 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Cases LJP Never Sees: Prosecution Decision Prediction for More Complete Criminal Liability Assessment
May 27, 2026Legal Judgment Prediction (LJP) has become a core benchmark for evaluating AI in the criminal legal domain, but it only sees criminal cases that have already passed prosecutorial review and been formally indicted. As a result, LJP leaves a substantial blind spot in assessing criminal liability, overlooking cases involving insufficient evidence, no criminal liability, or guilt exempted from punishment. To fill this gap, we propose \textbf{Prosecution Decision Prediction (PDP)}, the first Legal AI task built around prosecutorial review, which classifies each case into prosecution or one of three non-prosecution decisions and reflects legal AI's capabilities in evidence evaluation, legal subsumption, and value-based discretion. We further construct \textbf{PDP-Bench}, a benchmark of 4{,}630 real Chinese prosecutorial decisions spanning 190 charges. Extensive experiments show that state-of-the-art LLMs perform substantially worse on PDP than on LJP and that mainstream enhancement routes fail to close the gap. Moreover, controlled RLVR interventions show that simple outcome rewards fail to produce generalizable PDP discrimination.
TriDeliver: Cooperative Air-Ground Instant Delivery with UAVs, Couriers, and Crowdsourced Ground Vehicles
Apr 14, 2026Instant delivery, shipping items before critical deadlines, is essential in daily life. While multiple delivery agents, such as couriers, Unmanned Aerial Vehicles (UAVs), and crowdsourced agents, have been widely employed, each of them faces inherent limitations (e.g., low efficiency/labor shortages, flight control, and dynamic capabilities, respectively), preventing them from meeting the surging demands alone. This paper proposes TriDeliver, the first hierarchical cooperative framework, integrating human couriers, UAVs, and crowdsourced ground vehicles (GVs) for efficient instant delivery. To obtain the initial scheduling knowledge for GVs and UAVs as well as improve the cooperative delivery performance, we design a Transfer Learning (TL)-based algorithm to extract delivery knowledge from couriers' behavioral history and transfer their knowledge to UAVs and GVs with fine-tunings, which is then used to dispatch parcels for efficient delivery. Evaluated on one-month real-world trajectory and delivery datasets, it has been demonstrated that 1) by integrating couriers, UAVs, and crowdsourced GVs, TriDeliver reduces the delivery cost by $65.8\%$ versus state-of-the-art cooperative delivery by UAVs and couriers; 2) TriDeliver achieves further improvements in terms of delivery time ($-17.7\%$), delivery cost ($-9.8\%$), and impacts on original tasks of crowdsourced GVs ($-43.6\%$), even with the representation of the transferred knowledge by simple neural networks, respectively.
Aggregation Alignment for Federated Learning with Mixture-of-Experts under Data Heterogeneity
Mar 22, 2026Large language models (LLMs) increasingly adopt Mixture-of-Experts (MoE) architectures to scale model capacity while reducing computation. Fine-tuning these MoE-based LLMs often requires access to distributed and privacy-sensitive data, making centralized fine-tuning impractical. Federated learning (FL) therefore provides a paradigm to collaboratively fine-tune MoE-based LLMs, enabling each client to integrate diverse knowledge without compromising data privacy. However, the integration of MoE-based LLM fine-tuning into FL encounters two critical aggregation challenges due to inherent data heterogeneity across clients: (i) divergent local data distributions drive clients to develop distinct gating preference for localized expert selection, causing direct parameter aggregation to produce a ``one-size-fits-none'' global gating network, and (ii) same-indexed experts develop disparate semantic roles across clients, leading to expert semantic blurring and the degradation of expert specialization. To address these challenges, we propose FedAlign-MoE, a federated aggregation alignment framework that jointly enforces routing consistency and expert semantic alignment. Specifically, FedAlign-MoE aggregates gating behaviors by aligning routing distributions through consistency weighting and optimizes local gating networks through distribution regularization, maintaining cross-client stability without overriding discriminative local preferences. Meanwhile, FedAlign-MoE explicitly quantifies semantic consistency among same-indexed experts across clients and selectively aggregates updates from semantically aligned clients, ensuring stable and specialized functional roles for global experts. Extensive experiments demonstrate that FedAlign-MoE outperforms state-of-the-art benchmarks, achieving faster convergence and superior accuracy in non-IID federated environments.
Causal Inference for Time series Analysis: Problems, Methods and Evaluation
Feb 11, 2021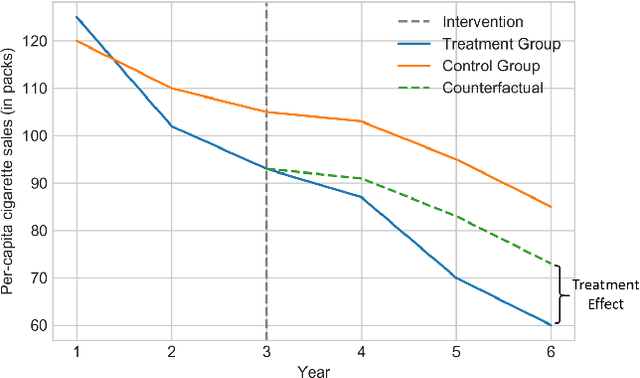

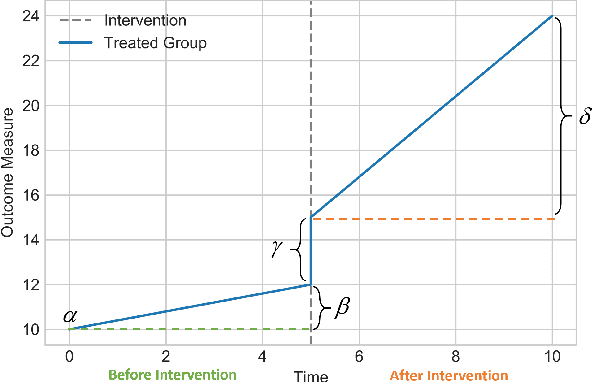
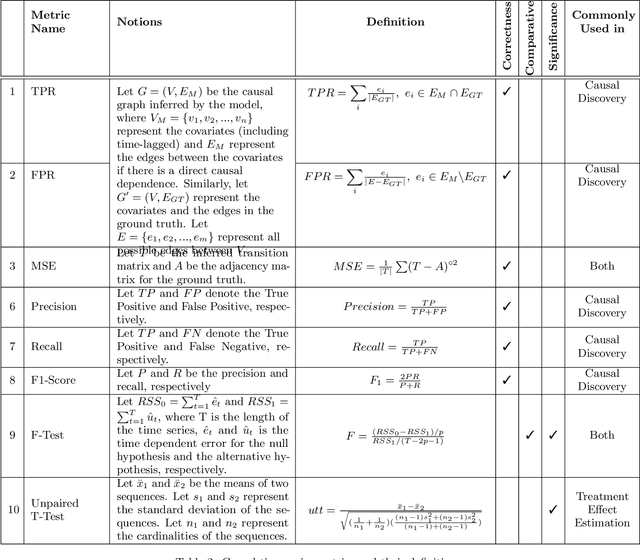
Time series data is a collection of chronological observations which is generated by several domains such as medical and financial fields. Over the years, different tasks such as classification, forecasting, and clustering have been proposed to analyze this type of data. Time series data has been also used to study the effect of interventions over time. Moreover, in many fields of science, learning the causal structure of dynamic systems and time series data is considered an interesting task which plays an important role in scientific discoveries. Estimating the effect of an intervention and identifying the causal relations from the data can be performed via causal inference. Existing surveys on time series discuss traditional tasks such as classification and forecasting or explain the details of the approaches proposed to solve a specific task. In this paper, we focus on two causal inference tasks, i.e., treatment effect estimation and causal discovery for time series data, and provide a comprehensive review of the approaches in each task. Furthermore, we curate a list of commonly used evaluation metrics and datasets for each task and provide in-depth insight. These metrics and datasets can serve as benchmarks for research in the field.