: collecting robot manipulation data in diverse environments poses logistical and safety challenges and requires substantial investments in hardware and human labour. As a result, even the most general robot manipulation policies today are mostly trained on data collected in a small number of environments with limited scene and task diversity. In this work, we introduce DROID (Distributed Robot Interaction Dataset), a diverse robot manipulation dataset with 76k demonstration trajectories or 350 hours of interaction data, collected across 564 scenes and 84 tasks by 50 data collectors in North America, Asia, and Europe over the course of 12 months. We demonstrate that training with DROID leads to policies with higher performance and improved generalization ability. We open source the full dataset, policy learning code, and a detailed guide for reproducing our robot hardware setup.
Lifelong LERF: Local 3D Semantic Inventory Monitoring Using FogROS2
Mar 15, 2024



Inventory monitoring in homes, factories, and retail stores relies on maintaining data despite objects being swapped, added, removed, or moved. We introduce Lifelong LERF, a method that allows a mobile robot with minimal compute to jointly optimize a dense language and geometric representation of its surroundings. Lifelong LERF maintains this representation over time by detecting semantic changes and selectively updating these regions of the environment, avoiding the need to exhaustively remap. Human users can query inventory by providing natural language queries and receiving a 3D heatmap of potential object locations. To manage the computational load, we use Fog-ROS2, a cloud robotics platform, to offload resource-intensive tasks. Lifelong LERF obtains poses from a monocular RGBD SLAM backend, and uses these poses to progressively optimize a Language Embedded Radiance Field (LERF) for semantic monitoring. Experiments with 3-5 objects arranged on a tabletop and a Turtlebot with a RealSense camera suggest that Lifelong LERF can persistently adapt to changes in objects with up to 91% accuracy.
Mirage: Cross-Embodiment Zero-Shot Policy Transfer with Cross-Painting
Feb 29, 2024



The ability to reuse collected data and transfer trained policies between robots could alleviate the burden of additional data collection and training. While existing approaches such as pretraining plus finetuning and co-training show promise, they do not generalize to robots unseen in training. Focusing on common robot arms with similar workspaces and 2-jaw grippers, we investigate the feasibility of zero-shot transfer. Through simulation studies on 8 manipulation tasks, we find that state-based Cartesian control policies can successfully zero-shot transfer to a target robot after accounting for forward dynamics. To address robot visual disparities for vision-based policies, we introduce Mirage, which uses "cross-painting"--masking out the unseen target robot and inpainting the seen source robot--during execution in real time so that it appears to the policy as if the trained source robot were performing the task. Despite its simplicity, our extensive simulation and physical experiments provide strong evidence that Mirage can successfully zero-shot transfer between different robot arms and grippers with only minimal performance degradation on a variety of manipulation tasks such as picking, stacking, and assembly, significantly outperforming a generalist policy. Project website: https://robot-mirage.github.io/
A Touch, Vision, and Language Dataset for Multimodal Alignment
Feb 20, 2024Touch is an important sensing modality for humans, but it has not yet been incorporated into a multimodal generative language model. This is partially due to the difficulty of obtaining natural language labels for tactile data and the complexity of aligning tactile readings with both visual observations and language descriptions. As a step towards bridging that gap, this work introduces a new dataset of 44K in-the-wild vision-touch pairs, with English language labels annotated by humans (10%) and textual pseudo-labels from GPT-4V (90%). We use this dataset to train a vision-language-aligned tactile encoder for open-vocabulary classification and a touch-vision-language (TVL) model for text generation using the trained encoder. Results suggest that by incorporating touch, the TVL model improves (+29% classification accuracy) touch-vision-language alignment over existing models trained on any pair of those modalities. Although only a small fraction of the dataset is human-labeled, the TVL model demonstrates improved visual-tactile understanding over GPT-4V (+12%) and open-source vision-language models (+32%) on a new touch-vision understanding benchmark. Code and data: https://tactile-vlm.github.io.
Rethinking Patch Dependence for Masked Autoencoders
Jan 25, 2024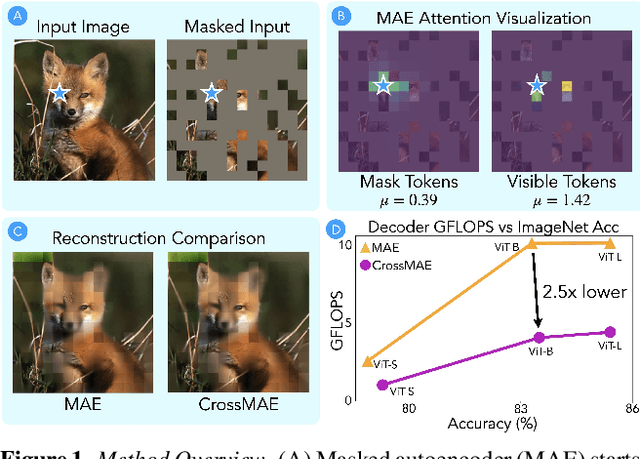
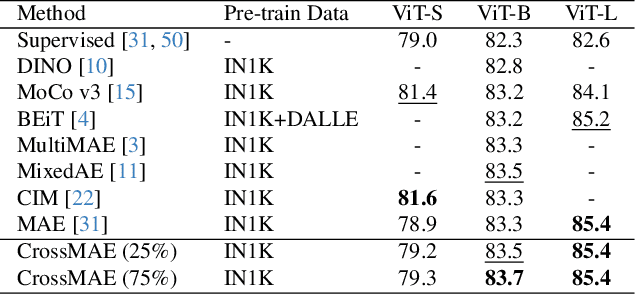

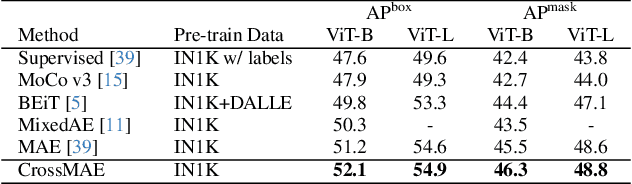
In this work, we re-examine inter-patch dependencies in the decoding mechanism of masked autoencoders (MAE). We decompose this decoding mechanism for masked patch reconstruction in MAE into self-attention and cross-attention. Our investigations suggest that self-attention between mask patches is not essential for learning good representations. To this end, we propose a novel pretraining framework: Cross-Attention Masked Autoencoders (CrossMAE). CrossMAE's decoder leverages only cross-attention between masked and visible tokens, with no degradation in downstream performance. This design also enables decoding only a small subset of mask tokens, boosting efficiency. Furthermore, each decoder block can now leverage different encoder features, resulting in improved representation learning. CrossMAE matches MAE in performance with 2.5 to 3.7$\times$ less decoding compute. It also surpasses MAE on ImageNet classification and COCO instance segmentation under the same compute. Code and models: https://crossmae.github.io
GARField: Group Anything with Radiance Fields
Jan 17, 2024Grouping is inherently ambiguous due to the multiple levels of granularity in which one can decompose a scene -- should the wheels of an excavator be considered separate or part of the whole? We present Group Anything with Radiance Fields (GARField), an approach for decomposing 3D scenes into a hierarchy of semantically meaningful groups from posed image inputs. To do this we embrace group ambiguity through physical scale: by optimizing a scale-conditioned 3D affinity feature field, a point in the world can belong to different groups of different sizes. We optimize this field from a set of 2D masks provided by Segment Anything (SAM) in a way that respects coarse-to-fine hierarchy, using scale to consistently fuse conflicting masks from different viewpoints. From this field we can derive a hierarchy of possible groupings via automatic tree construction or user interaction. We evaluate GARField on a variety of in-the-wild scenes and find it effectively extracts groups at many levels: clusters of objects, objects, and various subparts. GARField inherently represents multi-view consistent groupings and produces higher fidelity groups than the input SAM masks. GARField's hierarchical grouping could have exciting downstream applications such as 3D asset extraction or dynamic scene understanding. See the project website at https://www.garfield.studio/