 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRaw2Drive: Reinforcement Learning with Aligned World Models for End-to-End Autonomous Driving (in CARLA v2)
May 22, 2025Reinforcement Learning (RL) can mitigate the causal confusion and distribution shift inherent to imitation learning (IL). However, applying RL to end-to-end autonomous driving (E2E-AD) remains an open problem for its training difficulty, and IL is still the mainstream paradigm in both academia and industry. Recently Model-based Reinforcement Learning (MBRL) have demonstrated promising results in neural planning; however, these methods typically require privileged information as input rather than raw sensor data. We fill this gap by designing Raw2Drive, a dual-stream MBRL approach. Initially, we efficiently train an auxiliary privileged world model paired with a neural planner that uses privileged information as input. Subsequently, we introduce a raw sensor world model trained via our proposed Guidance Mechanism, which ensures consistency between the raw sensor world model and the privileged world model during rollouts. Finally, the raw sensor world model combines the prior knowledge embedded in the heads of the privileged world model to effectively guide the training of the raw sensor policy. Raw2Drive is so far the only RL based end-to-end method on CARLA Leaderboard 2.0, and Bench2Drive and it achieves state-of-the-art performance.
DriveMoE: Mixture-of-Experts for Vision-Language-Action Model in End-to-End Autonomous Driving
May 22, 2025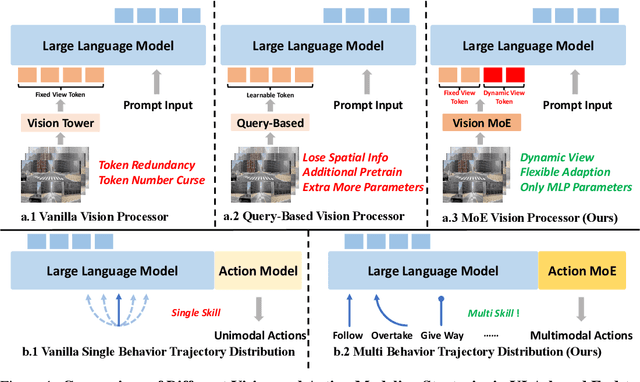
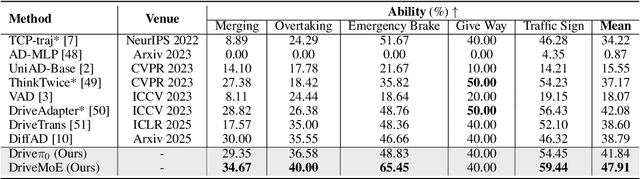
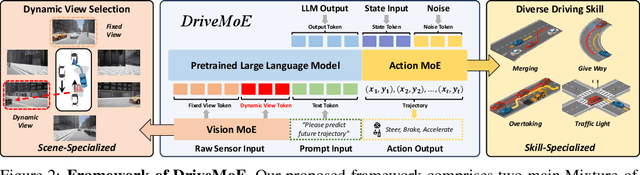
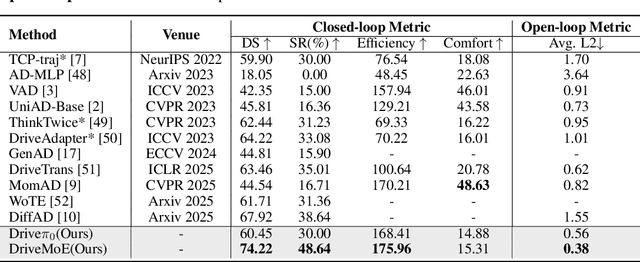
End-to-end autonomous driving (E2E-AD) demands effective processing of multi-view sensory data and robust handling of diverse and complex driving scenarios, particularly rare maneuvers such as aggressive turns. Recent success of Mixture-of-Experts (MoE) architecture in Large Language Models (LLMs) demonstrates that specialization of parameters enables strong scalability. In this work, we propose DriveMoE, a novel MoE-based E2E-AD framework, with a Scene-Specialized Vision MoE and a Skill-Specialized Action MoE. DriveMoE is built upon our $\pi_0$ Vision-Language-Action (VLA) baseline (originally from the embodied AI field), called Drive-$\pi_0$. Specifically, we add Vision MoE to Drive-$\pi_0$ by training a router to select relevant cameras according to the driving context dynamically. This design mirrors human driving cognition, where drivers selectively attend to crucial visual cues rather than exhaustively processing all visual information. In addition, we add Action MoE by training another router to activate specialized expert modules for different driving behaviors. Through explicit behavioral specialization, DriveMoE is able to handle diverse scenarios without suffering from modes averaging like existing models. In Bench2Drive closed-loop evaluation experiments, DriveMoE achieves state-of-the-art (SOTA) performance, demonstrating the effectiveness of combining vision and action MoE in autonomous driving tasks. We will release our code and models of DriveMoE and Drive-$\pi_0$.
New Evidence of the Two-Phase Learning Dynamics of Neural Networks
May 20, 2025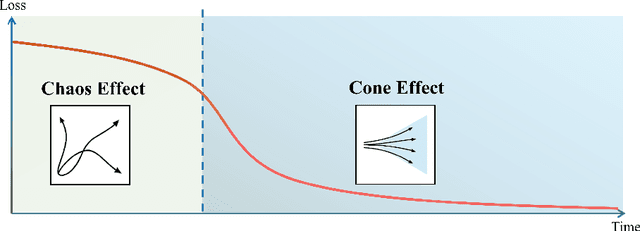
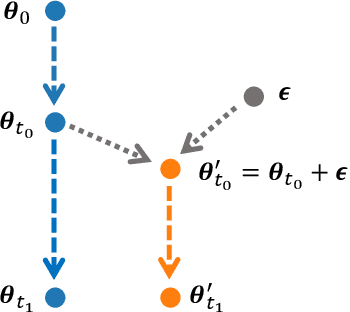
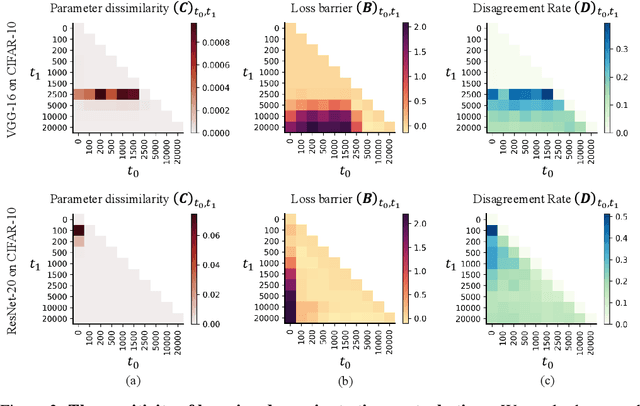
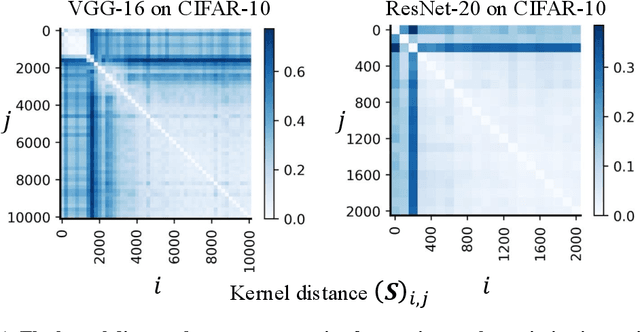
Understanding how deep neural networks learn remains a fundamental challenge in modern machine learning. A growing body of evidence suggests that training dynamics undergo a distinct phase transition, yet our understanding of this transition is still incomplete. In this paper, we introduce an interval-wise perspective that compares network states across a time window, revealing two new phenomena that illuminate the two-phase nature of deep learning. i) \textbf{The Chaos Effect.} By injecting an imperceptibly small parameter perturbation at various stages, we show that the response of the network to the perturbation exhibits a transition from chaotic to stable, suggesting there is an early critical period where the network is highly sensitive to initial conditions; ii) \textbf{The Cone Effect.} Tracking the evolution of the empirical Neural Tangent Kernel (eNTK), we find that after this transition point the model's functional trajectory is confined to a narrow cone-shaped subset: while the kernel continues to change, it gets trapped into a tight angular region. Together, these effects provide a structural, dynamical view of how deep networks transition from sensitive exploration to stable refinement during training.
KO: Kinetics-inspired Neural Optimizer with PDE Simulation Approaches
May 20, 2025The design of optimization algorithms for neural networks remains a critical challenge, with most existing methods relying on heuristic adaptations of gradient-based approaches. This paper introduces KO (Kinetics-inspired Optimizer), a novel neural optimizer inspired by kinetic theory and partial differential equation (PDE) simulations. We reimagine the training dynamics of network parameters as the evolution of a particle system governed by kinetic principles, where parameter updates are simulated via a numerical scheme for the Boltzmann transport equation (BTE) that models stochastic particle collisions. This physics-driven approach inherently promotes parameter diversity during optimization, mitigating the phenomenon of parameter condensation, i.e. collapse of network parameters into low-dimensional subspaces, through mechanisms analogous to thermal diffusion in physical systems. We analyze this property, establishing both a mathematical proof and a physical interpretation. Extensive experiments on image classification (CIFAR-10/100, ImageNet) and text classification (IMDB, Snips) tasks demonstrate that KO consistently outperforms baseline optimizers (e.g., Adam, SGD), achieving accuracy improvements while computation cost remains comparable.
Beyond Theorem Proving: Formulation, Framework and Benchmark for Formal Problem-Solving
May 07, 2025As a seemingly self-explanatory task, problem-solving has been a significant component of science and engineering. However, a general yet concrete formulation of problem-solving itself is missing. With the recent development of AI-based problem-solving agents, the demand for process-level verifiability is rapidly increasing yet underexplored. To fill these gaps, we present a principled formulation of problem-solving as a deterministic Markov decision process; a novel framework, FPS (Formal Problem-Solving), which utilizes existing FTP (formal theorem proving) environments to perform process-verified problem-solving; and D-FPS (Deductive FPS), decoupling solving and answer verification for better human-alignment. The expressiveness, soundness and completeness of the frameworks are proven. We construct three benchmarks on problem-solving: FormalMath500, a formalization of a subset of the MATH500 benchmark; MiniF2F-Solving and PutnamBench-Solving, adaptations of FTP benchmarks MiniF2F and PutnamBench. For faithful, interpretable, and human-aligned evaluation, we propose RPE (Restricted Propositional Equivalence), a symbolic approach to determine the correctness of answers by formal verification. We evaluate four prevalent FTP models and two prompting methods as baselines, solving at most 23.77% of FormalMath500, 27.47% of MiniF2F-Solving, and 0.31% of PutnamBench-Solving.
Interleave-VLA: Enhancing Robot Manipulation with Interleaved Image-Text Instructions
May 04, 2025Vision-Language-Action (VLA) models have shown great promise for generalist robotic manipulation in the physical world. However, existing models are restricted to robot observations and text-only instructions, lacking the flexibility of interleaved multimodal instructions enabled by recent advances in foundation models in the digital world. In this paper, we present Interleave-VLA, the first framework capable of comprehending interleaved image-text instructions and directly generating continuous action sequences in the physical world. It offers a flexible, model-agnostic paradigm that extends state-of-the-art VLA models with minimal modifications and strong zero-shot generalization. A key challenge in realizing Interleave-VLA is the absence of large-scale interleaved embodied datasets. To bridge this gap, we develop an automatic pipeline that converts text-only instructions from real-world datasets in Open X-Embodiment into interleaved image-text instructions, resulting in the first large-scale real-world interleaved embodied dataset with 210k episodes. Through comprehensive evaluation on simulation benchmarks and real-robot experiments, we demonstrate that Interleave-VLA offers significant benefits: 1) it improves out-of-domain generalization to unseen objects by 2-3x compared to state-of-the-art baselines, 2) supports flexible task interfaces, and 3) handles diverse user-provided image instructions in a zero-shot manner, such as hand-drawn sketches. We further analyze the factors behind Interleave-VLA's strong zero-shot performance, showing that the interleaved paradigm effectively leverages heterogeneous datasets and diverse instruction images, including those from the Internet, which demonstrates strong potential for scaling up. Our model and dataset will be open-sourced.
TrustGeoGen: Scalable and Formal-Verified Data Engine for Trustworthy Multi-modal Geometric Problem Solving
Apr 22, 2025



Mathematical geometric problem solving (GPS) often requires effective integration of multimodal information and verifiable logical coherence. Despite the fast development of large language models in general problem solving, it remains unresolved regarding with both methodology and benchmarks, especially given the fact that exiting synthetic GPS benchmarks are often not self-verified and contain noise and self-contradicted information due to the illusion of LLMs. In this paper, we propose a scalable data engine called TrustGeoGen for problem generation, with formal verification to provide a principled benchmark, which we believe lays the foundation for the further development of methods for GPS. The engine synthesizes geometric data through four key innovations: 1) multimodal-aligned generation of diagrams, textual descriptions, and stepwise solutions; 2) formal verification ensuring rule-compliant reasoning paths; 3) a bootstrapping mechanism enabling complexity escalation via recursive state generation and 4) our devised GeoExplore series algorithms simultaneously produce multi-solution variants and self-reflective backtracking traces. By formal logical verification, TrustGeoGen produces GeoTrust-200K dataset with guaranteed modality integrity, along with GeoTrust-test testset. Experiments reveal the state-of-the-art models achieve only 49.17\% accuracy on GeoTrust-test, demonstrating its evaluation stringency. Crucially, models trained on GeoTrust achieve OOD generalization on GeoQA, significantly reducing logical inconsistencies relative to pseudo-label annotated by OpenAI-o1. Our code is available at https://github.com/Alpha-Innovator/TrustGeoGen
Envisioning Beyond the Pixels: Benchmarking Reasoning-Informed Visual Editing
Apr 03, 2025Large Multi-modality Models (LMMs) have made significant progress in visual understanding and generation, but they still face challenges in General Visual Editing, particularly in following complex instructions, preserving appearance consistency, and supporting flexible input formats. To address this gap, we introduce RISEBench, the first benchmark for evaluating Reasoning-Informed viSual Editing (RISE). RISEBench focuses on four key reasoning types: Temporal, Causal, Spatial, and Logical Reasoning. We curate high-quality test cases for each category and propose an evaluation framework that assesses Instruction Reasoning, Appearance Consistency, and Visual Plausibility with both human judges and an LMM-as-a-judge approach. Our experiments reveal that while GPT-4o-Native significantly outperforms other open-source and proprietary models, even this state-of-the-art system struggles with logical reasoning tasks, highlighting an area that remains underexplored. As an initial effort, RISEBench aims to provide foundational insights into reasoning-aware visual editing and to catalyze future research. Though still in its early stages, we are committed to continuously expanding and refining the benchmark to support more comprehensive, reliable, and scalable evaluations of next-generation multimodal systems. Our code and data will be released at https://github.com/PhoenixZ810/RISEBench.
All Patches Matter, More Patches Better: Enhance AI-Generated Image Detection via Panoptic Patch Learning
Apr 02, 2025The exponential growth of AI-generated images (AIGIs) underscores the urgent need for robust and generalizable detection methods. In this paper, we establish two key principles for AIGI detection through systematic analysis: \textbf{(1) All Patches Matter:} Unlike conventional image classification where discriminative features concentrate on object-centric regions, each patch in AIGIs inherently contains synthetic artifacts due to the uniform generation process, suggesting that every patch serves as an important artifact source for detection. \textbf{(2) More Patches Better}: Leveraging distributed artifacts across more patches improves detection robustness by capturing complementary forensic evidence and reducing over-reliance on specific patches, thereby enhancing robustness and generalization. However, our counterfactual analysis reveals an undesirable phenomenon: naively trained detectors often exhibit a \textbf{Few-Patch Bias}, discriminating between real and synthetic images based on minority patches. We identify \textbf{Lazy Learner} as the root cause: detectors preferentially learn conspicuous artifacts in limited patches while neglecting broader artifact distributions. To address this bias, we propose the \textbf{P}anoptic \textbf{P}atch \textbf{L}earning (PPL) framework, involving: (1) Random Patch Replacement that randomly substitutes synthetic patches with real counterparts to compel models to identify artifacts in underutilized regions, encouraging the broader use of more patches; (2) Patch-wise Contrastive Learning that enforces consistent discriminative capability across all patches, ensuring uniform utilization of all patches. Extensive experiments across two different settings on several benchmarks verify the effectiveness of our approach.
On the Cone Effect in the Learning Dynamics
Mar 20, 2025Understanding the learning dynamics of neural networks is a central topic in the deep learning community. In this paper, we take an empirical perspective to study the learning dynamics of neural networks in real-world settings. Specifically, we investigate the evolution process of the empirical Neural Tangent Kernel (eNTK) during training. Our key findings reveal a two-phase learning process: i) in Phase I, the eNTK evolves significantly, signaling the rich regime, and ii) in Phase II, the eNTK keeps evolving but is constrained in a narrow space, a phenomenon we term the cone effect. This two-phase framework builds on the hypothesis proposed by Fort et al. (2020), but we uniquely identify the cone effect in Phase II, demonstrating its significant performance advantages over fully linearized training.