 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEAL: Can Saturated Benchmarks Be Revived by LLM-as-a-Meta-Judge?
May 28, 2026Widely used language-model benchmarks are increasingly saturated, with frontier systems often receiving near-tied scores that standard metrics cannot resolve. Rather than constructing harder alternatives, we ask whether existing tasks can be made informative again through improved evaluation over the same candidate outputs. Therefore, we present Seeded Elimination with Adaptive LLM-as-a-Meta-Judge, a self-improving evaluation protocol for extracting latent ranking signal from saturated benchmarks. SEAL seeds candidate outputs into a single elimination and evaluates each match with task-level principles plus self-improving checklist criteria. We evaluate SEAL on multiple saturated benchmarks covering code generation, mathematical reasoning, knowledge-intensive question answering, and tool-use agent task completion. Across these settings, SEAL improves the ranking-accuracy--latency trade-off over competing protocols, attaining 0.83--1.00 Spearman agreement with full pairwise judging and 4/4 top-1 agreement, while requiring only 11.89 calls per task compared with 28.00 for full pairwise evaluation.
DirectorBench: Diagnosing Long-Form Video Generation with Personalized Multi-Agent Evaluation
May 28, 2026Long-form video generation is rapidly moving from short, single-scene synthesis toward minute-long, multi-shot creation with narrative structure, cinematic control, audio, and cross-modal synchronization. However, evaluating such videos remains challenging, since existing benchmarks largely focus on local visual quality, short-horizon temporal consistency, or generic prompt alignment, and provide limited diagnosis of workflow failures and user-dependent preferences. We introduce DirectorBench, a personalized multi-agent diagnostic benchmark for long-form video generation. DirectorBench evaluates generated videos with respect to 80 structured metadata entries, 7 user profiles, and 40 checkpoint criteria across 5 dimensions: script, visual, audio, cross-modal, and stability. Instead of reducing quality to a single aggregate score, DirectorBench localizes checkpoint-level bottlenecks and supports profile-aware evaluation. We evaluate 4 long-form video generation workflows, 6 base LLMs, and 7 user profiles. Across workflows, DirectorBench reveals a between-unit bottleneck: transition quality averages only 0.256 and reaches 0.356 for the best workflow, while prompt-level user demand fulfillment averages 0.71. We further conduct human evaluation with 14 annotators to validate the alignment between DirectorBench and human judgment. The results show that DirectorBench captures human-perceptible quality differences and reveals workflow- and profile-dependent failure modes that are hidden by aggregate scoring. These findings highlight the importance of diagnostic and profile-aware benchmarking for long-form video generation.
Search More, Think Less: Rethinking Long-Horizon Agentic Search for Efficiency and Generalization
Feb 26, 2026Recent deep research agents primarily improve performance by scaling reasoning depth, but this leads to high inference cost and latency in search-intensive scenarios. Moreover, generalization across heterogeneous research settings remains challenging. In this work, we propose \emph{Search More, Think Less} (SMTL), a framework for long-horizon agentic search that targets both efficiency and generalization. SMTL replaces sequential reasoning with parallel evidence acquisition, enabling efficient context management under constrained context budgets. To support generalization across task types, we further introduce a unified data synthesis pipeline that constructs search tasks spanning both deterministic question answering and open-ended research scenarios with task appropriate evaluation metrics. We train an end-to-end agent using supervised fine-tuning and reinforcement learning, achieving strong and often state of the art performance across benchmarks including BrowseComp (48.6\%), GAIA (75.7\%), Xbench (82.0\%), and DeepResearch Bench (45.9\%). Compared to Mirothinker-v1.0, SMTL with maximum 100 interaction steps reduces the average number of reasoning steps on BrowseComp by 70.7\%, while improving accuracy.
O-Researcher: An Open Ended Deep Research Model via Multi-Agent Distillation and Agentic RL
Jan 07, 2026The performance gap between closed-source and open-source large language models (LLMs) is largely attributed to disparities in access to high-quality training data. To bridge this gap, we introduce a novel framework for the automated synthesis of sophisticated, research-grade instructional data. Our approach centers on a multi-agent workflow where collaborative AI agents simulate complex tool-integrated reasoning to generate diverse and high-fidelity data end-to-end. Leveraging this synthesized data, we develop a two-stage training strategy that integrates supervised fine-tuning with a novel reinforcement learning method, designed to maximize model alignment and capability. Extensive experiments demonstrate that our framework empowers open-source models across multiple scales, enabling them to achieve new state-of-the-art performance on the major deep research benchmark. This work provides a scalable and effective pathway for advancing open-source LLMs without relying on proprietary data or models.
O-Mem: Omni Memory System for Personalized, Long Horizon, Self-Evolving Agents
Nov 18, 2025



Recent advancements in LLM-powered agents have demonstrated significant potential in generating human-like responses; however, they continue to face challenges in maintaining long-term interactions within complex environments, primarily due to limitations in contextual consistency and dynamic personalization. Existing memory systems often depend on semantic grouping prior to retrieval, which can overlook semantically irrelevant yet critical user information and introduce retrieval noise. In this report, we propose the initial design of O-Mem, a novel memory framework based on active user profiling that dynamically extracts and updates user characteristics and event records from their proactive interactions with agents. O-Mem supports hierarchical retrieval of persona attributes and topic-related context, enabling more adaptive and coherent personalized responses. O-Mem achieves 51.67% on the public LoCoMo benchmark, a nearly 3% improvement upon LangMem,the previous state-of-the-art, and it achieves 62.99% on PERSONAMEM, a 3.5% improvement upon A-Mem,the previous state-of-the-art. O-Mem also boosts token and interaction response time efficiency compared to previous memory frameworks. Our work opens up promising directions for developing efficient and human-like personalized AI assistants in the future.
TaskCraft: Automated Generation of Agentic Tasks
Jun 11, 2025Agentic tasks, which require multi-step problem solving with autonomy, tool use, and adaptive reasoning, are becoming increasingly central to the advancement of NLP and AI. However, existing instruction data lacks tool interaction, and current agentic benchmarks rely on costly human annotation, limiting their scalability. We introduce \textsc{TaskCraft}, an automated workflow for generating difficulty-scalable, multi-tool, and verifiable agentic tasks with execution trajectories. TaskCraft expands atomic tasks using depth-based and width-based extensions to create structurally and hierarchically complex challenges. Empirical results show that these tasks improve prompt optimization in the generation workflow and enhance supervised fine-tuning of agentic foundation models. We present a large-scale synthetic dataset of approximately 36,000 tasks with varying difficulty to support future research on agent tuning and evaluation.
Dual Contrastive Learning: Text Classification via Label-Aware Data Augmentation
Jan 21, 2022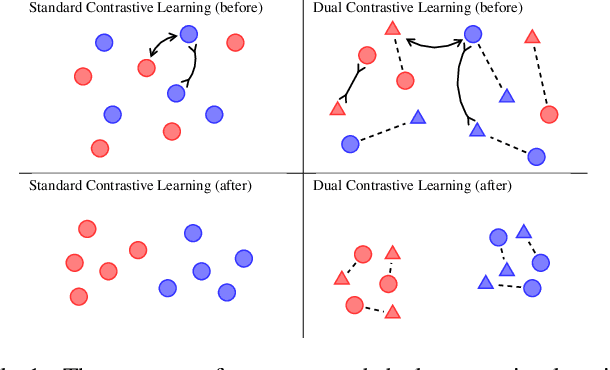
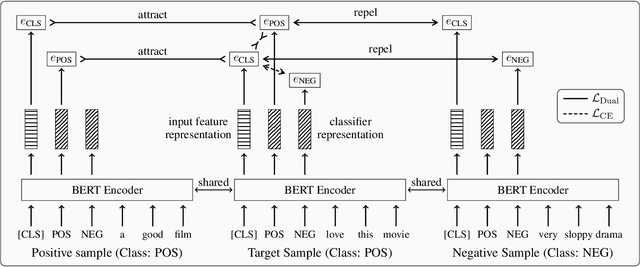
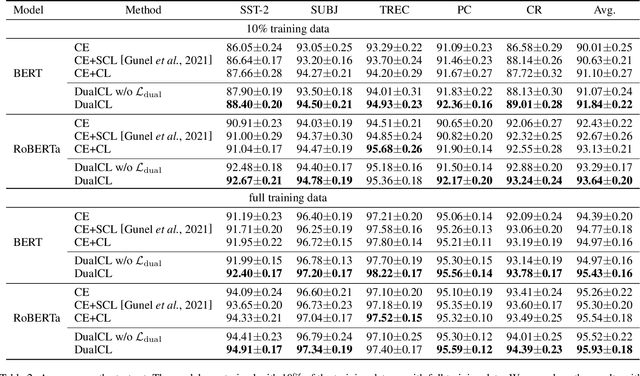
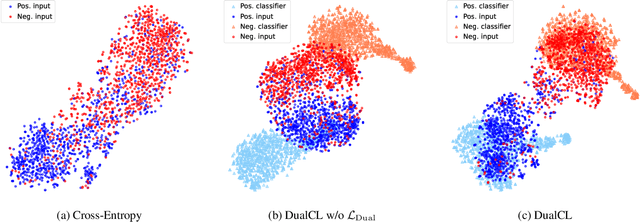
Contrastive learning has achieved remarkable success in representation learning via self-supervision in unsupervised settings. However, effectively adapting contrastive learning to supervised learning tasks remains as a challenge in practice. In this work, we introduce a dual contrastive learning (DualCL) framework that simultaneously learns the features of input samples and the parameters of classifiers in the same space. Specifically, DualCL regards the parameters of the classifiers as augmented samples associating to different labels and then exploits the contrastive learning between the input samples and the augmented samples. Empirical studies on five benchmark text classification datasets and their low-resource version demonstrate the improvement in classification accuracy and confirm the capability of learning discriminative representations of DualCL.