 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePACER: Blockwise Pre-verification for Speculative Decoding with Adaptive Length
Feb 01, 2026Speculative decoding (SD) is a powerful technique for accelerating the inference process of large language models (LLMs) without sacrificing accuracy. Typically, SD employs a small draft model to generate a fixed number of draft tokens, which are then verified in parallel by the target model. However, our experiments reveal that the optimal draft length varies significantly across different decoding steps. This variation suggests that using a fixed draft length limits the potential for further improvements in decoding speed. To address this challenge, we propose Pacer, a novel approach that dynamically controls draft length using a lightweight, trainable pre-verification layer. This layer pre-verifies draft tokens blockwise before they are sent to the target model, allowing the draft model to stop token generation if the blockwise pre-verification fails. We implement Pacer on multiple SD model pairs and evaluate its performance across various benchmarks. Our results demonstrate that Pacer achieves up to 2.66x Speedup over autoregressive decoding and consistently outperforms standard speculative decoding. Furthermore, when integrated with Ouroboros, Pacer attains up to 3.09x Speedup.
CMANet: Channel-Masked Attention Network for Cooperative Multi-Base-Station 3D Positioning
Jan 31, 2026Achieving ubiquitous high-accuracy localization is crucial for next-generation wireless systems, yet remains challenging in multipath-rich urban environments. By exploiting the fine-grained multipath characteristics embedded in channel state information (CSI), more reliable and precise localization can be achieved. To address this, we present CMANet, a multi-BS cooperative positioning architecture that performs feature-level fusion of raw CSI using the proposed Channel Masked Attention (CMA) mechanism. The CMA encoder injects a physically grounded prior--per-BS channel gain--into the attention weights, thus emphasizing reliable links and suppressing spurious multipath. A lightweight LSTM decoder then treats subcarriers as a sequence to accumulate frequency-domain evidence into a final 3D position estimate. In a typical 5G NR-compliant urban simulation, CMANet achieves less than 0.5m median error and 1.0m 90th-percentile error, outperforming state-of-the-art benchmarks. Ablations verify the necessity of CMA and frequency accumulation. CMANet is edge-deployable and exemplifies an Integrated Sensing and Communication (ISAC)-aligned, cooperative paradigm for multi-BS CSI positioning.
Fronthaul-Efficient Distributed Cooperative 3D Positioning with Quantized Latent CSI Embeddings
Jan 31, 2026High-precision three-dimensional (3D) positioning in dense urban non-line-of-sight (NLOS) environments benefits significantly from cooperation among multiple distributed base stations (BSs). However, forwarding raw CSI from multiple BSs to a central unit (CU) incurs prohibitive fronthaul overhead, which limits scalable cooperative positioning in practice. This paper proposes a learning-based edge-cloud cooperative positioning framework under limited-capacity fronthaul constraints. In the proposed architecture, a neural network is deployed at each BS to compress the locally estimated CSI into a quantized representation subject to a fixed fronthaul payload. The quantized CSI is transmitted to the CU, which performs cooperative 3D positioning by jointly processing the compressed CSI received from multiple BSs. The proposed framework adopts a two-stage training strategy consisting of self-supervised local training at the BSs and end-to-end joint training for positioning at the CU. Simulation results based on a 3.5~GHz 5G NR compliant urban ray-tracing scenario with six BSs and 20~MHz bandwidth show that the proposed method achieves a mean 3D positioning error of 0.48~m and a 90th-percentile error of 0.83~m, while reducing the fronthaul payload to 6.25% of lossless CSI forwarding. The achieved performance is close to that of cooperative positioning with full CSI exchange.
Habibi: Laying the Open-Source Foundation of Unified-Dialectal Arabic Speech Synthesis
Jan 20, 2026A notable gap persists in speech synthesis research and development for Arabic dialects, particularly from a unified modeling perspective. Despite its high practical value, the inherent linguistic complexity of Arabic dialects, further compounded by a lack of standardized data, benchmarks, and evaluation guidelines, steers researchers toward safer ground. To bridge this divide, we present Habibi, a suite of specialized and unified text-to-speech models that harnesses existing open-source ASR corpora to support a wide range of high- to low-resource Arabic dialects through linguistically-informed curriculum learning. Our approach outperforms the leading commercial service in generation quality, while maintaining extensibility through effective in-context learning, without requiring text diacritization. We are committed to open-sourcing the model, along with creating the first systematic benchmark for multi-dialect Arabic speech synthesis. Furthermore, by identifying the key challenges in and establishing evaluation standards for the process, we aim to provide a solid groundwork for subsequent research. Resources at https://SWivid.github.io/Habibi/ .
PaperGuide: Making Small Language-Model Paper-Reading Agents More Efficient
Jan 19, 2026The accelerating growth of the scientific literature makes it increasingly difficult for researchers to track new advances through manual reading alone. Recent progress in large language models (LLMs) has therefore spurred interest in autonomous agents that can read scientific papers and extract task-relevant information. However, most existing approaches rely either on heavily engineered prompting or on a conventional SFT-RL training pipeline, both of which often lead to excessive and low-yield exploration. Drawing inspiration from cognitive science, we propose PaperCompass, a framework that mitigates these issues by separating high-level planning from fine-grained execution. PaperCompass first drafts an explicit plan that outlines the intended sequence of actions, and then performs detailed reasoning to instantiate each step by selecting the parameters for the corresponding function calls. To train such behavior, we introduce Draft-and-Follow Policy Optimization (DFPO), a tailored RL method that jointly optimizes both the draft plan and the final solution. DFPO can be viewed as a lightweight form of hierarchical reinforcement learning, aimed at narrowing the `knowing-doing' gap in LLMs. We provide a theoretical analysis that establishes DFPO's favorable optimization properties, supporting a stable and reliable training process. Experiments on paper-based question answering (Paper-QA) benchmarks show that PaperCompass improves efficiency over strong baselines without sacrificing performance, achieving results comparable to much larger models.
Think-Then-Generate: Reasoning-Aware Text-to-Image Diffusion with LLM Encoders
Jan 15, 2026Recent progress in text-to-image (T2I) diffusion models (DMs) has enabled high-quality visual synthesis from diverse textual prompts. Yet, most existing T2I DMs, even those equipped with large language model (LLM)-based text encoders, remain text-pixel mappers -- they employ LLMs merely as text encoders, without leveraging their inherent reasoning capabilities to infer what should be visually depicted given the textual prompt. To move beyond such literal generation, we propose the think-then-generate (T2G) paradigm, where the LLM-based text encoder is encouraged to reason about and rewrite raw user prompts; the states of the rewritten prompts then serve as diffusion conditioning. To achieve this, we first activate the think-then-rewrite pattern of the LLM encoder with a lightweight supervised fine-tuning process. Subsequently, the LLM encoder and diffusion backbone are co-optimized to ensure faithful reasoning about the context and accurate rendering of the semantics via Dual-GRPO. In particular, the text encoder is reinforced using image-grounded rewards to infer and recall world knowledge, while the diffusion backbone is pushed to produce semantically consistent and visually coherent images. Experiments show substantial improvements in factual consistency, semantic alignment, and visual realism across reasoning-based image generation and editing benchmarks, achieving 0.79 on WISE score, nearly on par with GPT-4. Our results constitute a promising step toward next-generation unified models with reasoning, expression, and demonstration capacities.
SLAM-LLM: A Modular, Open-Source Multimodal Large Language Model Framework and Best Practice for Speech, Language, Audio and Music Processing
Jan 14, 2026The recent surge in open-source Multimodal Large Language Models (MLLM) frameworks, such as LLaVA, provides a convenient kickoff for artificial intelligence developers and researchers. However, most of the MLLM frameworks take vision as the main input modality, and provide limited in-depth support for the modality of speech, audio, and music. This situation hinders the development of audio-language models, and forces researchers to spend a lot of effort on code writing and hyperparameter tuning. We present SLAM-LLM, an open-source deep learning framework designed to train customized MLLMs, focused on speech, language, audio, and music processing. SLAM-LLM provides a modular configuration of different encoders, projectors, LLMs, and parameter-efficient fine-tuning plugins. SLAM-LLM also includes detailed training and inference recipes for mainstream tasks, along with high-performance checkpoints like LLM-based Automatic Speech Recognition (ASR), Automated Audio Captioning (AAC), and Music Captioning (MC). Some of these recipes have already reached or are nearing state-of-the-art performance, and some relevant techniques have also been accepted by academic papers. We hope SLAM-LLM will accelerate iteration, development, data engineering, and model training for researchers. We are committed to continually pushing forward audio-based MLLMs through this open-source framework, and call on the community to contribute to the LLM-based speech, audio and music processing.
What Does the Speaker Embedding Encode?
Dec 20, 2025



Developing a good speaker embedding has received tremendous interest in the speech community, with representations such as i-vector and d-vector demonstrating remarkable performance across various tasks. Despite their widespread adoption, a fundamental question remains largely unexplored: what properties are actually encoded in these embeddings? To address this gap, we conduct a comprehensive analysis of three prominent speaker embedding methods: i-vector, d-vector, and RNN/LSTM-based sequence-vector (s-vector). Through carefully designed classification tasks, we systematically investigate their encoding capabilities across multiple dimensions, including speaker identity, gender, speaking rate, text content, word order, and channel information. Our analysis reveals distinct strengths and limitations of each embedding type: i-vector excels at speaker discrimination but encodes limited sequential information; s-vector captures text content and word order effectively but struggles with speaker identity; d-vector shows balanced performance but loses sequential information through averaging. Based on these insights, we propose a novel multi-task learning framework that integrates i-vector and s-vector, resulting in a new speaker embedding (i-s-vector) that combines their complementary advantages. Experimental results on RSR2015 demonstrate that the proposed i-s-vector achieves more than 50% EER reduction compared to the i-vector baseline on content mismatch trials, validating the effectiveness of our approach.
MergeDNA: Context-aware Genome Modeling with Dynamic Tokenization through Token Merging
Nov 17, 2025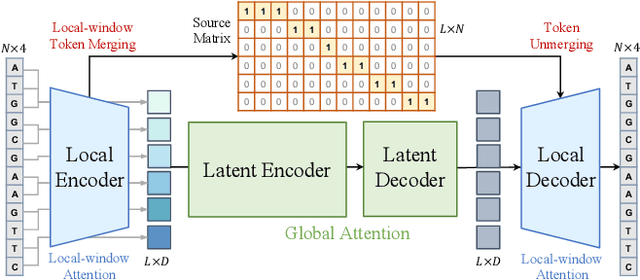

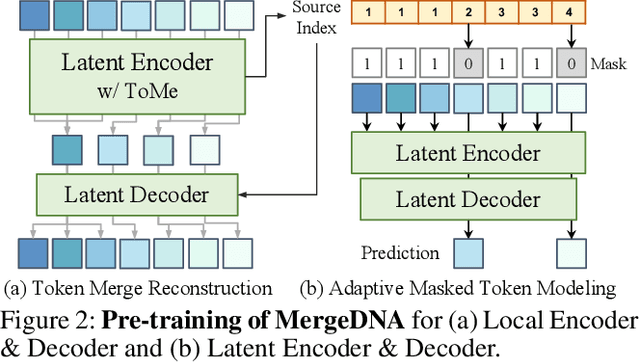
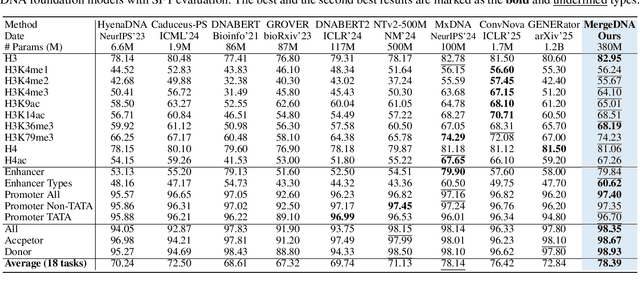
Modeling genomic sequences faces two unsolved challenges: the information density varies widely across different regions, while there is no clearly defined minimum vocabulary unit. Relying on either four primitive bases or independently designed DNA tokenizers, existing approaches with naive masked language modeling pre-training often fail to adapt to the varying complexities of genomic sequences. Leveraging Token Merging techniques, this paper introduces a hierarchical architecture that jointly optimizes a dynamic genomic tokenizer and latent Transformers with context-aware pre-training tasks. As for network structures, the tokenization module automatically chunks adjacent bases into words by stacking multiple layers of the differentiable token merging blocks with local-window constraints, then a Latent Encoder captures the global context of these merged words by full-attention blocks. Symmetrically employing a Latent Decoder and a Local Decoder, MergeDNA learns with two pre-training tasks: Merged Token Reconstruction simultaneously trains the dynamic tokenization module and adaptively filters important tokens, while Adaptive Masked Token Modeling learns to predict these filtered tokens to capture informative contents. Extensive experiments show that MergeDNA achieves superior performance on three popular DNA benchmarks and several multi-omics tasks with fine-tuning or zero-shot evaluation, outperforming typical tokenization methods and large-scale DNA foundation models.
BSCodec: A Band-Split Neural Codec for High-Quality Universal Audio Reconstruction
Nov 08, 2025



Neural audio codecs have recently enabled high-fidelity reconstruction at high compression rates, especially for speech. However, speech and non-speech audio exhibit fundamentally different spectral characteristics: speech energy concentrates in narrow bands around pitch harmonics (80-400 Hz), while non-speech audio requires faithful reproduction across the full spectrum, particularly preserving higher frequencies that define timbre and texture. This poses a challenge: speech-optimized neural codecs suffer degradation on music or sound. Treating the full spectrum holistically is suboptimal: frequency bands have vastly different information density and perceptual importance by content type, yet full-band approaches apply uniform capacity across frequencies without accounting for these acoustic structures. To address this gap, we propose BSCodec (Band-Split Codec), a novel neural audio codec architecture that splits the spectral dimension into separate bands and compresses each band independently. Experimental results demonstrate that BSCodec achieves superior reconstruction over baselines across sound and music, while maintaining competitive quality in the speech domain, when trained on the same combined dataset of speech, music and sound. Downstream benchmark tasks further confirm that BSCodec shows strong potential for use in downstream applications.