 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Reasoning Capabilities of Small Language Models with Blueprints and Prompt Template Search
Jun 10, 2025
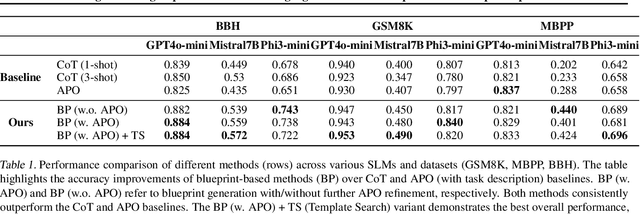


Small language models (SLMs) offer promising and efficient alternatives to large language models (LLMs). However, SLMs' limited capacity restricts their reasoning capabilities and makes them sensitive to prompt variations. To address these challenges, we propose a novel framework that enhances SLM reasoning capabilities through LLM generated blueprints. The blueprints provide structured, high-level reasoning guides that help SLMs systematically tackle related problems. Furthermore, our framework integrates a prompt template search mechanism to mitigate the SLMs' sensitivity to prompt variations. Our framework demonstrates improved SLM performance across various tasks, including math (GSM8K), coding (MBPP), and logic reasoning (BBH). Our approach improves the reasoning capabilities of SLMs without increasing model size or requiring additional training, offering a lightweight and deployment-friendly solution for on-device or resource-constrained environments.
Exploring How LLMs Capture and Represent Domain-Specific Knowledge
Apr 24, 2025



We study whether Large Language Models (LLMs) inherently capture domain-specific nuances in natural language. Our experiments probe the domain sensitivity of LLMs by examining their ability to distinguish queries from different domains using hidden states generated during the prefill phase. We reveal latent domain-related trajectories that indicate the model's internal recognition of query domains. We also study the robustness of these domain representations to variations in prompt styles and sources. Our approach leverages these representations for model selection, mapping the LLM that best matches the domain trace of the input query (i.e., the model with the highest performance on similar traces). Our findings show that LLMs can differentiate queries for related domains, and that the fine-tuned model is not always the most accurate. Unlike previous work, our interpretations apply to both closed and open-ended generative tasks
Ensuring Fair LLM Serving Amid Diverse Applications
Nov 24, 2024



In a multi-tenant large language model (LLM) serving platform hosting diverse applications, some users may submit an excessive number of requests, causing the service to become unavailable to other users and creating unfairness. Existing fairness approaches do not account for variations in token lengths across applications and multiple LLM calls, making them unsuitable for such platforms. To address the fairness challenge, this paper analyzes millions of requests from thousands of users on MS CoPilot, a real-world multi-tenant LLM platform hosted by Microsoft. Our analysis confirms the inadequacy of existing methods and guides the development of FairServe, a system that ensures fair LLM access across diverse applications. FairServe proposes application-characteristic aware request throttling coupled with a weighted service counter based scheduling technique to curb abusive behavior and ensure fairness. Our experimental results on real-world traces demonstrate FairServe's superior performance compared to the state-of-the-art method in ensuring fairness. We are actively working on deploying our system in production, expecting to benefit millions of customers world-wide.
EcoAct: Economic Agent Determines When to Register What Action
Nov 03, 2024



Recent advancements have enabled Large Language Models (LLMs) to function as agents that can perform actions using external tools. This requires registering, i.e., integrating tool information into the LLM context prior to taking actions. Current methods indiscriminately incorporate all candidate tools into the agent's context and retain them across multiple reasoning steps. This process remains opaque to LLM agents and is not integrated into their reasoning procedures, leading to inefficiencies due to increased context length from irrelevant tools. To address this, we introduce EcoAct, a tool using algorithm that allows LLMs to selectively register tools as needed, optimizing context use. By integrating the tool registration process into the reasoning procedure, EcoAct reduces computational costs by over 50% in multiple steps reasoning tasks while maintaining performance, as demonstrated through extensive experiments. Moreover, it can be plugged into any reasoning pipeline with only minor modifications to the prompt, making it applicable to LLM agents now and future.
Hybrid LLM: Cost-Efficient and Quality-Aware Query Routing
Apr 22, 2024Large language models (LLMs) excel in most NLP tasks but also require expensive cloud servers for deployment due to their size, while smaller models that can be deployed on lower cost (e.g., edge) devices, tend to lag behind in terms of response quality. Therefore in this work we propose a hybrid inference approach which combines their respective strengths to save cost and maintain quality. Our approach uses a router that assigns queries to the small or large model based on the predicted query difficulty and the desired quality level. The desired quality level can be tuned dynamically at test time to seamlessly trade quality for cost as per the scenario requirements. In experiments our approach allows us to make up to 40% fewer calls to the large model, with no drop in response quality.
Leveraging Spatial and Temporal Correlations in Sparsified Mean Estimation
Oct 14, 2021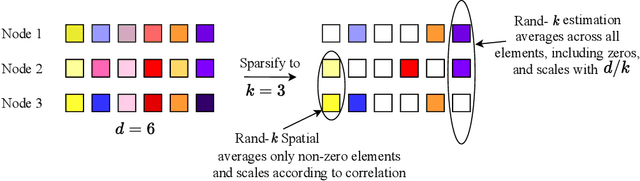
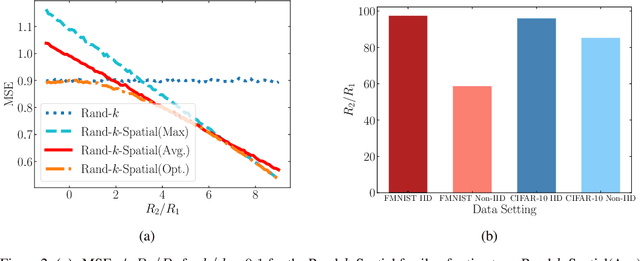
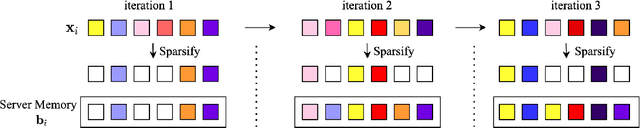
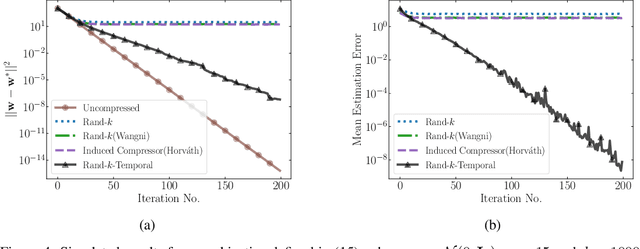
We study the problem of estimating at a central server the mean of a set of vectors distributed across several nodes (one vector per node). When the vectors are high-dimensional, the communication cost of sending entire vectors may be prohibitive, and it may be imperative for them to use sparsification techniques. While most existing work on sparsified mean estimation is agnostic to the characteristics of the data vectors, in many practical applications such as federated learning, there may be spatial correlations (similarities in the vectors sent by different nodes) or temporal correlations (similarities in the data sent by a single node over different iterations of the algorithm) in the data vectors. We leverage these correlations by simply modifying the decoding method used by the server to estimate the mean. We provide an analysis of the resulting estimation error as well as experiments for PCA, K-Means and Logistic Regression, which show that our estimators consistently outperform more sophisticated and expensive sparsification methods.
Probabilistic Neighbourhood Component Analysis: Sample Efficient Uncertainty Estimation in Deep Learning
Jul 18, 2020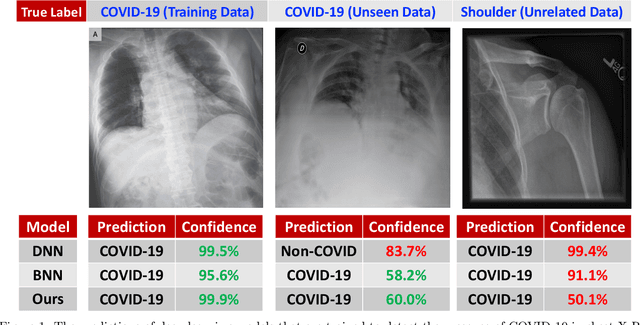

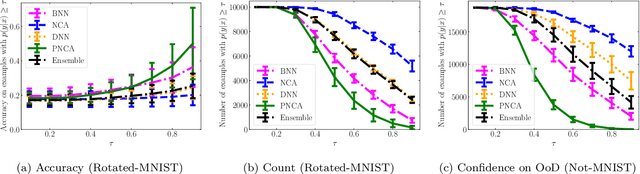
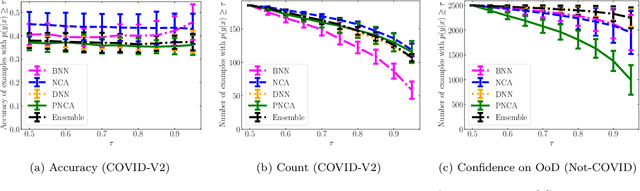
While Deep Neural Networks (DNNs) achieve state-of-the-art accuracy in various applications, they often fall short in accurately estimating their predictive uncertainty and, in turn, fail to recognize when these predictions may be wrong. Several uncertainty-aware models, such as Bayesian Neural Network (BNNs) and Deep Ensembles have been proposed in the literature for quantifying predictive uncertainty. However, research in this area has been largely confined to the big data regime. In this work, we show that the uncertainty estimation capability of state-of-the-art BNNs and Deep Ensemble models degrades significantly when the amount of training data is small. To address the issue of accurate uncertainty estimation in the small-data regime, we propose a probabilistic generalization of the popular sample-efficient non-parametric kNN approach. Our approach enables deep kNN classifier to accurately quantify underlying uncertainties in its prediction. We demonstrate the usefulness of the proposed approach by achieving superior uncertainty quantification as compared to state-of-the-art on a real-world application of COVID-19 diagnosis from chest X-Rays. Our code is available at https://github.com/ankurmallick/sample-efficient-uq
Deep Probabilistic Kernels for Sample-Efficient Learning
Oct 13, 2019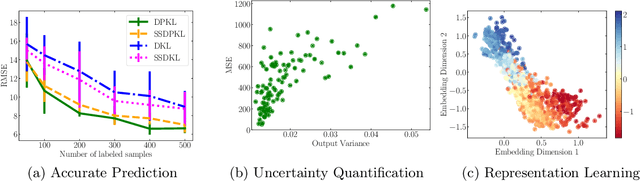
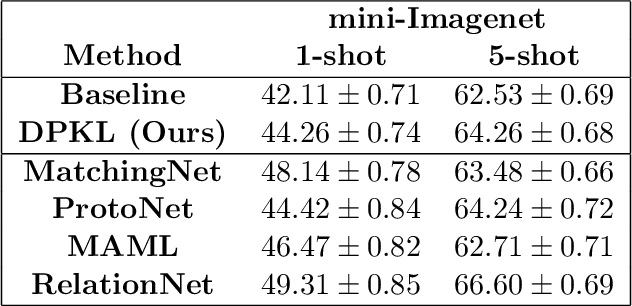
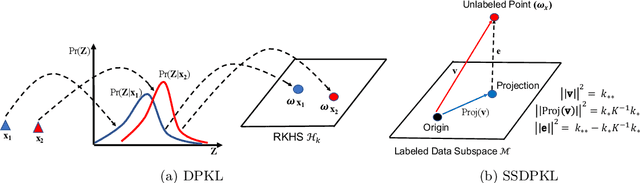
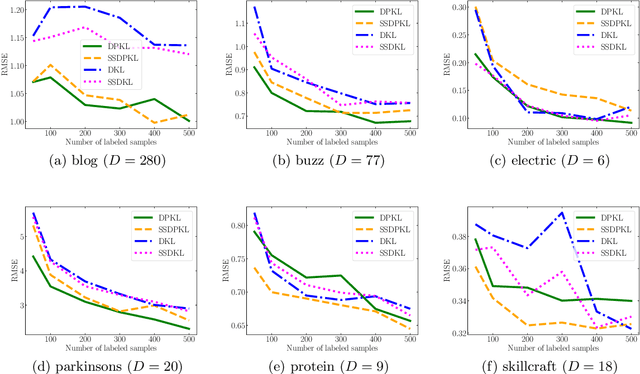
Gaussian Processes (GPs) with an appropriate kernel are known to provide accurate predictions and uncertainty estimates even with very small amounts of labeled data. However, GPs are generally unable to learn a good representation that can encode intricate structures in high dimensional data. The representation power of GPs depends heavily on kernel functions used to quantify the similarity between data points. Traditional GP kernels are not very effective at capturing similarity between high dimensional data points, while methods that use deep neural networks to learn a kernel are not sample-efficient. To overcome these drawbacks, we propose deep probabilistic kernels which use a probabilistic neural network to map high-dimensional data to a probability distribution in a low dimensional subspace, and leverage the rich work on kernels between distributions to capture the similarity between these distributions. Experiments on a variety of datasets show that building a GP using this covariance kernel solves the conflicting problems of representation learning and sample efficiency. Our model can be extended beyond GPs to other small-data paradigms such as few-shot classification where we show competitive performance with state-of-the-art models on the mini-Imagenet dataset.