 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOdysseyBench: Evaluating LLM Agents on Long-Horizon Complex Office Application Workflows
Aug 12, 2025



Autonomous agents powered by large language models (LLMs) are increasingly deployed in real-world applications requiring complex, long-horizon workflows. However, existing benchmarks predominantly focus on atomic tasks that are self-contained and independent, failing to capture the long-term contextual dependencies and multi-interaction coordination required in realistic scenarios. To address this gap, we introduce OdysseyBench, a comprehensive benchmark for evaluating LLM agents on long-horizon workflows across diverse office applications including Word, Excel, PDF, Email, and Calendar. Our benchmark comprises two complementary splits: OdysseyBench+ with 300 tasks derived from real-world use cases, and OdysseyBench-Neo with 302 newly synthesized complex tasks. Each task requires agent to identify essential information from long-horizon interaction histories and perform multi-step reasoning across various applications. To enable scalable benchmark creation, we propose HomerAgents, a multi-agent framework that automates the generation of long-horizon workflow benchmarks through systematic environment exploration, task generation, and dialogue synthesis. Our extensive evaluation demonstrates that OdysseyBench effectively challenges state-of-the-art LLM agents, providing more accurate assessment of their capabilities in complex, real-world contexts compared to existing atomic task benchmarks. We believe that OdysseyBench will serve as a valuable resource for advancing the development and evaluation of LLM agents in real-world productivity scenarios. In addition, we release OdysseyBench and HomerAgents to foster research along this line.
MVISU-Bench: Benchmarking Mobile Agents for Real-World Tasks by Multi-App, Vague, Interactive, Single-App and Unethical Instructions
Aug 12, 2025Given the significant advances in Large Vision Language Models (LVLMs) in reasoning and visual understanding, mobile agents are rapidly emerging to meet users' automation needs. However, existing evaluation benchmarks are disconnected from the real world and fail to adequately address the diverse and complex requirements of users. From our extensive collection of user questionnaire, we identified five tasks: Multi-App, Vague, Interactive, Single-App, and Unethical Instructions. Around these tasks, we present \textbf{MVISU-Bench}, a bilingual benchmark that includes 404 tasks across 137 mobile applications. Furthermore, we propose Aider, a plug-and-play module that acts as a dynamic prompt prompter to mitigate risks and clarify user intent for mobile agents. Our Aider is easy to integrate into several frameworks and has successfully improved overall success rates by 19.55\% compared to the current state-of-the-art (SOTA) on MVISU-Bench. Specifically, it achieves success rate improvements of 53.52\% and 29.41\% for unethical and interactive instructions, respectively. Through extensive experiments and analysis, we highlight the gap between existing mobile agents and real-world user expectations.
Quasi-Clique Discovery via Energy Diffusion
Aug 06, 2025Discovering quasi-cliques -- subgraphs with edge density no less than a given threshold -- is a fundamental task in graph mining, with broad applications in social networks, bioinformatics, and e-commerce. Existing heuristics often rely on greedy rules, similarity measures, or metaheuristic search, but struggle to maintain both efficiency and solution consistency across diverse graphs. This paper introduces EDQC, a novel quasi-clique discovery algorithm inspired by energy diffusion. Instead of explicitly enumerating candidate subgraphs, EDQC performs stochastic energy diffusion from source vertices, naturally concentrating energy within structurally cohesive regions. The approach enables efficient dense subgraph discovery without exhaustive search or dataset-specific tuning. Experimental results on 30 real-world datasets demonstrate that EDQC consistently discovers larger quasi-cliques than state-of-the-art baselines on the majority of datasets, while also yielding lower variance in solution quality. To the best of our knowledge, EDQC is the first method to incorporate energy diffusion into quasi-clique discovery.
Enhancing Reasoning Capabilities of Small Language Models with Blueprints and Prompt Template Search
Jun 10, 2025
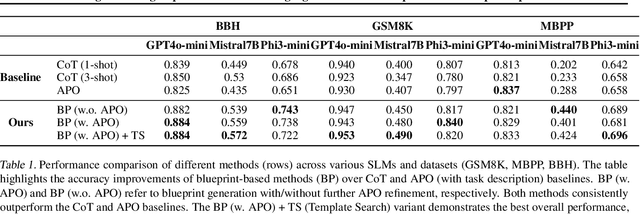


Small language models (SLMs) offer promising and efficient alternatives to large language models (LLMs). However, SLMs' limited capacity restricts their reasoning capabilities and makes them sensitive to prompt variations. To address these challenges, we propose a novel framework that enhances SLM reasoning capabilities through LLM generated blueprints. The blueprints provide structured, high-level reasoning guides that help SLMs systematically tackle related problems. Furthermore, our framework integrates a prompt template search mechanism to mitigate the SLMs' sensitivity to prompt variations. Our framework demonstrates improved SLM performance across various tasks, including math (GSM8K), coding (MBPP), and logic reasoning (BBH). Our approach improves the reasoning capabilities of SLMs without increasing model size or requiring additional training, offering a lightweight and deployment-friendly solution for on-device or resource-constrained environments.
HyColor: An Efficient Heuristic Algorithm for Graph Coloring
Jun 09, 2025



The graph coloring problem (GCP) is a classic combinatorial optimization problem that aims to find the minimum number of colors assigned to vertices of a graph such that no two adjacent vertices receive the same color. GCP has been extensively studied by researchers from various fields, including mathematics, computer science, and biological science. Due to the NP-hard nature, many heuristic algorithms have been proposed to solve GCP. However, existing GCP algorithms focus on either small hard graphs or large-scale sparse graphs (with up to 10^7 vertices). This paper presents an efficient hybrid heuristic algorithm for GCP, named HyColor, which excels in handling large-scale sparse graphs while achieving impressive results on small dense graphs. The efficiency of HyColor comes from the following three aspects: a local decision strategy to improve the lower bound on the chromatic number; a graph-reduction strategy to reduce the working graph; and a k-core and mixed degree-based greedy heuristic for efficiently coloring graphs. HyColor is evaluated against three state-of-the-art GCP algorithms across four benchmarks, comprising three large-scale sparse graph benchmarks and one small dense graph benchmark, totaling 209 instances. The results demonstrate that HyColor consistently outperforms existing heuristic algorithms in both solution accuracy and computational efficiency for the majority of instances. Notably, HyColor achieved the best solutions in 194 instances (over 93%), with 34 of these solutions significantly surpassing those of other algorithms. Furthermore, HyColor successfully determined the chromatic number and achieved optimal coloring in 128 instances.
Speech Token Prediction via Compressed-to-fine Language Modeling for Speech Generation
May 30, 2025Neural audio codecs, used as speech tokenizers, have demonstrated remarkable potential in the field of speech generation. However, to ensure high-fidelity audio reconstruction, neural audio codecs typically encode audio into long sequences of speech tokens, posing a significant challenge for downstream language models in long-context modeling. We observe that speech token sequences exhibit short-range dependency: due to the monotonic alignment between text and speech in text-to-speech (TTS) tasks, the prediction of the current token primarily relies on its local context, while long-range tokens contribute less to the current token prediction and often contain redundant information. Inspired by this observation, we propose a \textbf{compressed-to-fine language modeling} approach to address the challenge of long sequence speech tokens within neural codec language models: (1) \textbf{Fine-grained Initial and Short-range Information}: Our approach retains the prompt and local tokens during prediction to ensure text alignment and the integrity of paralinguistic information; (2) \textbf{Compressed Long-range Context}: Our approach compresses long-range token spans into compact representations to reduce redundant information while preserving essential semantics. Extensive experiments on various neural audio codecs and downstream language models validate the effectiveness and generalizability of the proposed approach, highlighting the importance of token compression in improving speech generation within neural codec language models. The demo of audio samples will be available at https://anonymous.4open.science/r/SpeechTokenPredictionViaCompressedToFinedLM.
Synonymous Variational Inference for Perceptual Image Compression
May 28, 2025Recent contributions of semantic information theory reveal the set-element relationship between semantic and syntactic information, represented as synonymous relationships. In this paper, we propose a synonymous variational inference (SVI) method based on this synonymity viewpoint to re-analyze the perceptual image compression problem. It takes perceptual similarity as a typical synonymous criterion to build an ideal synonymous set (Synset), and approximate the posterior of its latent synonymous representation with a parametric density by minimizing a partial semantic KL divergence. This analysis theoretically proves that the optimization direction of perception image compression follows a triple tradeoff that can cover the existing rate-distortion-perception schemes. Additionally, we introduce synonymous image compression (SIC), a new image compression scheme that corresponds to the analytical process of SVI, and implement a progressive SIC codec to fully leverage the model's capabilities. Experimental results demonstrate comparable rate-distortion-perception performance using a single progressive SIC codec, thus verifying the effectiveness of our proposed analysis method.
SongEval: A Benchmark Dataset for Song Aesthetics Evaluation
May 16, 2025Aesthetics serve as an implicit and important criterion in song generation tasks that reflect human perception beyond objective metrics. However, evaluating the aesthetics of generated songs remains a fundamental challenge, as the appreciation of music is highly subjective. Existing evaluation metrics, such as embedding-based distances, are limited in reflecting the subjective and perceptual aspects that define musical appeal. To address this issue, we introduce SongEval, the first open-source, large-scale benchmark dataset for evaluating the aesthetics of full-length songs. SongEval includes over 2,399 songs in full length, summing up to more than 140 hours, with aesthetic ratings from 16 professional annotators with musical backgrounds. Each song is evaluated across five key dimensions: overall coherence, memorability, naturalness of vocal breathing and phrasing, clarity of song structure, and overall musicality. The dataset covers both English and Chinese songs, spanning nine mainstream genres. Moreover, to assess the effectiveness of song aesthetic evaluation, we conduct experiments using SongEval to predict aesthetic scores and demonstrate better performance than existing objective evaluation metrics in predicting human-perceived musical quality.
WavReward: Spoken Dialogue Models With Generalist Reward Evaluators
May 14, 2025End-to-end spoken dialogue models such as GPT-4o-audio have recently garnered significant attention in the speech domain. However, the evaluation of spoken dialogue models' conversational performance has largely been overlooked. This is primarily due to the intelligent chatbots convey a wealth of non-textual information which cannot be easily measured using text-based language models like ChatGPT. To address this gap, we propose WavReward, a reward feedback model based on audio language models that can evaluate both the IQ and EQ of spoken dialogue systems with speech input. Specifically, 1) based on audio language models, WavReward incorporates the deep reasoning process and the nonlinear reward mechanism for post-training. By utilizing multi-sample feedback via the reinforcement learning algorithm, we construct a specialized evaluator tailored to spoken dialogue models. 2) We introduce ChatReward-30K, a preference dataset used to train WavReward. ChatReward-30K includes both comprehension and generation aspects of spoken dialogue models. These scenarios span various tasks, such as text-based chats, nine acoustic attributes of instruction chats, and implicit chats. WavReward outperforms previous state-of-the-art evaluation models across multiple spoken dialogue scenarios, achieving a substantial improvement about Qwen2.5-Omni in objective accuracy from 55.1$\%$ to 91.5$\%$. In subjective A/B testing, WavReward also leads by a margin of 83$\%$. Comprehensive ablation studies confirm the necessity of each component of WavReward. All data and code will be publicly at https://github.com/jishengpeng/WavReward after the paper is accepted.
UniSymNet: A Unified Symbolic Network Guided by Transformer
May 09, 2025



Symbolic Regression (SR) is a powerful technique for automatically discovering mathematical expressions from input data. Mainstream SR algorithms search for the optimal symbolic tree in a vast function space, but the increasing complexity of the tree structure limits their performance. Inspired by neural networks, symbolic networks have emerged as a promising new paradigm. However, most existing symbolic networks still face certain challenges: binary nonlinear operators $\{\times, \div\}$ cannot be naturally extended to multivariate operators, and training with fixed architecture often leads to higher complexity and overfitting. In this work, we propose a Unified Symbolic Network that unifies nonlinear binary operators into nested unary operators and define the conditions under which UniSymNet can reduce complexity. Moreover, we pre-train a Transformer model with a novel label encoding method to guide structural selection, and adopt objective-specific optimization strategies to learn the parameters of the symbolic network. UniSymNet shows high fitting accuracy, excellent symbolic solution rate, and relatively low expression complexity, achieving competitive performance on low-dimensional Standard Benchmarks and high-dimensional SRBench.