 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Merge, Ensemble, and Cooperate! A Survey on Collaborative Strategies in the Era of Large Language Models
Jul 08, 2024



The remarkable success of Large Language Models (LLMs) has ushered natural language processing (NLP) research into a new era. Despite their diverse capabilities, LLMs trained on different corpora exhibit varying strengths and weaknesses, leading to challenges in maximizing their overall efficiency and versatility. To address these challenges, recent studies have explored collaborative strategies for LLMs. This paper provides a comprehensive overview of this emerging research area, highlighting the motivation behind such collaborations. Specifically, we categorize collaborative strategies into three primary approaches: Merging, Ensemble, and Cooperation. Merging involves integrating multiple LLMs in the parameter space. Ensemble combines the outputs of various LLMs. Cooperation} leverages different LLMs to allow full play to their diverse capabilities for specific tasks. We provide in-depth introductions to these methods from different perspectives and discuss their potential applications. Additionally, we outline future research directions, hoping this work will catalyze further studies on LLM collaborations and paving the way for advanced NLP applications.
Diver: Large Language Model Decoding with Span-Level Mutual Information Verification
Jun 04, 2024



Large language models (LLMs) have shown impressive capabilities in adapting to various tasks when provided with task-specific instructions. However, LLMs using standard decoding strategies often struggle with deviations from the inputs. Intuitively, compliant LLM outputs should reflect the information present in the input, which can be measured by point-wise mutual information (PMI) scores. Therefore, we propose Diver, a novel approach that enhances LLM Decoding through span-level PMI verification. During inference, Diver first identifies divergence steps that may lead to multiple candidate spans. Subsequently, it calculates the PMI scores by assessing the log-likelihood gains of the input if the candidate spans are generated. Finally, the optimal span is selected based on the PMI re-ranked output distributions. We evaluate our method across various downstream tasks, and empirical results demonstrate that Diver significantly outperforms existing decoding methods in both performance and versatility.
X-Instruction: Aligning Language Model in Low-resource Languages with Self-curated Cross-lingual Instructions
May 30, 2024Large language models respond well in high-resource languages like English but struggle in low-resource languages. It may arise from the lack of high-quality instruction following data in these languages. Directly translating English samples into these languages can be a solution but unreliable, leading to responses with translation errors and lacking language-specific or cultural knowledge. To address this issue, we propose a novel method to construct cross-lingual instruction following samples with instruction in English and response in low-resource languages. Specifically, the language model first learns to generate appropriate English instructions according to the natural web texts in other languages as responses. The candidate cross-lingual instruction tuning samples are further refined and diversified. We have employed this method to build a large-scale cross-lingual instruction tuning dataset on 10 languages, namely X-Instruction. The instruction data built using our method incorporate more language-specific knowledge compared with the naive translation method. Experimental results have shown that the response quality of the model tuned on X-Instruction greatly exceeds the model distilled from a powerful teacher model, reaching or even surpassing the ones of ChatGPT. In addition, we find that models tuned on cross-lingual instruction following samples can follow the instruction in the output language without further tuning.
Bridging the Gap between Different Vocabularies for LLM Ensemble
Apr 15, 2024



Ensembling different large language models (LLMs) to unleash their complementary potential and harness their individual strengths is highly valuable. Nevertheless, vocabulary discrepancies among various LLMs have constrained previous studies to either selecting or blending completely generated outputs. This limitation hinders the dynamic correction and enhancement of outputs during the generation process, resulting in a limited capacity for effective ensemble. To address this issue, we propose a novel method to Ensemble LLMs via Vocabulary Alignment (EVA). EVA bridges the lexical gap among various LLMs, enabling meticulous ensemble at each generation step. Specifically, we first learn mappings between the vocabularies of different LLMs with the assistance of overlapping tokens. Subsequently, these mappings are employed to project output distributions of LLMs into a unified space, facilitating a fine-grained ensemble. Finally, we design a filtering strategy to exclude models that generate unfaithful tokens. Experimental results on commonsense reasoning, arithmetic reasoning, machine translation, and data-to-text generation tasks demonstrate the superiority of our approach compared with individual LLMs and previous ensemble methods conducted on complete outputs. Further analyses confirm that our approach can leverage knowledge from different language models and yield consistent improvement.
BLSP: Bootstrapping Language-Speech Pre-training via Behavior Alignment of Continuation Writing
Sep 02, 2023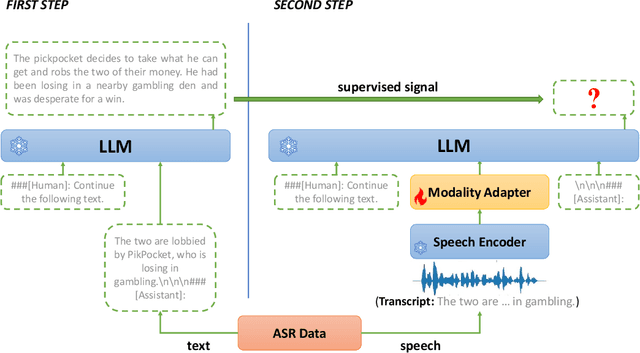


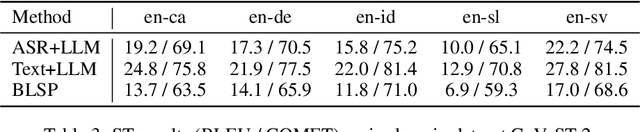
The emergence of large language models (LLMs) has sparked significant interest in extending their remarkable language capabilities to speech. However, modality alignment between speech and text still remains an open problem. Current solutions can be categorized into two strategies. One is a cascaded approach where outputs (tokens or states) of a separately trained speech recognition system are used as inputs for LLMs, which limits their potential in modeling alignment between speech and text. The other is an end-to-end approach that relies on speech instruction data, which is very difficult to collect in large quantities. In this paper, we address these issues and propose the BLSP approach that Bootstraps Language-Speech Pre-training via behavior alignment of continuation writing. We achieve this by learning a lightweight modality adapter between a frozen speech encoder and an LLM, ensuring that the LLM exhibits the same generation behavior regardless of the modality of input: a speech segment or its transcript. The training process can be divided into two steps. The first step prompts an LLM to generate texts with speech transcripts as prefixes, obtaining text continuations. In the second step, these continuations are used as supervised signals to train the modality adapter in an end-to-end manner. We demonstrate that this straightforward process can extend the capabilities of LLMs to speech, enabling speech recognition, speech translation, spoken language understanding, and speech conversation, even in zero-shot cross-lingual scenarios.
Instance-aware Prompt Learning for Language Understanding and Generation
Jan 18, 2022
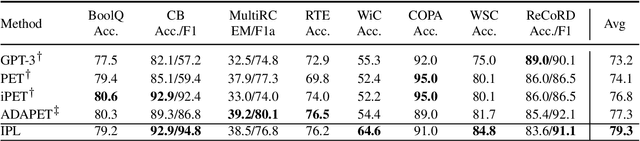
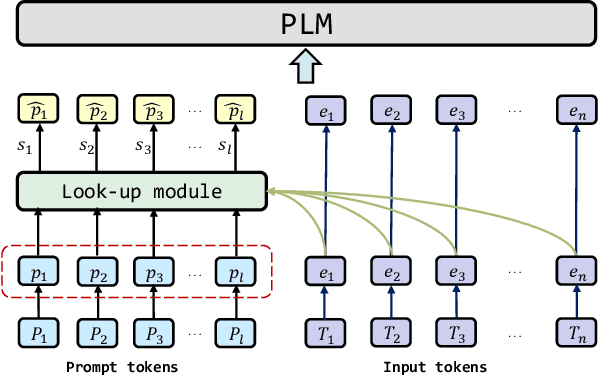
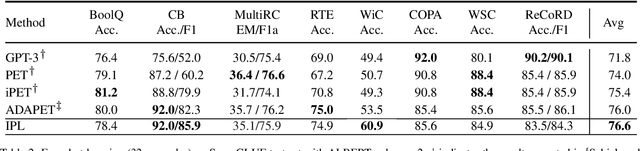
Recently, prompt learning has become a new paradigm to utilize pre-trained language models (PLMs) and achieves promising results in downstream tasks with a negligible increase of parameters. The current usage of discrete and continuous prompts assumes that the prompt is fixed for a specific task and all samples in the task share the same prompt. However, a task may contain quite diverse samples in which some are easy and others are difficult, and diverse prompts are desirable. In this paper, we propose an instance-aware prompt learning method that learns a different prompt for each instance. Specifically, we suppose that each learnable prompt token has a different contribution to different instances, and we learn the contribution by calculating the relevance score between an instance and each prompt token. The contribution weighted prompt would be instance aware. We apply our method to both unidirectional and bidirectional PLMs on both language understanding and generation tasks. Extensive experiments demonstrate that our method obtains considerable improvements compared to strong baselines. Especially, our method achieves the state-of-the-art on the SuperGLUE few-shot learning benchmark.
CUGE: A Chinese Language Understanding and Generation Evaluation Benchmark
Dec 27, 2021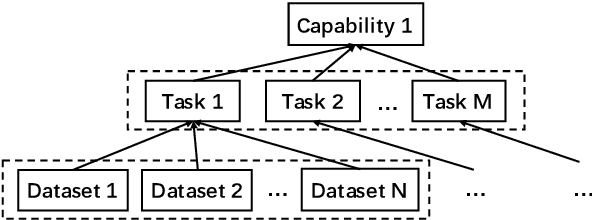
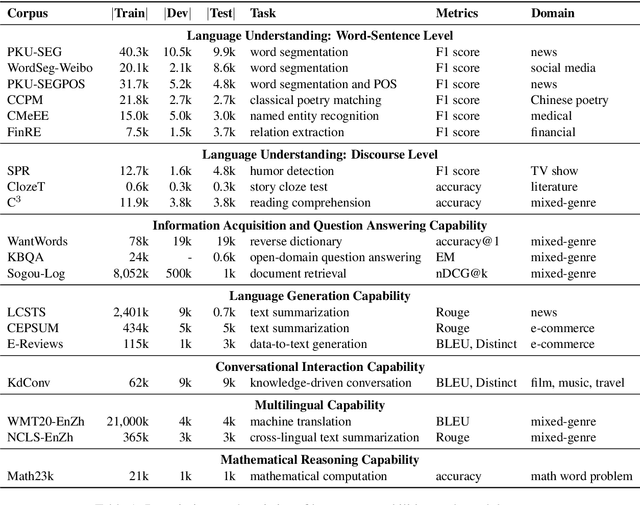

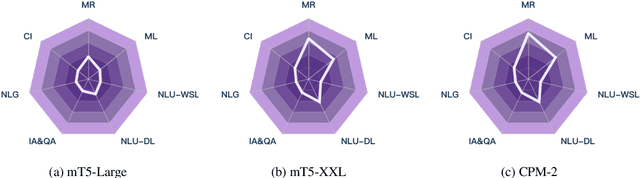
Realizing general-purpose language intelligence has been a longstanding goal for natural language processing, where standard evaluation benchmarks play a fundamental and guiding role. We argue that for general-purpose language intelligence evaluation, the benchmark itself needs to be comprehensive and systematic. To this end, we propose CUGE, a Chinese Language Understanding and Generation Evaluation benchmark with the following features: (1) Hierarchical benchmark framework, where datasets are principally selected and organized with a language capability-task-dataset hierarchy. (2) Multi-level scoring strategy, where different levels of model performance are provided based on the hierarchical framework. To facilitate CUGE, we provide a public leaderboard that can be customized to support flexible model judging criteria. Evaluation results on representative pre-trained language models indicate ample room for improvement towards general-purpose language intelligence. CUGE is publicly available at cuge.baai.ac.cn.
Exploiting Curriculum Learning in Unsupervised Neural Machine Translation
Sep 23, 2021
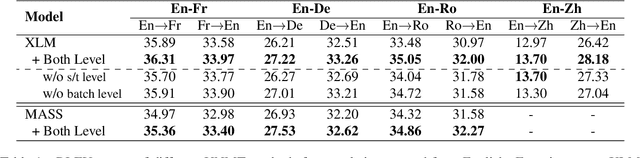
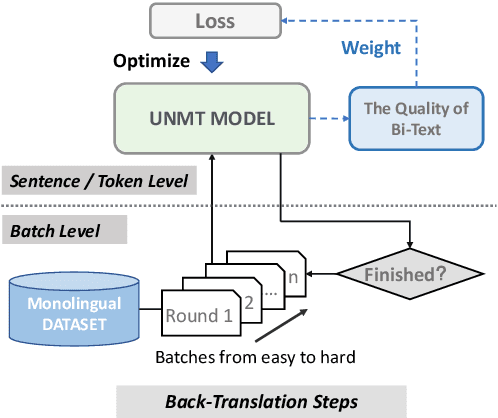

Back-translation (BT) has become one of the de facto components in unsupervised neural machine translation (UNMT), and it explicitly makes UNMT have translation ability. However, all the pseudo bi-texts generated by BT are treated equally as clean data during optimization without considering the quality diversity, leading to slow convergence and limited translation performance. To address this problem, we propose a curriculum learning method to gradually utilize pseudo bi-texts based on their quality from multiple granularities. Specifically, we first apply cross-lingual word embedding to calculate the potential translation difficulty (quality) for the monolingual sentences. Then, the sentences are fed into UNMT from easy to hard batch by batch. Furthermore, considering the quality of sentences/tokens in a particular batch are also diverse, we further adopt the model itself to calculate the fine-grained quality scores, which are served as learning factors to balance the contributions of different parts when computing loss and encourage the UNMT model to focus on pseudo data with higher quality. Experimental results on WMT 14 En-Fr, WMT 16 En-De, WMT 16 En-Ro, and LDC En-Zh translation tasks demonstrate that the proposed method achieves consistent improvements with faster convergence speed.