 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld Engine: Towards the Era of Post-Training for Autonomous Driving
Jun 18, 2026Autonomous vehicles must operate safely in the real world, where errors can have severe consequences. Although modern end-to-end driving policies excel in routine scenarios, their reliability is limited by the scarcity of safety-critical ``long-tail'' events in real driving datasets. These rare interactions define the practical safety boundary of the learned policy, yet they are difficult to collect at scale in the real world. Here we show that this fundamental limitation can be addressed by post-training pre-trained driving models on synthesized high-stakes interactions. We introduce World Engine, a generative framework that reconstructs high-fidelity interactive environments from real-world logs and systematically extrapolates them into realistic safety-critical variations. This paradigm enables reinforcement-based post-training to align policies with safety constraints, circumventing the physical risks inherent in real-world exploration. On a public benchmark built on nuPlan, World Engine substantially reduces failures in rare safety-critical scenarios and yields significantly larger gains than scaling pre-training data alone. Furthermore, when deployed on a production-scale autonomous driving system, the resulting policy reduces simulated collisions and demonstrates measurable improvements in on-road testing, showing that post-training on synthesized, safety-critical interactions offers a scalable and effective pathway to safer autonomous driving. The full codebase suite, including training, is released to the public.
GuidedVLA: Specifying Task-Relevant Factors via Plug-and-Play Action Attention Specialization
May 12, 2026Vision-Language-Action (VLA) models aim for general robot learning by aligning action as a modality within powerful Vision-Language Models (VLMs). Existing VLAs rely on end-to-end supervision to implicitly enable the action decoding process to learn task-relevant features. However, without explicit guidance, these models often overfit to spurious correlations, such as visual shortcuts or environmental noise, limiting their generalization. In this paper, we introduce GuidedVLA, a framework designed to manually guide the action generation to focus on task-relevant factors. Our core insight is to treat the action decoder not as a monolithic learner, but as an assembly of functional components. Individual attention heads are supervised by manually defined auxiliary signals to capture distinct factors. As an initial study, we instantiate this paradigm with three specialized heads: object grounding, spatial geometry, and temporal skill logic. Across simulation and real-robot experiments, GuidedVLA improves success rates in both in-domain and out-of-domain settings compared to strong VLA baselines. Finally, we show that the quality of these specialized factors correlates positively with task performance and that our mechanism yields decoupled, high-quality features. Our results suggest that explicitly guiding action-decoder learning is a promising direction for building more robust and general VLA models.
Bench2Drive-VL: Benchmarks for Closed-Loop Autonomous Driving with Vision-Language Models
Apr 01, 2026With the rise of vision-language models (VLM), their application for autonomous driving (VLM4AD) has gained significant attention. Meanwhile, in autonomous driving, closed-loop evaluation has become widely recognized as a more reliable validation method than open-loop evaluation, as it can evaluate the performance of the model under cumulative errors and out-of-distribution inputs. However, existing VLM4AD benchmarks evaluate the model`s scene understanding ability under open-loop, i.e., via static question-answer (QA) dataset. This kind of evaluation fails to assess the VLMs performance under out-of-distribution states rarely appeared in the human collected datasets.To this end, we present Bench2Drive-VL, an extension of Bench2Drive that brings closed-loop evaluation to VLM-based driving, which introduces: (1) DriveCommenter, a closed-loop generator that automatically generates diverse, behavior-grounded question-answer pairs for all driving situations in CARLA,including severe off-route and off-road deviations previously unassessable in simulation. (2) A unified protocol and interface that allows modern VLMs to be directly plugged into the Bench2Drive closed-loop environment to compare with traditional agents. (3) A flexible reasoning and control framework, supporting multi-format visual inputs and configurable graph-based chain-of-thought execution. (4) A complete development ecosystem. Together, these components form a comprehensive closed-loop benchmark for VLM4AD. All codes and annotated datasets are open sourced.
DriveMamba: Task-Centric Scalable State Space Model for Efficient End-to-End Autonomous Driving
Feb 09, 2026Recent advances towards End-to-End Autonomous Driving (E2E-AD) have been often devoted on integrating modular designs into a unified framework for joint optimization e.g. UniAD, which follow a sequential paradigm (i.e., perception-prediction-planning) based on separable Transformer decoders and rely on dense BEV features to encode scene representations. However, such manual ordering design can inevitably cause information loss and cumulative errors, lacking flexible and diverse relation modeling among different modules and sensors. Meanwhile, insufficient training of image backbone and quadratic-complexity of attention mechanism also hinder the scalability and efficiency of E2E-AD system to handle spatiotemporal input. To this end, we propose DriveMamba, a Task-Centric Scalable paradigm for efficient E2E-AD, which integrates dynamic task relation modeling, implicit view correspondence learning and long-term temporal fusion into a single-stage Unified Mamba decoder. Specifically, both extracted image features and expected task outputs are converted into token-level sparse representations in advance, which are then sorted by their instantiated positions in 3D space. The linear-complexity operator enables efficient long-context sequential token modeling to capture task-related inter-dependencies simultaneously. Additionally, a bidirectional trajectory-guided "local-to-global" scan method is designed to preserve spatial locality from ego-perspective, thus facilitating the ego-planning. Extensive experiments conducted on nuScenes and Bench2Drive datasets demonstrate the superiority, generalizability and great efficiency of DriveMamba.
FlowRL: Matching Reward Distributions for LLM Reasoning
Sep 18, 2025We propose FlowRL: matching the full reward distribution via flow balancing instead of maximizing rewards in large language model (LLM) reinforcement learning (RL). Recent advanced reasoning models adopt reward-maximizing methods (\eg, PPO and GRPO), which tend to over-optimize dominant reward signals while neglecting less frequent but valid reasoning paths, thus reducing diversity. In contrast, we transform scalar rewards into a normalized target distribution using a learnable partition function, and then minimize the reverse KL divergence between the policy and the target distribution. We implement this idea as a flow-balanced optimization method that promotes diverse exploration and generalizable reasoning trajectories. We conduct experiments on math and code reasoning tasks: FlowRL achieves a significant average improvement of $10.0\%$ over GRPO and $5.1\%$ over PPO on math benchmarks, and performs consistently better on code reasoning tasks. These results highlight reward distribution-matching as a key step toward efficient exploration and diverse reasoning in LLM reinforcement learning.
DriveMoE: Mixture-of-Experts for Vision-Language-Action Model in End-to-End Autonomous Driving
May 22, 2025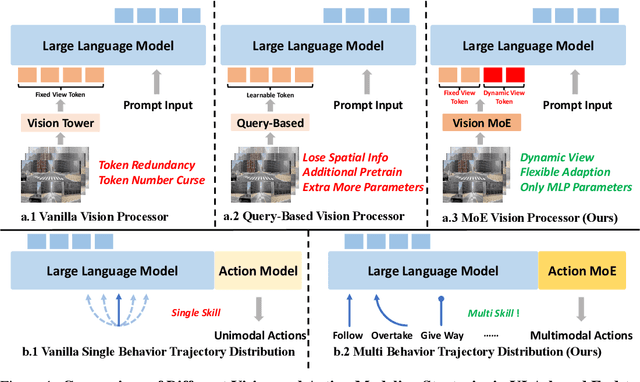
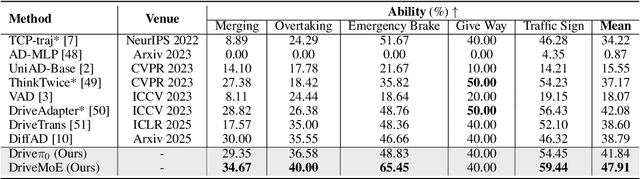
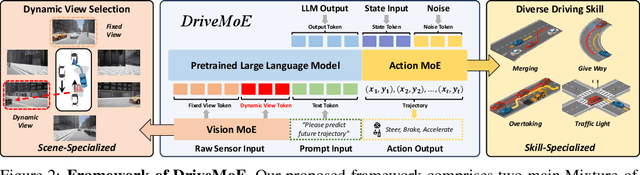
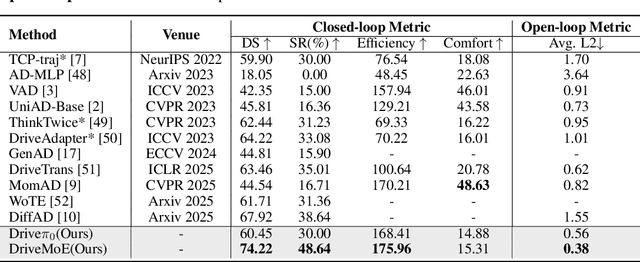
End-to-end autonomous driving (E2E-AD) demands effective processing of multi-view sensory data and robust handling of diverse and complex driving scenarios, particularly rare maneuvers such as aggressive turns. Recent success of Mixture-of-Experts (MoE) architecture in Large Language Models (LLMs) demonstrates that specialization of parameters enables strong scalability. In this work, we propose DriveMoE, a novel MoE-based E2E-AD framework, with a Scene-Specialized Vision MoE and a Skill-Specialized Action MoE. DriveMoE is built upon our $\pi_0$ Vision-Language-Action (VLA) baseline (originally from the embodied AI field), called Drive-$\pi_0$. Specifically, we add Vision MoE to Drive-$\pi_0$ by training a router to select relevant cameras according to the driving context dynamically. This design mirrors human driving cognition, where drivers selectively attend to crucial visual cues rather than exhaustively processing all visual information. In addition, we add Action MoE by training another router to activate specialized expert modules for different driving behaviors. Through explicit behavioral specialization, DriveMoE is able to handle diverse scenarios without suffering from modes averaging like existing models. In Bench2Drive closed-loop evaluation experiments, DriveMoE achieves state-of-the-art (SOTA) performance, demonstrating the effectiveness of combining vision and action MoE in autonomous driving tasks. We will release our code and models of DriveMoE and Drive-$\pi_0$.
Raw2Drive: Reinforcement Learning with Aligned World Models for End-to-End Autonomous Driving (in CARLA v2)
May 22, 2025Reinforcement Learning (RL) can mitigate the causal confusion and distribution shift inherent to imitation learning (IL). However, applying RL to end-to-end autonomous driving (E2E-AD) remains an open problem for its training difficulty, and IL is still the mainstream paradigm in both academia and industry. Recently Model-based Reinforcement Learning (MBRL) have demonstrated promising results in neural planning; however, these methods typically require privileged information as input rather than raw sensor data. We fill this gap by designing Raw2Drive, a dual-stream MBRL approach. Initially, we efficiently train an auxiliary privileged world model paired with a neural planner that uses privileged information as input. Subsequently, we introduce a raw sensor world model trained via our proposed Guidance Mechanism, which ensures consistency between the raw sensor world model and the privileged world model during rollouts. Finally, the raw sensor world model combines the prior knowledge embedded in the heads of the privileged world model to effectively guide the training of the raw sensor policy. Raw2Drive is so far the only RL based end-to-end method on CARLA Leaderboard 2.0, and Bench2Drive and it achieves state-of-the-art performance.
UniZero: Generalized and Efficient Planning with Scalable Latent World Models
Jun 15, 2024



Learning predictive world models is essential for enhancing the planning capabilities of reinforcement learning agents. Notably, the MuZero-style algorithms, based on the value equivalence principle and Monte Carlo Tree Search (MCTS), have achieved superhuman performance in various domains. However, in environments that require capturing long-term dependencies, MuZero's performance deteriorates rapidly. We identify that this is partially due to the \textit{entanglement} of latent representations with historical information, which results in incompatibility with the auxiliary self-supervised state regularization. To overcome this limitation, we present \textit{UniZero}, a novel approach that \textit{disentangles} latent states from implicit latent history using a transformer-based latent world model. By concurrently predicting latent dynamics and decision-oriented quantities conditioned on the learned latent history, UniZero enables joint optimization of the long-horizon world model and policy, facilitating broader and more efficient planning in latent space. We demonstrate that UniZero, even with single-frame inputs, matches or surpasses the performance of MuZero-style algorithms on the Atari 100k benchmark. Furthermore, it significantly outperforms prior baselines in benchmarks that require long-term memory. Lastly, we validate the effectiveness and scalability of our design choices through extensive ablation studies, visual analyses, and multi-task learning results. The code is available at \textcolor{magenta}{https://github.com/opendilab/LightZero}.
Bench2Drive: Towards Multi-Ability Benchmarking of Closed-Loop End-To-End Autonomous Driving
Jun 06, 2024



In an era marked by the rapid scaling of foundation models, autonomous driving technologies are approaching a transformative threshold where end-to-end autonomous driving (E2E-AD) emerges due to its potential of scaling up in the data-driven manner. However, existing E2E-AD methods are mostly evaluated under the open-loop log-replay manner with L2 errors and collision rate as metrics (e.g., in nuScenes), which could not fully reflect the driving performance of algorithms as recently acknowledged in the community. For those E2E-AD methods evaluated under the closed-loop protocol, they are tested in fixed routes (e.g., Town05Long and Longest6 in CARLA) with the driving score as metrics, which is known for high variance due to the unsmoothed metric function and large randomness in the long route. Besides, these methods usually collect their own data for training, which makes algorithm-level fair comparison infeasible. To fulfill the paramount need of comprehensive, realistic, and fair testing environments for Full Self-Driving (FSD), we present Bench2Drive, the first benchmark for evaluating E2E-AD systems' multiple abilities in a closed-loop manner. Bench2Drive's official training data consists of 2 million fully annotated frames, collected from 10000 short clips uniformly distributed under 44 interactive scenarios (cut-in, overtaking, detour, etc), 23 weathers (sunny, foggy, rainy, etc), and 12 towns (urban, village, university, etc) in CARLA v2. Its evaluation protocol requires E2E-AD models to pass 44 interactive scenarios under different locations and weathers which sums up to 220 routes and thus provides a comprehensive and disentangled assessment about their driving capability under different situations. We implement state-of-the-art E2E-AD models and evaluate them in Bench2Drive, providing insights regarding current status and future directions.
A Survey of Large Language Models for Autonomous Driving
Nov 02, 2023



Autonomous driving technology, a catalyst for revolutionizing transportation and urban mobility, has the tend to transition from rule-based systems to data-driven strategies. Traditional module-based systems are constrained by cumulative errors among cascaded modules and inflexible pre-set rules. In contrast, end-to-end autonomous driving systems have the potential to avoid error accumulation due to their fully data-driven training process, although they often lack transparency due to their ``black box" nature, complicating the validation and traceability of decisions. Recently, large language models (LLMs) have demonstrated abilities including understanding context, logical reasoning, and generating answers. A natural thought is to utilize these abilities to empower autonomous driving. By combining LLM with foundation vision models, it could open the door to open-world understanding, reasoning, and few-shot learning, which current autonomous driving systems are lacking. In this paper, we systematically review a research line about \textit{Large Language Models for Autonomous Driving (LLM4AD)}. This study evaluates the current state of technological advancements, distinctly outlining the principal challenges and prospective directions for the field. For the convenience of researchers in academia and industry, we provide real-time updates on the latest advances in the field as well as relevant open-source resources via the designated link: https://github.com/Thinklab-SJTU/Awesome-LLM4AD.