 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing is Believing: Aligning Prompt Rewriting with Visual Anchors for Text-to-Image Generation
Jun 07, 2026Despite the impressive capabilities of text-to-image (T2I) models, an intent-generation gap often persists due to the brevity and ambiguity of user prompts. Existing approaches primarily polish the prompt for fluency and readability. However, the enhancement process still lacks visual grounding. As a result, the rewriter may over-infer missing details, causing an intent-generation gap. To address this limitation, we propose FaithRewriter, a novel prompt-enhancement framework for T2I generation. Specifically, FaithRewriter first leverages a multimodal MLLM to generate an image from the original prompt as an intermediate visual cue. This cue is then combined with the prompt and fed into a large-scale LLM to produce visually grounded augmentations that better reflect how the intended content should appear in images. Finally, these augmentations are distilled into a small-scale LLM for efficient deployment, enhancing its ability to generate effective T2I prompts. Experiments show that FaithRewriter yields prompts that are more faithful to the user intent and more visually plausible than strong baselines, helping narrow the intent-generation gap.
The Cases LJP Never Sees: Prosecution Decision Prediction for More Complete Criminal Liability Assessment
May 27, 2026Legal Judgment Prediction (LJP) has become a core benchmark for evaluating AI in the criminal legal domain, but it only sees criminal cases that have already passed prosecutorial review and been formally indicted. As a result, LJP leaves a substantial blind spot in assessing criminal liability, overlooking cases involving insufficient evidence, no criminal liability, or guilt exempted from punishment. To fill this gap, we propose \textbf{Prosecution Decision Prediction (PDP)}, the first Legal AI task built around prosecutorial review, which classifies each case into prosecution or one of three non-prosecution decisions and reflects legal AI's capabilities in evidence evaluation, legal subsumption, and value-based discretion. We further construct \textbf{PDP-Bench}, a benchmark of 4{,}630 real Chinese prosecutorial decisions spanning 190 charges. Extensive experiments show that state-of-the-art LLMs perform substantially worse on PDP than on LJP and that mainstream enhancement routes fail to close the gap. Moreover, controlled RLVR interventions show that simple outcome rewards fail to produce generalizable PDP discrimination.
Distinguishing Right from Wrong in Debates: Attribution Analysis of Chinese Harmful Memes
May 23, 2026Research on harmful meme detection has garnered significant attention, resulting in the development of numerous datasets and methods. However, progress in detecting Chinese harmful memes lags considerably, primarily due to two challenges: first, accurately assessing a meme's harmfulness depends heavily on understanding deep cultural context; second, many memes are semantically ambiguous, making harmfulness highly subjective. To address these issues, we focus on the interpretable detection of Chinese harmful memes by constructing the first Chinese harmful meme explanation dataset, Ex-ToxiCN-MM. This dataset offers opposing interpretations, categorized as "harmful" and "non-harmful", for each meme, aiming to rigorously evaluate a model's ability to discern and comprehend ambiguous, culturally grounded content. We built a specialized knowledge base of Chinese cultural concepts and offensive vocabulary to supply models with essential prior knowledge (C-HarmKB). To address the ambiguity and lack of background knowledge in meme attribution, we have developed a comprehensive attribution analysis framework, RIKE, which includes an Attribution Knowledge Enhancement module (AKE) and a Relative Intent Reasoning module (RIR). Extensive quantitative and qualitative experiments demonstrate that our method outperforms mainstream baseline models across multiple metrics in the task of attributing harmful memes in Chinese. The code, Ex-ToxiCN-MM dataset, and Chinese Harmful Semantic Knowledge Base (C-HarmKB) involved in this study have been open-sourced at https://github.com/wimiw123/Ex-ToxiCN-MM
Harder to Defend: Towards Chinese Toxicity Attacks via Implicit Enhancement and Obfuscation Rewriting
May 21, 2026Large language models (LLMs) require robust toxicity evaluation beyond explicit wording. This setting remains underexplored in Chinese, where toxicity may combine semantic indirectness with surface obfuscation. We introduce Chinese Implicit Toxicity Attack (CITA), a controlled red-team evaluation and defense-data generation framework, not a deployable evasion tool. CITA uses three stages: (i) Harmful Intent Learning, (ii) Implicit Toxicity Enhancement, and (iii) Obfuscation Variant Rewriting, to preserve harmful intent, increase implicitness, and add controlled surface variants. On CITA-generated evaluation samples, the seven tested detectors exhibit substantial missed-detection risks, reaching an average ASR of 69.48%; human evaluation further confirms preserved harmfulness and increased implicitness/evasiveness. As a downstream defense application, we fine-tune a Chinese Implicit Toxicity Defense model (CITD) with CITA-generated red-team data, showing that such data can improve robustness through additional training.
Aligning LLM Uncertainty with Human Disagreement in Subjectivity Analysis
May 11, 2026Large language models for subjectivity analysis are typically trained with aggregated labels, which compress variations in human judgment into a single supervision signal. This paradigm overlooks the intrinsic uncertainty of low-agreement samples and often induces overconfident predictions, undermining reliability and generalization in complex subjective settings. In this work, we advocate uncertainty-aware subjectivity analysis, where models are expected to make predictions while expressing uncertainty that reflects human disagreement. To operationalize this perspective, we propose a two-phase Disagreement Perception and Uncertainty Alignment (DPUA) framework. Specifically, DPUA jointly models label prediction, rationale generation, and uncertainty expression under an uncertainty-aware setting. In the disagreement perception phase, adaptive decoupled learning enhances the model's sensitivity to disagreement-related cues while preserving task performance. In the uncertainty alignment phase, GRPO-based reward optimization further improves uncertainty-aware reasoning and aligns the model's confidence expression with the human disagreement distribution. Experiments on three subjectivity analysis tasks show that DPUA preserves task performance while better aligning model uncertainty with human disagreement, mitigating overconfidence on boundary samples, and improving out-of-distribution generalization.
Split CNN Inference on Networked Microcontrollers
May 10, 2026Running deep neural networks on microcontroller units (MCUs) is severely constrained by limited memory resources. While TinyML techniques reduce model size and computation, they often fail in practice due to excessive peak Random Access Memory (RAM) usage during inference, dominated by intermediate activations. As a result, many models remain infeasible on standalone MCUs. In this work, we present a fine-grained split inference system for networked MCUs that enables collaborative inference of Convolutional Neural Networks (CNN) models across multiple devices. Our key insight is that breaking the memory bottleneck requires splitting inference at sub-layer granularity rather than at layer boundaries. We reinterpret pre-trained models to enable kernel-wise and neuron-wise partitioning, and distribute both model parameters and intermediate activations across multiple MCUs. A lightweight, resource-aware coordinator orchestrates the inference across MCU devices with heterogeneous resources. We implement the proposed system on a real testbed and evaluate it on up to 8 MCUs using MobileNetV2, a representative CNN model. Our experimental results show that CNN models infeasible on a single MCU can be executed across networked MCUs, reducing the per-MCU peak RAM usage while maintaining the practical end-to-end inference latency. All the source code of this work can be found here: https://github.com/shashsuresh/split-inference-on-MCUs.
* 10 pages
ARGUS: Policy-Adaptive Ad Governance via Evolving Reinforcement with Adversarial Umpiring
May 04, 2026Online advertising governance faces significant challenges due to the non-stationary nature of regulatory policies, where emerging mandates (e.g., restrictions on education or aesthetic anxiety) create severe label inconsistencies and reasoning ambiguities in historical datasets. In this paper, we propose ARGUS, a policy-adaptive governance system that enables evolving reinforcement through multi-agent adversarial umpiring. ARGUS addresses the sparsity of new policy data by employing a three-stage framework: (1) Policy Seeding for initial perception; (2) Adversarial Label Rectification, which utilizes a ``Prosecutor-Defender-Umpire'' architecture to resolve conflicts between stale labels and new mandates; and (3) Latent Knowledge Discovery, which employs a tripartite dialectical discussion to unearth sophisticated, ``gray-area'' violations. By leveraging RAG-enhanced policy knowledge and Chain-of-Thought synthesis as dynamic rewards for reinforcement learning, ARGUS synchronizes its reasoning pathways with evolving regulations. Extensive experiments on both industrial and public datasets demonstrate that ARGUS significantly outperforms traditional fine-tuning baselines, achieving superior policy-adaptive learning with minimal gold data.
Multi-Agent VLMs Guided Self-Training with PNU Loss for Low-Resource Offensive Content Detection
Nov 14, 2025



Accurate detection of offensive content on social media demands high-quality labeled data; however, such data is often scarce due to the low prevalence of offensive instances and the high cost of manual annotation. To address this low-resource challenge, we propose a self-training framework that leverages abundant unlabeled data through collaborative pseudo-labeling. Starting with a lightweight classifier trained on limited labeled data, our method iteratively assigns pseudo-labels to unlabeled instances with the support of Multi-Agent Vision-Language Models (MA-VLMs). Un-labeled data on which the classifier and MA-VLMs agree are designated as the Agreed-Unknown set, while conflicting samples form the Disagreed-Unknown set. To enhance label reliability, MA-VLMs simulate dual perspectives, moderator and user, capturing both regulatory and subjective viewpoints. The classifier is optimized using a novel Positive-Negative-Unlabeled (PNU) loss, which jointly exploits labeled, Agreed-Unknown, and Disagreed-Unknown data while mitigating pseudo-label noise. Experiments on benchmark datasets demonstrate that our framework substantially outperforms baselines under limited supervision and approaches the performance of large-scale models
Contextualized Token Discrimination for Speech Search Query Correction
Sep 04, 2025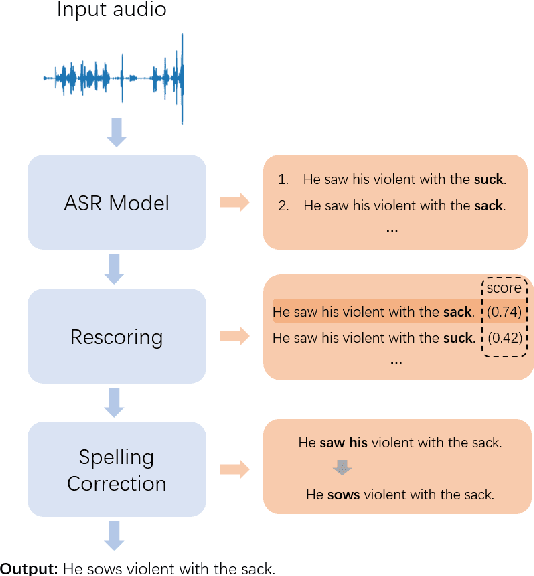



Query spelling correction is an important function of modern search engines since it effectively helps users express their intentions clearly. With the growing popularity of speech search driven by Automated Speech Recognition (ASR) systems, this paper introduces a novel method named Contextualized Token Discrimination (CTD) to conduct effective speech query correction. In CTD, we first employ BERT to generate token-level contextualized representations and then construct a composition layer to enhance semantic information. Finally, we produce the correct query according to the aggregated token representation, correcting the incorrect tokens by comparing the original token representations and the contextualized representations. Extensive experiments demonstrate the superior performance of our proposed method across all metrics, and we further present a new benchmark dataset with erroneous ASR transcriptions to offer comprehensive evaluations for audio query correction.
VIS-Shepherd: Constructing Critic for LLM-based Data Visualization Generation
Jun 16, 2025Data visualization generation using Large Language Models (LLMs) has shown promising results but often produces suboptimal visualizations that require human intervention for improvement. In this work, we introduce VIS-Shepherd, a specialized Multimodal Large Language Model (MLLM)-based critic to evaluate and provide feedback for LLM-generated data visualizations. At the core of our approach is a framework to construct a high-quality visualization critique dataset, where we collect human-created visualization instances, synthesize corresponding LLM-generated instances, and construct high-quality critiques. We conduct both model-based automatic evaluation and human preference studies to evaluate the effectiveness of our approach. Our experiments show that even small (7B parameters) open-source MLLM models achieve substantial performance gains by leveraging our high-quality visualization critique dataset, reaching levels comparable to much larger open-source or even proprietary models. Our work demonstrates significant potential for MLLM-based automated visualization critique and indicates promising directions for enhancing LLM-based data visualization generation. Our project page: https://github.com/bopan3/VIS-Shepherd.