 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoGround: A Unified Large Vision-Language Model. for Remote Sensing Visual Grounding
Nov 16, 2024



Remote sensing (RS) visual grounding aims to use natural language expression to locate specific objects (in the form of the bounding box or segmentation mask) in RS images, enhancing human interaction with intelligent RS interpretation systems. Early research in this area was primarily based on horizontal bounding boxes (HBBs), but as more diverse RS datasets have become available, tasks involving oriented bounding boxes (OBBs) and segmentation masks have emerged. In practical applications, different targets require different grounding types: HBB can localize an object's position, OBB provides its orientation, and mask depicts its shape. However, existing specialized methods are typically tailored to a single type of RS visual grounding task and are hard to generalize across tasks. In contrast, large vision-language models (VLMs) exhibit powerful multi-task learning capabilities but struggle to handle dense prediction tasks like segmentation. This paper proposes GeoGround, a novel framework that unifies support for HBB, OBB, and mask RS visual grounding tasks, allowing flexible output selection. Rather than customizing the architecture of VLM, our work aims to elegantly support pixel-level visual grounding output through the Text-Mask technique. We define prompt-assisted and geometry-guided learning to enhance consistency across different signals. To support model training, we present refGeo, a large-scale RS visual instruction-following dataset containing 161k image-text pairs. Experimental results show that GeoGround demonstrates strong performance across four RS visual grounding tasks, matching or surpassing the performance of specialized methods on multiple benchmarks. Code available at https://github.com/zytx121/GeoGround
Text4Seg: Reimagining Image Segmentation as Text Generation
Oct 13, 2024



Multimodal Large Language Models (MLLMs) have shown exceptional capabilities in vision-language tasks; however, effectively integrating image segmentation into these models remains a significant challenge. In this paper, we introduce Text4Seg, a novel text-as-mask paradigm that casts image segmentation as a text generation problem, eliminating the need for additional decoders and significantly simplifying the segmentation process. Our key innovation is semantic descriptors, a new textual representation of segmentation masks where each image patch is mapped to its corresponding text label. This unified representation allows seamless integration into the auto-regressive training pipeline of MLLMs for easier optimization. We demonstrate that representing an image with $16\times16$ semantic descriptors yields competitive segmentation performance. To enhance efficiency, we introduce the Row-wise Run-Length Encoding (R-RLE), which compresses redundant text sequences, reducing the length of semantic descriptors by 74% and accelerating inference by $3\times$, without compromising performance. Extensive experiments across various vision tasks, such as referring expression segmentation and comprehension, show that Text4Seg achieves state-of-the-art performance on multiple datasets by fine-tuning different MLLM backbones. Our approach provides an efficient, scalable solution for vision-centric tasks within the MLLM framework.
ProxyCLIP: Proxy Attention Improves CLIP for Open-Vocabulary Segmentation
Aug 09, 2024Open-vocabulary semantic segmentation requires models to effectively integrate visual representations with open-vocabulary semantic labels. While Contrastive Language-Image Pre-training (CLIP) models shine in recognizing visual concepts from text, they often struggle with segment coherence due to their limited localization ability. In contrast, Vision Foundation Models (VFMs) excel at acquiring spatially consistent local visual representations, yet they fall short in semantic understanding. This paper introduces ProxyCLIP, an innovative framework designed to harmonize the strengths of both CLIP and VFMs, facilitating enhanced open-vocabulary semantic segmentation. ProxyCLIP leverages the spatial feature correspondence from VFMs as a form of proxy attention to augment CLIP, thereby inheriting the VFMs' robust local consistency and maintaining CLIP's exceptional zero-shot transfer capacity. We propose an adaptive normalization and masking strategy to get the proxy attention from VFMs, allowing for adaptation across different VFMs. Remarkably, as a training-free approach, ProxyCLIP significantly improves the average mean Intersection over Union (mIoU) across eight benchmarks from 40.3 to 44.4, showcasing its exceptional efficacy in bridging the gap between spatial precision and semantic richness for the open-vocabulary segmentation task.
ClearCLIP: Decomposing CLIP Representations for Dense Vision-Language Inference
Jul 17, 2024



Despite the success of large-scale pretrained Vision-Language Models (VLMs) especially CLIP in various open-vocabulary tasks, their application to semantic segmentation remains challenging, producing noisy segmentation maps with mis-segmented regions. In this paper, we carefully re-investigate the architecture of CLIP, and identify residual connections as the primary source of noise that degrades segmentation quality. With a comparative analysis of statistical properties in the residual connection and the attention output across different pretrained models, we discover that CLIP's image-text contrastive training paradigm emphasizes global features at the expense of local discriminability, leading to noisy segmentation results. In response, we propose ClearCLIP, a novel approach that decomposes CLIP's representations to enhance open-vocabulary semantic segmentation. We introduce three simple modifications to the final layer: removing the residual connection, implementing the self-self attention, and discarding the feed-forward network. ClearCLIP consistently generates clearer and more accurate segmentation maps and outperforms existing approaches across multiple benchmarks, affirming the significance of our discoveries.
Towards Vision-Language Geo-Foundation Model: A Survey
Jun 13, 2024



Vision-Language Foundation Models (VLFMs) have made remarkable progress on various multimodal tasks, such as image captioning, image-text retrieval, visual question answering, and visual grounding. However, most methods rely on training with general image datasets, and the lack of geospatial data leads to poor performance on earth observation. Numerous geospatial image-text pair datasets and VLFMs fine-tuned on them have been proposed recently. These new approaches aim to leverage large-scale, multimodal geospatial data to build versatile intelligent models with diverse geo-perceptive capabilities, which we refer to as Vision-Language Geo-Foundation Models (VLGFMs). This paper thoroughly reviews VLGFMs, summarizing and analyzing recent developments in the field. In particular, we introduce the background and motivation behind the rise of VLGFMs, highlighting their unique research significance. Then, we systematically summarize the core technologies employed in VLGFMs, including data construction, model architectures, and applications of various multimodal geospatial tasks. Finally, we conclude with insights, issues, and discussions regarding future research directions. To the best of our knowledge, this is the first comprehensive literature review of VLGFMs. We keep tracing related works at https://github.com/zytx121/Awesome-VLGFM.
A$^{2}$-MAE: A spatial-temporal-spectral unified remote sensing pre-training method based on anchor-aware masked autoencoder
Jun 12, 2024



Vast amounts of remote sensing (RS) data provide Earth observations across multiple dimensions, encompassing critical spatial, temporal, and spectral information which is essential for addressing global-scale challenges such as land use monitoring, disaster prevention, and environmental change mitigation. Despite various pre-training methods tailored to the characteristics of RS data, a key limitation persists: the inability to effectively integrate spatial, temporal, and spectral information within a single unified model. To unlock the potential of RS data, we construct a Spatial-Temporal-Spectral Structured Dataset (STSSD) characterized by the incorporation of multiple RS sources, diverse coverage, unified locations within image sets, and heterogeneity within images. Building upon this structured dataset, we propose an Anchor-Aware Masked AutoEncoder method (A$^{2}$-MAE), leveraging intrinsic complementary information from the different kinds of images and geo-information to reconstruct the masked patches during the pre-training phase. A$^{2}$-MAE integrates an anchor-aware masking strategy and a geographic encoding module to comprehensively exploit the properties of RS images. Specifically, the proposed anchor-aware masking strategy dynamically adapts the masking process based on the meta-information of a pre-selected anchor image, thereby facilitating the training on images captured by diverse types of RS sources within one model. Furthermore, we propose a geographic encoding method to leverage accurate spatial patterns, enhancing the model generalization capabilities for downstream applications that are generally location-related. Extensive experiments demonstrate our method achieves comprehensive improvements across various downstream tasks compared with existing RS pre-training methods, including image classification, semantic segmentation, and change detection tasks.
H2RSVLM: Towards Helpful and Honest Remote Sensing Large Vision Language Model
Mar 29, 2024



The generic large Vision-Language Models (VLMs) is rapidly developing, but still perform poorly in Remote Sensing (RS) domain, which is due to the unique and specialized nature of RS imagery and the comparatively limited spatial perception of current VLMs. Existing Remote Sensing specific Vision Language Models (RSVLMs) still have considerable potential for improvement, primarily owing to the lack of large-scale, high-quality RS vision-language datasets. We constructed HqDC-1.4M, the large scale High quality and Detailed Captions for RS images, containing 1.4 million image-caption pairs, which not only enhance the RSVLM's understanding of RS images but also significantly improve the model's spatial perception abilities, such as localization and counting, thereby increasing the helpfulness of the RSVLM. Moreover, to address the inevitable "hallucination" problem in RSVLM, we developed RSSA, the first dataset aimed at enhancing the Self-Awareness capability of RSVLMs. By incorporating a variety of unanswerable questions into typical RS visual question-answering tasks, RSSA effectively improves the truthfulness and reduces the hallucinations of the model's outputs, thereby enhancing the honesty of the RSVLM. Based on these datasets, we proposed the H2RSVLM, the Helpful and Honest Remote Sensing Vision Language Model. H2RSVLM has achieved outstanding performance on multiple RS public datasets and is capable of recognizing and refusing to answer the unanswerable questions, effectively mitigating the incorrect generations. We will release the code, data and model weights at https://github.com/opendatalab/H2RSVLM .
SmooSeg: Smoothness Prior for Unsupervised Semantic Segmentation
Oct 27, 2023



Unsupervised semantic segmentation is a challenging task that segments images into semantic groups without manual annotation. Prior works have primarily focused on leveraging prior knowledge of semantic consistency or priori concepts from self-supervised learning methods, which often overlook the coherence property of image segments. In this paper, we demonstrate that the smoothness prior, asserting that close features in a metric space share the same semantics, can significantly simplify segmentation by casting unsupervised semantic segmentation as an energy minimization problem. Under this paradigm, we propose a novel approach called SmooSeg that harnesses self-supervised learning methods to model the closeness relationships among observations as smoothness signals. To effectively discover coherent semantic segments, we introduce a novel smoothness loss that promotes piecewise smoothness within segments while preserving discontinuities across different segments. Additionally, to further enhance segmentation quality, we design an asymmetric teacher-student style predictor that generates smoothly updated pseudo labels, facilitating an optimal fit between observations and labeling outputs. Thanks to the rich supervision cues of the smoothness prior, our SmooSeg significantly outperforms STEGO in terms of pixel accuracy on three datasets: COCOStuff (+14.9%), Cityscapes (+13.0%), and Potsdam-3 (+5.7%).
Diverse Cotraining Makes Strong Semi-Supervised Segmentor
Aug 18, 2023



Deep co-training has been introduced to semi-supervised segmentation and achieves impressive results, yet few studies have explored the working mechanism behind it. In this work, we revisit the core assumption that supports co-training: multiple compatible and conditionally independent views. By theoretically deriving the generalization upper bound, we prove the prediction similarity between two models negatively impacts the model's generalization ability. However, most current co-training models are tightly coupled together and violate this assumption. Such coupling leads to the homogenization of networks and confirmation bias which consequently limits the performance. To this end, we explore different dimensions of co-training and systematically increase the diversity from the aspects of input domains, different augmentations and model architectures to counteract homogenization. Our Diverse Co-training outperforms the state-of-the-art (SOTA) methods by a large margin across different evaluation protocols on the Pascal and Cityscapes. For example. we achieve the best mIoU of 76.2%, 77.7% and 80.2% on Pascal with only 92, 183 and 366 labeled images, surpassing the previous best results by more than 5%.
Consistent Teacher Provides Better Supervision in Semi-supervised Object Detection
Sep 04, 2022

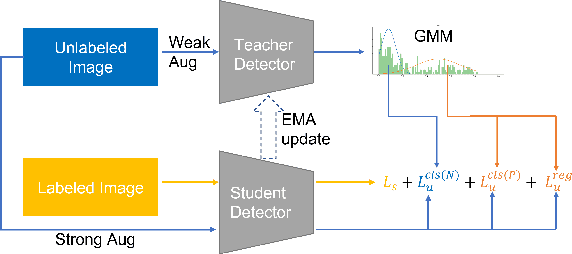
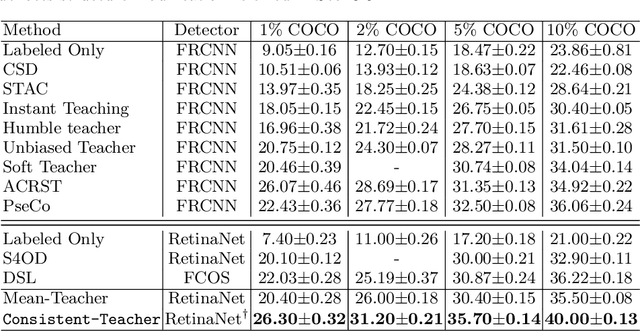
In this study, we dive deep into the unique challenges in semi-supervised object detection~(SSOD). We observe that current detectors generally suffer from 3 inconsistency problems. 1) Assignment inconsistency, that the conventional assignment policy is sensitive to labeling noise. 2) Subtasks inconsistency, where the classification and regression predictions are misaligned at the same feature point. 3) Temporal inconsistency, that the pseudo bboxes vary dramatically at different training steps. These issues lead to inconsistent optimization objectives of the student network, thus deteriorating performance and slowing down the model convergence. We, therefore, propose a systematic solution, termed Consistent Teacher, to remedy the above-mentioned challenges. First, adaptive anchor assignment substitutes the static IoU-based strategy, which enables the student network to be resistant to noisy psudo bboxes; Then we calibrate the subtask predictions by designing a feature alignment module; Lastly, We adopt a Gaussian Mixture Model (GMM) to dynamically adjust the pseudo-boxes threshold. Consistent Teacher provides a new strong baseline on a large range of SSOD evaluations. It achieves 40.0 mAP with ResNet-50 backbone given only 10% of annotated MS-COCO data, which surpasses previous baselines using pseudo labels by around 4 mAP. When trained on fully annotated MS-COCO with additional unlabeled data, the performance further increases to 49.1 mAP. Our code will be open-sourced soon.