 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreedyPrune: Retenting Critical Visual Token Set for Large Vision Language Models
Jun 16, 2025Although Large Vision Language Models (LVLMs) have demonstrated remarkable performance in image understanding tasks, their computational efficiency remains a significant challenge, particularly on resource-constrained devices due to the high cost of processing large numbers of visual tokens. Recently, training-free visual token pruning methods have gained popularity as a low-cost solution to this issue. However, existing approaches suffer from two key limitations: semantic saliency-based strategies primarily focus on high cross-attention visual tokens, often neglecting visual diversity, whereas visual diversity-based methods risk inadvertently discarding semantically important tokens, especially under high compression ratios. In this paper, we introduce GreedyPrune, a training-free plug-and-play visual token pruning algorithm designed to jointly optimize semantic saliency and visual diversity. We formalize the token pruning process as a combinatorial optimization problem and demonstrate that greedy algorithms effectively balance computational efficiency with model accuracy. Extensive experiments validate the effectiveness of our approach, showing that GreedyPrune achieves state-of-the-art accuracy across various multimodal tasks and models while significantly reducing end-to-end inference latency.
Scaling Test-time Compute for LLM Agents
Jun 15, 2025Scaling test time compute has shown remarkable success in improving the reasoning abilities of large language models (LLMs). In this work, we conduct the first systematic exploration of applying test-time scaling methods to language agents and investigate the extent to which it improves their effectiveness. Specifically, we explore different test-time scaling strategies, including: (1) parallel sampling algorithms; (2) sequential revision strategies; (3) verifiers and merging methods; (4)strategies for diversifying rollouts.We carefully analyze and ablate the impact of different design strategies on applying test-time scaling on language agents, and have follow findings: 1. Scaling test time compute could improve the performance of agents. 2. Knowing when to reflect is important for agents. 3. Among different verification and result merging approaches, the list-wise method performs best. 4. Increasing diversified rollouts exerts a positive effect on the agent's task performance.
EconGym: A Scalable AI Testbed with Diverse Economic Tasks
Jun 13, 2025Artificial intelligence (AI) has become a powerful tool for economic research, enabling large-scale simulation and policy optimization. However, applying AI effectively requires simulation platforms for scalable training and evaluation-yet existing environments remain limited to simplified, narrowly scoped tasks, falling short of capturing complex economic challenges such as demographic shifts, multi-government coordination, and large-scale agent interactions. To address this gap, we introduce EconGym, a scalable and modular testbed that connects diverse economic tasks with AI algorithms. Grounded in rigorous economic modeling, EconGym implements 11 heterogeneous role types (e.g., households, firms, banks, governments), their interaction mechanisms, and agent models with well-defined observations, actions, and rewards. Users can flexibly compose economic roles with diverse agent algorithms to simulate rich multi-agent trajectories across 25+ economic tasks for AI-driven policy learning and analysis. Experiments show that EconGym supports diverse and cross-domain tasks-such as coordinating fiscal, pension, and monetary policies-and enables benchmarking across AI, economic methods, and hybrids. Results indicate that richer task composition and algorithm diversity expand the policy space, while AI agents guided by classical economic methods perform best in complex settings. EconGym also scales to 10k agents with high realism and efficiency.
Improving Medical Visual Representation Learning with Pathological-level Cross-Modal Alignment and Correlation Exploration
Jun 12, 2025Learning medical visual representations from image-report pairs through joint learning has garnered increasing research attention due to its potential to alleviate the data scarcity problem in the medical domain. The primary challenges stem from the lengthy reports that feature complex discourse relations and semantic pathologies. Previous works have predominantly focused on instance-wise or token-wise cross-modal alignment, often neglecting the importance of pathological-level consistency. This paper presents a novel framework PLACE that promotes the Pathological-Level Alignment and enriches the fine-grained details via Correlation Exploration without additional human annotations. Specifically, we propose a novel pathological-level cross-modal alignment (PCMA) approach to maximize the consistency of pathology observations from both images and reports. To facilitate this, a Visual Pathology Observation Extractor is introduced to extract visual pathological observation representations from localized tokens. The PCMA module operates independently of any external disease annotations, enhancing the generalizability and robustness of our methods. Furthermore, we design a proxy task that enforces the model to identify correlations among image patches, thereby enriching the fine-grained details crucial for various downstream tasks. Experimental results demonstrate that our proposed framework achieves new state-of-the-art performance on multiple downstream tasks, including classification, image-to-text retrieval, semantic segmentation, object detection and report generation.
TaskCraft: Automated Generation of Agentic Tasks
Jun 11, 2025Agentic tasks, which require multi-step problem solving with autonomy, tool use, and adaptive reasoning, are becoming increasingly central to the advancement of NLP and AI. However, existing instruction data lacks tool interaction, and current agentic benchmarks rely on costly human annotation, limiting their scalability. We introduce \textsc{TaskCraft}, an automated workflow for generating difficulty-scalable, multi-tool, and verifiable agentic tasks with execution trajectories. TaskCraft expands atomic tasks using depth-based and width-based extensions to create structurally and hierarchically complex challenges. Empirical results show that these tasks improve prompt optimization in the generation workflow and enhance supervised fine-tuning of agentic foundation models. We present a large-scale synthetic dataset of approximately 36,000 tasks with varying difficulty to support future research on agent tuning and evaluation.
Causal Sufficiency and Necessity Improves Chain-of-Thought Reasoning
Jun 11, 2025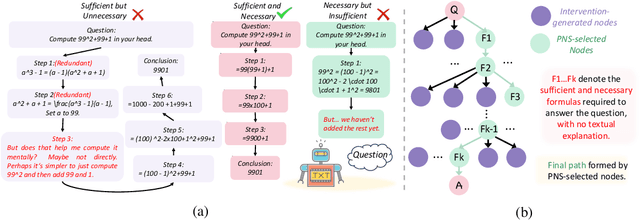
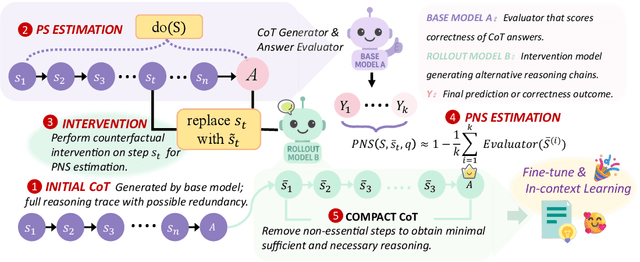
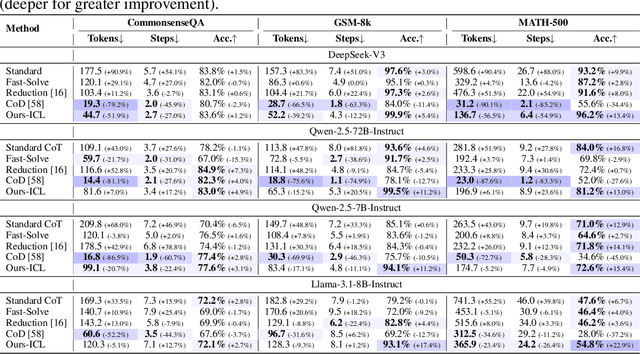
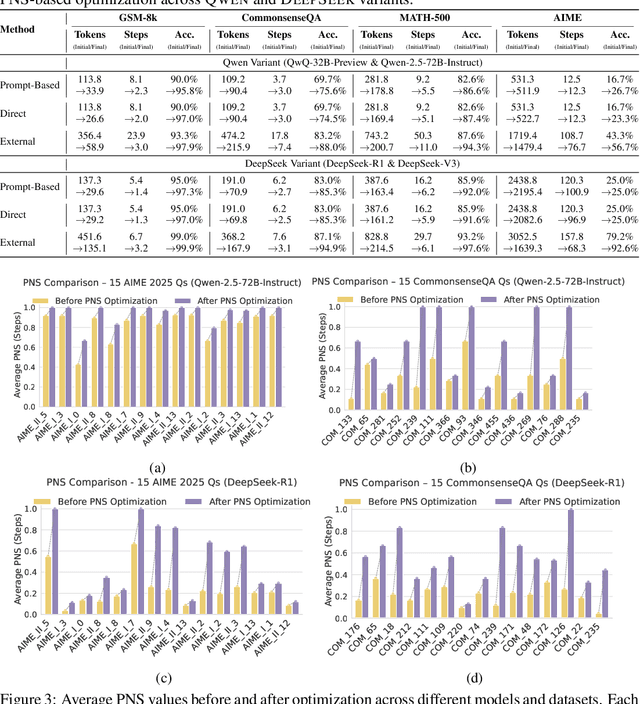
Chain-of-Thought (CoT) prompting plays an indispensable role in endowing large language models (LLMs) with complex reasoning capabilities. However, CoT currently faces two fundamental challenges: (1) Sufficiency, which ensures that the generated intermediate inference steps comprehensively cover and substantiate the final conclusion; and (2) Necessity, which identifies the inference steps that are truly indispensable for the soundness of the resulting answer. We propose a causal framework that characterizes CoT reasoning through the dual lenses of sufficiency and necessity. Incorporating causal Probability of Sufficiency and Necessity allows us not only to determine which steps are logically sufficient or necessary to the prediction outcome, but also to quantify their actual influence on the final reasoning outcome under different intervention scenarios, thereby enabling the automated addition of missing steps and the pruning of redundant ones. Extensive experimental results on various mathematical and commonsense reasoning benchmarks confirm substantial improvements in reasoning efficiency and reduced token usage without sacrificing accuracy. Our work provides a promising direction for improving LLM reasoning performance and cost-effectiveness.
TABLET: Table Structure Recognition using Encoder-only Transformers
Jun 08, 2025To address the challenges of table structure recognition, we propose a novel Split-Merge-based top-down model optimized for large, densely populated tables. Our approach formulates row and column splitting as sequence labeling tasks, utilizing dual Transformer encoders to capture feature interactions. The merging process is framed as a grid cell classification task, leveraging an additional Transformer encoder to ensure accurate and coherent merging. By eliminating unstable bounding box predictions, our method reduces resolution loss and computational complexity, achieving high accuracy while maintaining fast processing speed. Extensive experiments on FinTabNet and PubTabNet demonstrate the superiority of our model over existing approaches, particularly in real-world applications. Our method offers a robust, scalable, and efficient solution for large-scale table recognition, making it well-suited for industrial deployment.
Large Language Models are Demonstration Pre-Selectors for Themselves
Jun 06, 2025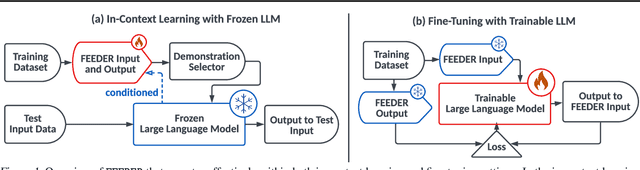
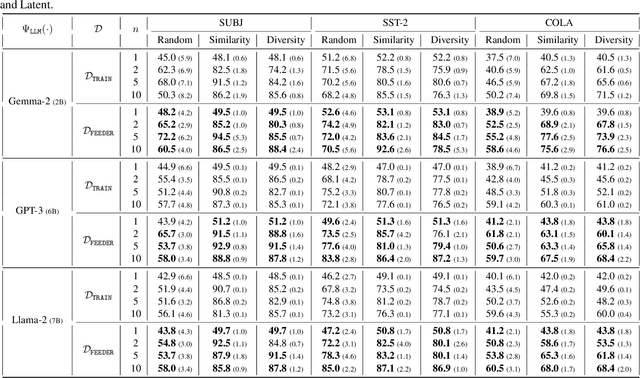
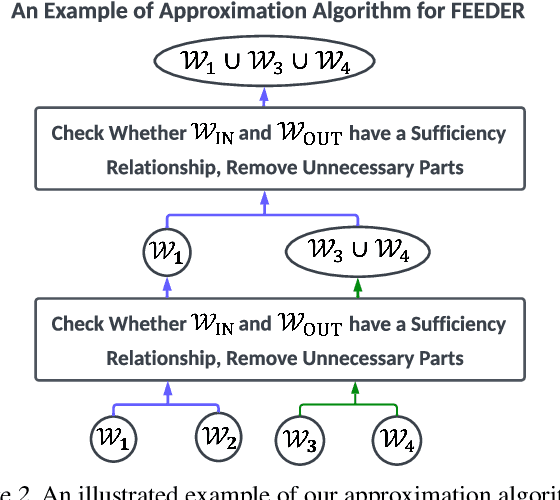
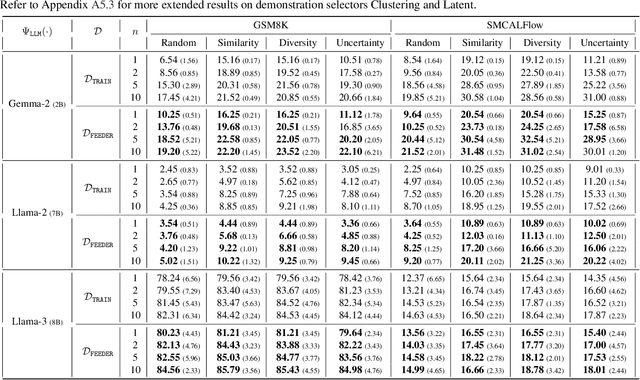
In-context learning (ICL) with large language models (LLMs) delivers strong few-shot performance by choosing few-shot demonstrations from the entire training data. However, existing ICL methods, which rely on similarity or diversity scores to choose demonstrations, incur high computational costs due to repeatedly retrieval from large-scale datasets for each query. To this end, we propose FEEDER (FEw yet Essential Demonstration prE-selectoR), a novel pre-selection framework that identifies a representative subset of demonstrations containing the most representative examples in the training data, tailored to specific LLMs. To construct this subset, we introduce the "sufficiency" and "necessity" metrics in the pre-selection stage and design a tree-based algorithm to identify representative examples efficiently. Once pre-selected, this representative subset can effectively replace the full training data, improving efficiency while maintaining comparable performance in ICL. Additionally, our pre-selected subset also benefits fine-tuning LLMs, where we introduce a bi-level optimization method that enhances training efficiency without sacrificing performance. Experiments with LLMs ranging from 300M to 8B parameters show that FEEDER can reduce training data size by over 20% while maintaining performance and seamlessly integrating with various downstream demonstration selection strategies in ICL.
Enhancing Efficiency and Propulsion in Bio-mimetic Robotic Fish through End-to-End Deep Reinforcement Learning
Jun 05, 2025Aquatic organisms are known for their ability to generate efficient propulsion with low energy expenditure. While existing research has sought to leverage bio-inspired structures to reduce energy costs in underwater robotics, the crucial role of control policies in enhancing efficiency has often been overlooked. In this study, we optimize the motion of a bio-mimetic robotic fish using deep reinforcement learning (DRL) to maximize propulsion efficiency and minimize energy consumption. Our novel DRL approach incorporates extended pressure perception, a transformer model processing sequences of observations, and a policy transfer scheme. Notably, significantly improved training stability and speed within our approach allow for end-to-end training of the robotic fish. This enables agiler responses to hydrodynamic environments and possesses greater optimization potential compared to pre-defined motion pattern controls. Our experiments are conducted on a serially connected rigid robotic fish in a free stream with a Reynolds number of 6000 using computational fluid dynamics (CFD) simulations. The DRL-trained policies yield impressive results, demonstrating both high efficiency and propulsion. The policies also showcase the agent's embodiment, skillfully utilizing its body structure and engaging with surrounding fluid dynamics, as revealed through flow analysis. This study provides valuable insights into the bio-mimetic underwater robots optimization through DRL training, capitalizing on their structural advantages, and ultimately contributing to more efficient underwater propulsion systems.
Risk-aware Direct Preference Optimization under Nested Risk Measure
May 29, 2025When fine-tuning pre-trained Large Language Models (LLMs) to align with human values and intentions, maximizing the estimated reward can lead to superior performance, but it also introduces potential risks due to deviations from the reference model's intended behavior. Most existing methods typically introduce KL divergence to constrain deviations between the trained model and the reference model; however, this may not be sufficient in certain applications that require tight risk control. In this paper, we introduce Risk-aware Direct Preference Optimization (Ra-DPO), a novel approach that incorporates risk-awareness by employing a class of nested risk measures. This approach formulates a constrained risk-aware advantage function maximization problem and then converts the Bradley-Terry model into a token-level representation. The objective function maximizes the likelihood of the policy while suppressing the deviation between a trained model and the reference model using a sequential risk ratio, thereby enhancing the model's risk-awareness. Experimental results across three open-source datasets: IMDb Dataset, Anthropic HH Dataset, and AlpacaEval, demonstrate the proposed method's superior performance in balancing alignment performance and model drift. Our code is opensourced at https://github.com/zlj123-max/Ra-DPO.