 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models are Demonstration Pre-Selectors for Themselves
Jun 06, 2025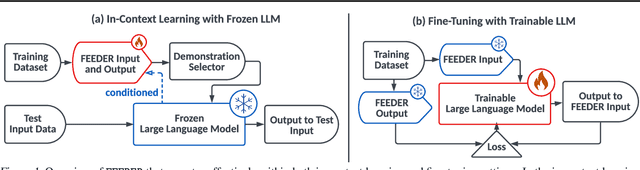
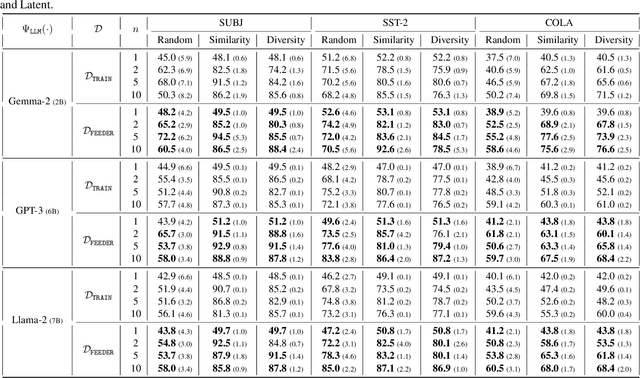
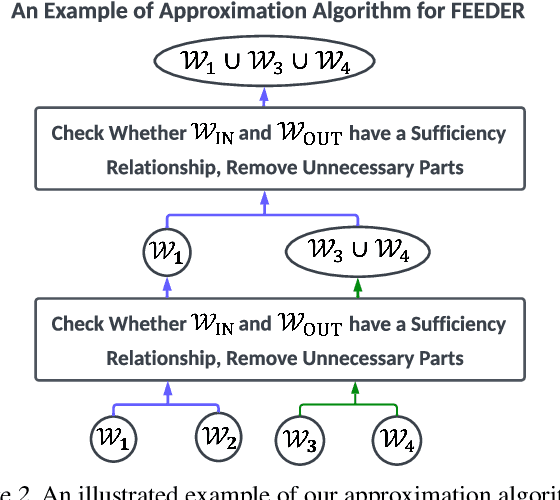
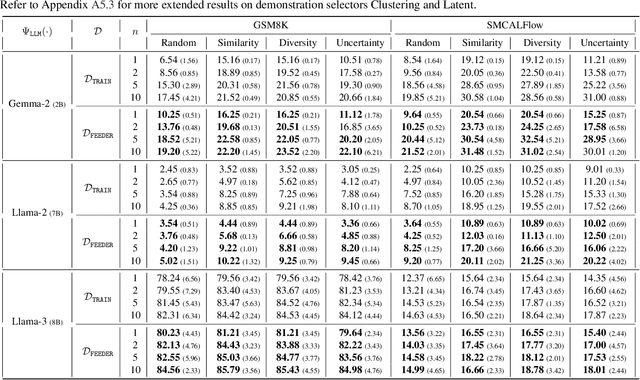
In-context learning (ICL) with large language models (LLMs) delivers strong few-shot performance by choosing few-shot demonstrations from the entire training data. However, existing ICL methods, which rely on similarity or diversity scores to choose demonstrations, incur high computational costs due to repeatedly retrieval from large-scale datasets for each query. To this end, we propose FEEDER (FEw yet Essential Demonstration prE-selectoR), a novel pre-selection framework that identifies a representative subset of demonstrations containing the most representative examples in the training data, tailored to specific LLMs. To construct this subset, we introduce the "sufficiency" and "necessity" metrics in the pre-selection stage and design a tree-based algorithm to identify representative examples efficiently. Once pre-selected, this representative subset can effectively replace the full training data, improving efficiency while maintaining comparable performance in ICL. Additionally, our pre-selected subset also benefits fine-tuning LLMs, where we introduce a bi-level optimization method that enhances training efficiency without sacrificing performance. Experiments with LLMs ranging from 300M to 8B parameters show that FEEDER can reduce training data size by over 20% while maintaining performance and seamlessly integrating with various downstream demonstration selection strategies in ICL.