 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Heterogeneous Language Model Optimization for Hybrid Automatic Speech Recognition
Mar 05, 2026Training automatic speech recognition (ASR) models increasingly relies on decentralized federated learning to ensure data privacy and accessibility, producing multiple local models that require effective merging. In hybrid ASR systems, while acoustic models can be merged using established methods, the language model (LM) for rescoring the N-best speech recognition list faces challenges due to the heterogeneity of non-neural n-gram models and neural network models. This paper proposes a heterogeneous LM optimization task and introduces a match-and-merge paradigm with two algorithms: the Genetic Match-and-Merge Algorithm (GMMA), using genetic operations to evolve and pair LMs, and the Reinforced Match-and-Merge Algorithm (RMMA), leveraging reinforcement learning for efficient convergence. Experiments on seven OpenSLR datasets show RMMA achieves the lowest average Character Error Rate and better generalization than baselines, converging up to seven times faster than GMMA, highlighting the paradigm's potential for scalable, privacy-preserving ASR systems.
CiteLLM: An Agentic Platform for Trustworthy Scientific Reference Discovery
Feb 26, 2026Large language models (LLMs) have created new opportunities to enhance the efficiency of scholarly activities; however, challenges persist in the ethical deployment of AI assistance, including (1) the trustworthiness of AI-generated content, (2) preservation of academic integrity and intellectual property, and (3) protection of information privacy. In this work, we present CiteLLM, a specialized agentic platform designed to enable trustworthy reference discovery for grounding author-drafted claims and statements. The system introduces a novel interaction paradigm by embedding LLM utilities directly within the LaTeX editor environment, ensuring a seamless user experience and no data transmission outside the local system. To guarantee hallucination-free references, we employ dynamic discipline-aware routing to retrieve candidates exclusively from trusted web-based academic repositories, while leveraging LLMs solely for generating context-aware search queries, ranking candidates by relevance, and validating and explaining support through paragraph-level semantic matching and an integrated chatbot. Evaluation results demonstrate the superior performance of the proposed system in returning valid and highly usable references.
RAL2M: Retrieval Augmented Learning-To-Match Against Hallucination in Compliance-Guaranteed Service Systems
Jan 06, 2026Hallucination is a major concern in LLM-driven service systems, necessitating explicit knowledge grounding for compliance-guaranteed responses. In this paper, we introduce Retrieval-Augmented Learning-to-Match (RAL2M), a novel framework that eliminates generation hallucination by repositioning LLMs as query-response matching judges within a retrieval-based system, providing a robust alternative to purely generative approaches. To further mitigate judgment hallucination, we propose a query-adaptive latent ensemble strategy that explicitly models heterogeneous model competence and interdependencies among LLMs, deriving a calibrated consensus decision. Extensive experiments on large-scale benchmarks demonstrate that the proposed method effectively leverages the "wisdom of the crowd" and significantly outperforms strong baselines. Finally, we discuss best practices and promising directions for further exploiting latent representations in future work.
Contextualized Token Discrimination for Speech Search Query Correction
Sep 04, 2025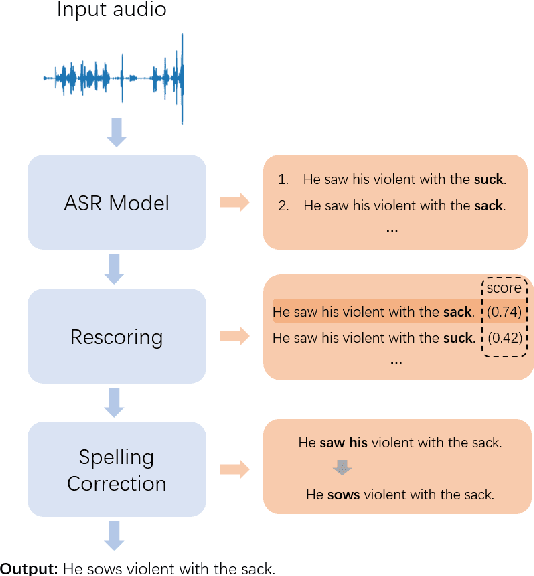



Query spelling correction is an important function of modern search engines since it effectively helps users express their intentions clearly. With the growing popularity of speech search driven by Automated Speech Recognition (ASR) systems, this paper introduces a novel method named Contextualized Token Discrimination (CTD) to conduct effective speech query correction. In CTD, we first employ BERT to generate token-level contextualized representations and then construct a composition layer to enhance semantic information. Finally, we produce the correct query according to the aggregated token representation, correcting the incorrect tokens by comparing the original token representations and the contextualized representations. Extensive experiments demonstrate the superior performance of our proposed method across all metrics, and we further present a new benchmark dataset with erroneous ASR transcriptions to offer comprehensive evaluations for audio query correction.