 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvariant Causal Routing for Governing Social Norms in Online Market Economies
Mar 04, 2026Social norms are stable behavioral patterns that emerge endogenously within economic systems through repeated interactions among agents. In online market economies, such norms -- like fair exposure, sustained participation, and balanced reinvestment -- are critical for long-term stability. We aim to understand the causal mechanisms driving these emergent norms and to design principled interventions that can steer them toward desired outcomes. This is challenging because norms arise from countless micro-level interactions that aggregate into macro-level regularities, making causal attribution and policy transferability difficult. To address this, we propose \textbf{Invariant Causal Routing (ICR)}, a causal governance framework that identifies policy-norm relations stable across heterogeneous environments. ICR integrates counterfactual reasoning with invariant causal discovery to separate genuine causal effects from spurious correlations and to construct interpretable, auditable policy rules that remain effective under distribution shift. In heterogeneous agent simulations calibrated with real data, ICR yields more stable norms, smaller generalization gaps, and more concise rules than correlation or coverage baselines, demonstrating that causal invariance offers a principled and interpretable foundation for governance.
ProcMEM: Learning Reusable Procedural Memory from Experience via Non-Parametric PPO for LLM Agents
Feb 02, 2026LLM-driven agents demonstrate strong performance in sequential decision-making but often rely on on-the-fly reasoning, re-deriving solutions even in recurring scenarios. This insufficient experience reuse leads to computational redundancy and execution instability. To bridge this gap, we propose ProcMEM, a framework that enables agents to autonomously learn procedural memory from interaction experiences without parameter updates. By formalizing a Skill-MDP, ProcMEM transforms passive episodic narratives into executable Skills defined by activation, execution, and termination conditions to ensure executability. To achieve reliable reusability without capability degradation, we introduce Non-Parametric PPO, which leverages semantic gradients for high-quality candidate generation and a PPO Gate for robust Skill verification. Through score-based maintenance, ProcMEM sustains compact, high-quality procedural memory. Experimental results across in-domain, cross-task, and cross-agent scenarios demonstrate that ProcMEM achieves superior reuse rates and significant performance gains with extreme memory compression. Visualized evolutionary trajectories and Skill distributions further reveal how ProcMEM transparently accumulates, refines, and reuses procedural knowledge to facilitate long-term autonomy.
Think, Speak, Decide: Language-Augmented Multi-Agent Reinforcement Learning for Economic Decision-Making
Nov 17, 2025



Economic decision-making depends not only on structured signals such as prices and taxes, but also on unstructured language, including peer dialogue and media narratives. While multi-agent reinforcement learning (MARL) has shown promise in optimizing economic decisions, it struggles with the semantic ambiguity and contextual richness of language. We propose LAMP (Language-Augmented Multi-Agent Policy), a framework that integrates language into economic decision-making and narrows the gap to real-world settings. LAMP follows a Think-Speak-Decide pipeline: (1) Think interprets numerical observations to extract short-term shocks and long-term trends, caching high-value reasoning trajectories; (2) Speak crafts and exchanges strategic messages based on reasoning, updating beliefs by parsing peer communications; and (3) Decide fuses numerical data, reasoning, and reflections into a MARL policy to optimize language-augmented decision-making. Experiments in economic simulation show that LAMP outperforms both MARL and LLM-only baselines in cumulative return (+63.5%, +34.0%), robustness (+18.8%, +59.4%), and interpretability. These results demonstrate the potential of language-augmented policies to deliver more effective and robust economic strategies.
EconGym: A Scalable AI Testbed with Diverse Economic Tasks
Jun 13, 2025



Artificial intelligence (AI) has become a powerful tool for economic research, enabling large-scale simulation and policy optimization. However, applying AI effectively requires simulation platforms for scalable training and evaluation-yet existing environments remain limited to simplified, narrowly scoped tasks, falling short of capturing complex economic challenges such as demographic shifts, multi-government coordination, and large-scale agent interactions. To address this gap, we introduce EconGym, a scalable and modular testbed that connects diverse economic tasks with AI algorithms. Grounded in rigorous economic modeling, EconGym implements 11 heterogeneous role types (e.g., households, firms, banks, governments), their interaction mechanisms, and agent models with well-defined observations, actions, and rewards. Users can flexibly compose economic roles with diverse agent algorithms to simulate rich multi-agent trajectories across 25+ economic tasks for AI-driven policy learning and analysis. Experiments show that EconGym supports diverse and cross-domain tasks-such as coordinating fiscal, pension, and monetary policies-and enables benchmarking across AI, economic methods, and hybrids. Results indicate that richer task composition and algorithm diversity expand the policy space, while AI agents guided by classical economic methods perform best in complex settings. EconGym also scales to 10k agents with high realism and efficiency.
MF-LLM: Simulating Collective Decision Dynamics via a Mean-Field Large Language Model Framework
Apr 30, 2025
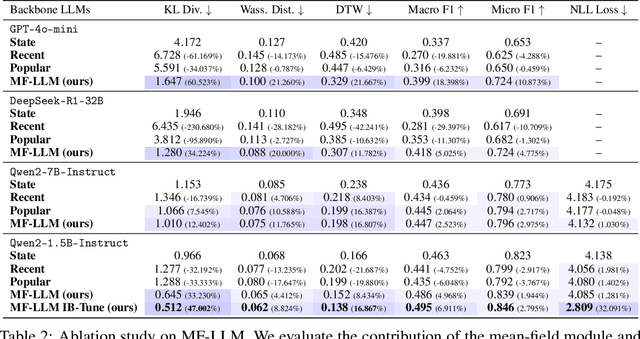


Simulating collective decision-making involves more than aggregating individual behaviors; it arises from dynamic interactions among individuals. While large language models (LLMs) show promise for social simulation, existing approaches often exhibit deviations from real-world data. To address this gap, we propose the Mean-Field LLM (MF-LLM) framework, which explicitly models the feedback loop between micro-level decisions and macro-level population. MF-LLM alternates between two models: a policy model that generates individual actions based on personal states and group-level information, and a mean field model that updates the population distribution from the latest individual decisions. Together, they produce rollouts that simulate the evolving trajectories of collective decision-making. To better match real-world data, we introduce IB-Tune, a fine-tuning method for LLMs grounded in the information bottleneck principle, which maximizes the relevance of population distributions to future actions while minimizing redundancy with historical data. We evaluate MF-LLM on a real-world social dataset, where it reduces KL divergence to human population distributions by 47 percent over non-mean-field baselines, and enables accurate trend forecasting and intervention planning. It generalizes across seven domains and four LLM backbones, providing a scalable foundation for high-fidelity social simulation.
Learning Macroeconomic Policies based on Microfoundations: A Stackelberg Mean Field Game Approach
Mar 14, 2024Effective macroeconomic policies play a crucial role in promoting economic growth and social stability. This paper models the optimal macroeconomic policy problem based on the \textit{Stackelberg Mean Field Game} (SMFG), where the government acts as the leader in policy-making, and large-scale households dynamically respond as followers. This modeling method captures the asymmetric dynamic game between the government and large-scale households, and interpretably evaluates the effects of macroeconomic policies based on microfoundations, which is difficult for existing methods to achieve. We also propose a solution for SMFGs, incorporating pre-training on real data and a model-free \textit{Stackelberg mean-field reinforcement learning }(SMFRL) algorithm, which operates independently of prior environmental knowledge and transitions. Our experimental results showcase the superiority of the SMFG method over other economic policies in terms of performance, efficiency-equity tradeoff, and SMFG assumption analysis. This paper significantly contributes to the domain of AI for economics by providing a powerful tool for modeling and solving optimal macroeconomic policies.
Large Language Models Play StarCraft II: Benchmarks and A Chain of Summarization Approach
Dec 19, 2023
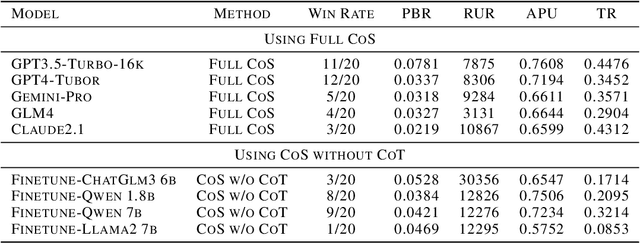


StarCraft II is a challenging benchmark for AI agents due to the necessity of both precise micro level operations and strategic macro awareness. Previous works, such as Alphastar and SCC, achieve impressive performance on tackling StarCraft II , however, still exhibit deficiencies in long term strategic planning and strategy interpretability. Emerging large language model (LLM) agents, such as Voyage and MetaGPT, presents the immense potential in solving intricate tasks. Motivated by this, we aim to validate the capabilities of LLMs on StarCraft II, a highly complex RTS game.To conveniently take full advantage of LLMs` reasoning abilities, we first develop textual StratCraft II environment, called TextStarCraft II, which LLM agent can interact. Secondly, we propose a Chain of Summarization method, including single frame summarization for processing raw observations and multi frame summarization for analyzing game information, providing command recommendations, and generating strategic decisions. Our experiment consists of two parts: first, an evaluation by human experts, which includes assessing the LLMs`s mastery of StarCraft II knowledge and the performance of LLM agents in the game; second, the in game performance of LLM agents, encompassing aspects like win rate and the impact of Chain of Summarization.Experiment results demonstrate that: 1. LLMs possess the relevant knowledge and complex planning abilities needed to address StarCraft II scenarios; 2. Human experts consider the performance of LLM agents to be close to that of an average player who has played StarCraft II for eight years; 3. LLM agents are capable of defeating the built in AI at the Harder(Lv5) difficulty level. We have open sourced the code and released demo videos of LLM agent playing StarCraft II.