 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Reasoning Capabilities of Small Language Models with Blueprints and Prompt Template Search
Jun 10, 2025
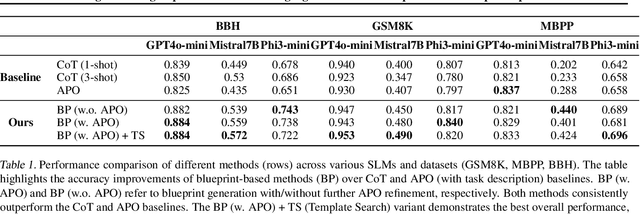


Small language models (SLMs) offer promising and efficient alternatives to large language models (LLMs). However, SLMs' limited capacity restricts their reasoning capabilities and makes them sensitive to prompt variations. To address these challenges, we propose a novel framework that enhances SLM reasoning capabilities through LLM generated blueprints. The blueprints provide structured, high-level reasoning guides that help SLMs systematically tackle related problems. Furthermore, our framework integrates a prompt template search mechanism to mitigate the SLMs' sensitivity to prompt variations. Our framework demonstrates improved SLM performance across various tasks, including math (GSM8K), coding (MBPP), and logic reasoning (BBH). Our approach improves the reasoning capabilities of SLMs without increasing model size or requiring additional training, offering a lightweight and deployment-friendly solution for on-device or resource-constrained environments.
SAVA: Scalable Learning-Agnostic Data Valuation
Jun 03, 2024



Selecting suitable data for training machine learning models is crucial since large, web-scraped, real datasets contain noisy artifacts that affect the quality and relevance of individual data points. These artifacts will impact the performance and generalization of the model. We formulate this problem as a data valuation task, assigning a value to data points in the training set according to how similar or dissimilar they are to a clean and curated validation set. Recently, LAVA (Just et al. 2023) successfully demonstrated the use of optimal transport (OT) between a large noisy training dataset and a clean validation set, to value training data efficiently, without the dependency on model performance. However, the LAVA algorithm requires the whole dataset as an input, this limits its application to large datasets. Inspired by the scalability of stochastic (gradient) approaches which carry out computations on batches of data points instead of the entire dataset, we analogously propose SAVA, a scalable variant of LAVA with its computation on batches of data points. Intuitively, SAVA follows the same scheme as LAVA which leverages the hierarchically defined OT for data valuation. However, while LAVA processes the whole dataset, SAVA divides the dataset into batches of data points, and carries out the OT problem computation on those batches. We perform extensive experiments, to demonstrate that SAVA can scale to large datasets with millions of data points and doesn't trade off data valuation performance.
Fisher Flow Matching for Generative Modeling over Discrete Data
May 23, 2024



Generative modeling over discrete data has recently seen numerous success stories, with applications spanning language modeling, biological sequence design, and graph-structured molecular data. The predominant generative modeling paradigm for discrete data is still autoregressive, with more recent alternatives based on diffusion or flow-matching falling short of their impressive performance in continuous data settings, such as image or video generation. In this work, we introduce Fisher-Flow, a novel flow-matching model for discrete data. Fisher-Flow takes a manifestly geometric perspective by considering categorical distributions over discrete data as points residing on a statistical manifold equipped with its natural Riemannian metric: the $\textit{Fisher-Rao metric}$. As a result, we demonstrate discrete data itself can be continuously reparameterised to points on the positive orthant of the $d$-hypersphere $\mathbb{S}^d_+$, which allows us to define flows that map any source distribution to target in a principled manner by transporting mass along (closed-form) geodesics of $\mathbb{S}^d_+$. Furthermore, the learned flows in Fisher-Flow can be further bootstrapped by leveraging Riemannian optimal transport leading to improved training dynamics. We prove that the gradient flow induced by Fisher-Flow is optimal in reducing the forward KL divergence. We evaluate Fisher-Flow on an array of synthetic and diverse real-world benchmarks, including designing DNA Promoter, and DNA Enhancer sequences. Empirically, we find that Fisher-Flow improves over prior diffusion and flow-matching models on these benchmarks.
Few-Shot Learning Patterns in Financial Time-Series for Trend-Following Strategies
Oct 16, 2023



Forecasting models for systematic trading strategies do not adapt quickly when financial market conditions change, as was seen in the advent of the COVID-19 pandemic in 2020, when market conditions changed dramatically causing many forecasting models to take loss-making positions. To deal with such situations, we propose a novel time-series trend-following forecaster that is able to quickly adapt to new market conditions, referred to as regimes. We leverage recent developments from the deep learning community and use few-shot learning. We propose the Cross Attentive Time-Series Trend Network - X-Trend - which takes positions attending over a context set of financial time-series regimes. X-Trend transfers trends from similar patterns in the context set to make predictions and take positions for a new distinct target regime. X-Trend is able to quickly adapt to new financial regimes with a Sharpe ratio increase of 18.9% over a neural forecaster and 10-fold over a conventional Time-series Momentum strategy during the turbulent market period from 2018 to 2023. Our strategy recovers twice as quickly from the COVID-19 drawdown compared to the neural-forecaster. X-Trend can also take zero-shot positions on novel unseen financial assets obtaining a 5-fold Sharpe ratio increase versus a neural time-series trend forecaster over the same period. X-Trend both forecasts next-day prices and outputs a trading signal. Furthermore, the cross-attention mechanism allows us to interpret the relationship between forecasts and patterns in the context set.
On Sequential Bayesian Inference for Continual Learning
Jan 04, 2023



Sequential Bayesian inference can be used for continual learning to prevent catastrophic forgetting of past tasks and provide an informative prior when learning new tasks. We revisit sequential Bayesian inference and test whether having access to the true posterior is guaranteed to prevent catastrophic forgetting in Bayesian neural networks. To do this we perform sequential Bayesian inference using Hamiltonian Monte Carlo. We propagate the posterior as a prior for new tasks by fitting a density estimator on Hamiltonian Monte Carlo samples. We find that this approach fails to prevent catastrophic forgetting demonstrating the difficulty in performing sequential Bayesian inference in neural networks. From there we study simple analytical examples of sequential Bayesian inference and CL and highlight the issue of model misspecification which can lead to sub-optimal continual learning performance despite exact inference. Furthermore, we discuss how task data imbalances can cause forgetting. From these limitations, we argue that we need probabilistic models of the continual learning generative process rather than relying on sequential Bayesian inference over Bayesian neural network weights. In this vein, we also propose a simple baseline called Prototypical Bayesian Continual Learning, which is competitive with state-of-the-art Bayesian continual learning methods on class incremental continual learning vision benchmarks.
The Surprising Effectiveness of Latent World Models for Continual Reinforcement Learning
Nov 29, 2022



We study the use of model-based reinforcement learning methods, in particular, world models for continual reinforcement learning. In continual reinforcement learning, an agent is required to solve one task and then another sequentially while retaining performance and preventing forgetting on past tasks. World models offer a task-agnostic solution: they do not require knowledge of task changes. World models are a straight-forward baseline for continual reinforcement learning for three main reasons. Firstly, forgetting in the world model is prevented by persisting existing experience replay buffers across tasks, experience from previous tasks is replayed for learning the world model. Secondly, they are sample efficient. Thirdly and finally, they offer a task-agnostic exploration strategy through the uncertainty in the trajectories generated by the world model. We show that world models are a simple and effective continual reinforcement learning baseline. We study their effectiveness on Minigrid and Minihack continual reinforcement learning benchmarks and show that it outperforms state of the art task-agnostic continual reinforcement learning methods.
Efficient Adapter Transfer of Self-Supervised Speech Models for Automatic Speech Recognition
Feb 07, 2022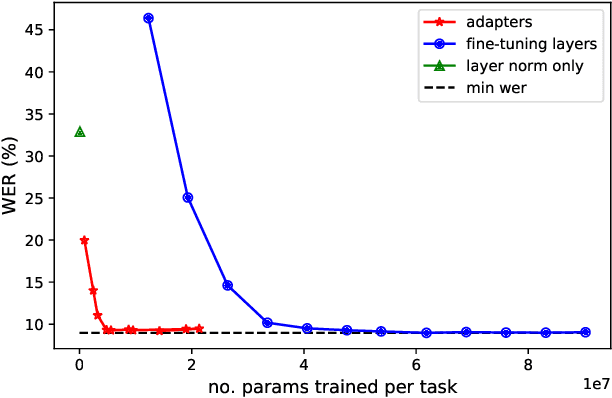
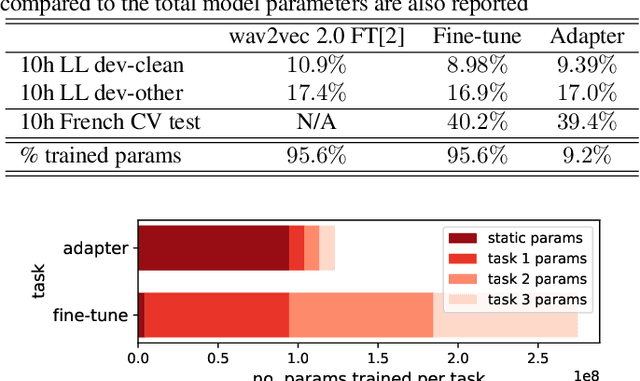

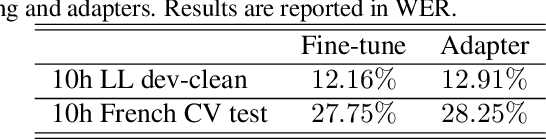
Self-supervised learning (SSL) is a powerful tool that allows learning of underlying representations from unlabeled data. Transformer based models such as wav2vec 2.0 and HuBERT are leading the field in the speech domain. Generally these models are fine-tuned on a small amount of labeled data for a downstream task such as Automatic Speech Recognition (ASR). This involves re-training the majority of the model for each task. Adapters are small lightweight modules which are commonly used in Natural Language Processing (NLP) to adapt pre-trained models to new tasks. In this paper we propose applying adapters to wav2vec 2.0 to reduce the number of parameters required for downstream ASR tasks, and increase scalability of the model to multiple tasks or languages. Using adapters we can perform ASR while training fewer than 10% of parameters per task compared to full fine-tuning with little degradation of performance. Ablations show that applying adapters into just the top few layers of the pre-trained network gives similar performance to full transfer, supporting the theory that higher pre-trained layers encode more phonemic information, and further optimizing efficiency.
Continual-wav2vec2: an Application of Continual Learning for Self-Supervised Automatic Speech Recognition
Jul 26, 2021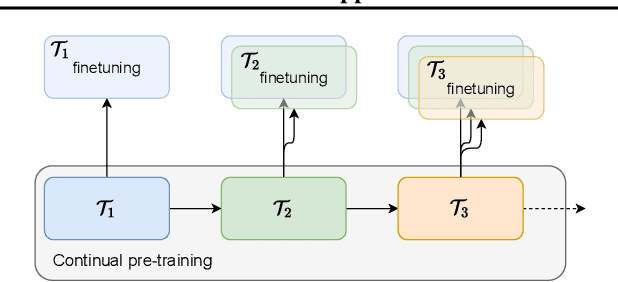
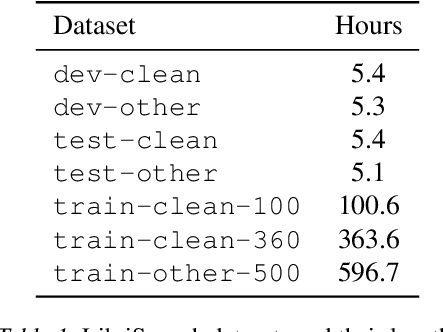
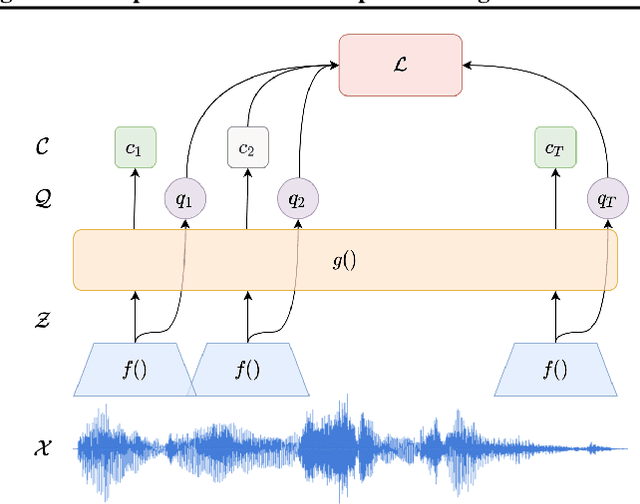
We present a method for continual learning of speech representations for multiple languages using self-supervised learning (SSL) and applying these for automatic speech recognition. There is an abundance of unannotated speech, so creating self-supervised representations from raw audio and finetuning on a small annotated datasets is a promising direction to build speech recognition systems. Wav2vec models perform SSL on raw audio in a pretraining phase and then finetune on a small fraction of annotated data. SSL models have produced state of the art results for ASR. However, these models are very expensive to pretrain with self-supervision. We tackle the problem of learning new language representations continually from audio without forgetting a previous language representation. We use ideas from continual learning to transfer knowledge from a previous task to speed up pretraining a new language task. Our continual-wav2vec2 model can decrease pretraining times by 32% when learning a new language task, and learn this new audio-language representation without forgetting previous language representation.
Same State, Different Task: Continual Reinforcement Learning without Interference
Jun 05, 2021



Continual Learning (CL) considers the problem of training an agent sequentially on a set of tasks while seeking to retain performance on all previous tasks. A key challenge in CL is catastrophic forgetting, which arises when performance on a previously mastered task is reduced when learning a new task. While a variety of methods exist to combat forgetting, in some cases tasks are fundamentally incompatible with each other and thus cannot be learnt by a single policy. This can occur, in reinforcement learning (RL) when an agent may be rewarded for achieving different goals from the same observation. In this paper we formalize this ``interference'' as distinct from the problem of forgetting. We show that existing CL methods based on single neural network predictors with shared replay buffers fail in the presence of interference. Instead, we propose a simple method, OWL, to address this challenge. OWL learns a factorized policy, using shared feature extraction layers, but separate heads, each specializing on a new task. The separate heads in OWL are used to prevent interference. At test time, we formulate policy selection as a multi-armed bandit problem, and show it is possible to select the best policy for an unknown task using feedback from the environment. The use of bandit algorithms allows the OWL agent to constructively re-use different continually learnt policies at different times during an episode. We show in multiple RL environments that existing replay based CL methods fail, while OWL is able to achieve close to optimal performance when training sequentially.
Indian Buffet Neural Networks for Continual Learning
Dec 04, 2019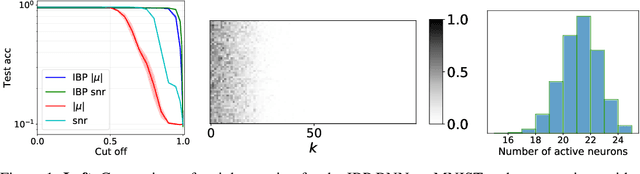
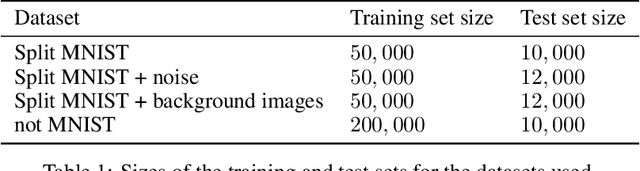
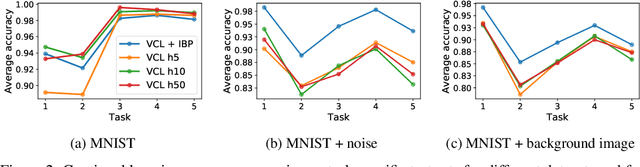
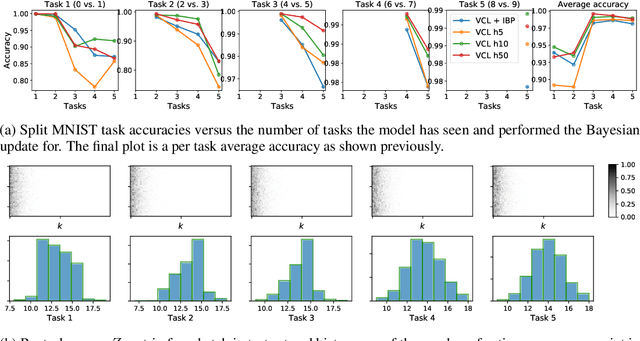
We place an Indian Buffet Process (IBP) prior over the neural structure of a Bayesian Neural Network (BNN), thus allowing the complexity of the BNN to increase and decrease automatically. We apply this methodology to the problem of resource allocation in continual learning, where new tasks occur and the network requires extra resources. Our BNN exploits online variational inference with relaxations to the Bernoulli and Beta distributions (which constitute the IBP prior), so allowing the use of the reparameterisation trick to learn variational posteriors via gradient-based methods. As we automatically learn the number of weights in the BNN, overfitting and underfitting problems are largely overcome. We show empirically that the method offers competitive results compared to Variational Continual Learning (VCL) in some settings.