 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM$^3$Exam: Benchmarking Multimodal Memory for Realistic User-Agent Interactions
Jun 05, 2026Language agents are increasingly deployed over accumulating multimodal information, yet existing benchmarks assume a human-human form with sparse visuals and straightforward content, evaluating neither reasoning over authentic multimodal file interaction nor the interpretation of concealed user information. We therefore introduce M$^3$Exam, a query-centric multimodal conversational memory benchmark built on realistic user-agent interaction, with multi-dimensional evaluation spanning cross-modal grounding and implicit information inference. Benchmarking MLLMs and memory systems reveals persistent gaps in cross-modal grounding, cross session reasoning, and the efficiency cost of accumulating multimodal context. We further propose M$^3$Proctor, a multimodal memory method that detects query modality bias and consumes raw visual sources only on demand, improving accuracy by 13% while cutting index-construction time and retrieved tokens by over 70%.
Cardinality Estimation for High Dimensional Similarity Queries with Adaptive Bucket Probing
Apr 06, 2026In this work, we address the problem of cardinality estimation for similarity search in high-dimensional spaces. Our goal is to design a framework that is lightweight, easy to construct, and capable of providing accurate estimates with satisfying online efficiency. We leverage locality-sensitive hashing (LSH) to partition the vector space while preserving distance proximity. Building on this, we adopt the principles of classical multi-probe LSH to adaptively explore neighboring buckets, accounting for distance thresholds of varying magnitudes. To improve online efficiency, we employ progressive sampling to reduce the number of distance computations and utilize asymmetric distance computation in product quantization to accelerate distance calculations in high-dimensional spaces. In addition to handling static datasets, our framework includes updating algorithm designed to efficiently support large-scale dynamic scenarios of data updates.Experiments demonstrate that our methods can accurately estimate the cardinality of similarity queries, yielding satisfying efficiency.
Memory in the LLM Era: Modular Architectures and Strategies in a Unified Framework
Apr 02, 2026Memory emerges as the core module in the large language model (LLM)-based agents for long-horizon complex tasks (e.g., multi-turn dialogue, game playing, scientific discovery), where memory can enable knowledge accumulation, iterative reasoning and self-evolution. A number of memory methods have been proposed in the literature. However, these methods have not been systematically and comprehensively compared under the same experimental settings. In this paper, we first summarize a unified framework that incorporates all the existing agent memory methods from a high-level perspective. We then extensively compare representative agent memory methods on two well-known benchmarks and examine the effectiveness of all methods, providing a thorough analysis of those methods. As a byproduct of our experimental analysis, we also design a new memory method by exploiting modules in the existing methods, which outperforms the state-of-the-art methods. Finally, based on these findings, we offer promising future research opportunities. We believe that a deeper understanding of the behavior of existing methods can provide valuable new insights for future research.
Breaking the Static Graph: Context-Aware Traversal for Robust Retrieval-Augmented Generation
Feb 02, 2026Recent advances in Retrieval-Augmented Generation (RAG) have shifted from simple vector similarity to structure-aware approaches like HippoRAG, which leverage Knowledge Graphs (KGs) and Personalized PageRank (PPR) to capture multi-hop dependencies. However, these methods suffer from a "Static Graph Fallacy": they rely on fixed transition probabilities determined during indexing. This rigidity ignores the query-dependent nature of edge relevance, causing semantic drift where random walks are diverted into high-degree "hub" nodes before reaching critical downstream evidence. Consequently, models often achieve high partial recall but fail to retrieve the complete evidence chain required for multi-hop queries. To address this, we propose CatRAG, Context-Aware Traversal for robust RAG, a framework that builds on the HippoRAG 2 architecture and transforms the static KG into a query-adaptive navigation structure. We introduce a multi-faceted framework to steer the random walk: (1) Symbolic Anchoring, which injects weak entity constraints to regularize the random walk; (2) Query-Aware Dynamic Edge Weighting, which dynamically modulates graph structure, to prune irrelevant paths while amplifying those aligned with the query's intent; and (3) Key-Fact Passage Weight Enhancement, a cost-efficient bias that structurally anchors the random walk to likely evidence. Experiments across four multi-hop benchmarks demonstrate that CatRAG consistently outperforms state of the art baselines. Our analysis reveals that while standard Recall metrics show modest gains, CatRAG achieves substantial improvements in reasoning completeness, the capacity to recover the entire evidence path without gaps. These results reveal that our approach effectively bridges the gap between retrieving partial context and enabling fully grounded reasoning. Resources are available at https://github.com/kwunhang/CatRAG.
Contextualized Token Discrimination for Speech Search Query Correction
Sep 04, 2025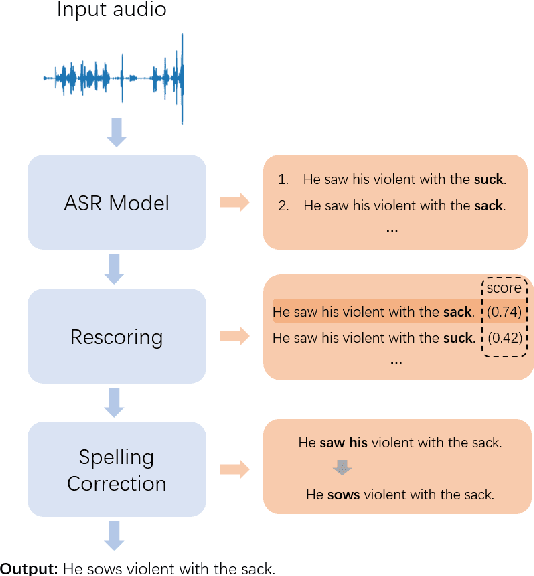



Query spelling correction is an important function of modern search engines since it effectively helps users express their intentions clearly. With the growing popularity of speech search driven by Automated Speech Recognition (ASR) systems, this paper introduces a novel method named Contextualized Token Discrimination (CTD) to conduct effective speech query correction. In CTD, we first employ BERT to generate token-level contextualized representations and then construct a composition layer to enhance semantic information. Finally, we produce the correct query according to the aggregated token representation, correcting the incorrect tokens by comparing the original token representations and the contextualized representations. Extensive experiments demonstrate the superior performance of our proposed method across all metrics, and we further present a new benchmark dataset with erroneous ASR transcriptions to offer comprehensive evaluations for audio query correction.
EraRAG: Efficient and Incremental Retrieval Augmented Generation for Growing Corpora
Jun 26, 2025Graph-based Retrieval-Augmented Generation (Graph-RAG) enhances large language models (LLMs) by structuring retrieval over an external corpus. However, existing approaches typically assume a static corpus, requiring expensive full-graph reconstruction whenever new documents arrive, limiting their scalability in dynamic, evolving environments. To address these limitations, we introduce EraRAG, a novel multi-layered Graph-RAG framework that supports efficient and scalable dynamic updates. Our method leverages hyperplane-based Locality-Sensitive Hashing (LSH) to partition and organize the original corpus into hierarchical graph structures, enabling efficient and localized insertions of new data without disrupting the existing topology. The design eliminates the need for retraining or costly recomputation while preserving high retrieval accuracy and low latency. Experiments on large-scale benchmarks demonstrate that EraRag achieves up to an order of magnitude reduction in update time and token consumption compared to existing Graph-RAG systems, while providing superior accuracy performance. This work offers a practical path forward for RAG systems that must operate over continually growing corpora, bridging the gap between retrieval efficiency and adaptability. Our code and data are available at https://github.com/EverM0re/EraRAG-Official.