 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransparentGS: Fast Inverse Rendering of Transparent Objects with Gaussians
May 01, 2025



The emergence of neural and Gaussian-based radiance field methods has led to considerable advancements in novel view synthesis and 3D object reconstruction. Nonetheless, specular reflection and refraction continue to pose significant challenges due to the instability and incorrect overfitting of radiance fields to high-frequency light variations. Currently, even 3D Gaussian Splatting (3D-GS), as a powerful and efficient tool, falls short in recovering transparent objects with nearby contents due to the existence of apparent secondary ray effects. To address this issue, we propose TransparentGS, a fast inverse rendering pipeline for transparent objects based on 3D-GS. The main contributions are three-fold. Firstly, an efficient representation of transparent objects, transparent Gaussian primitives, is designed to enable specular refraction through a deferred refraction strategy. Secondly, we leverage Gaussian light field probes (GaussProbe) to encode both ambient light and nearby contents in a unified framework. Thirdly, a depth-based iterative probes query (IterQuery) algorithm is proposed to reduce the parallax errors in our probe-based framework. Experiments demonstrate the speed and accuracy of our approach in recovering transparent objects from complex environments, as well as several applications in computer graphics and vision.
CombatVLA: An Efficient Vision-Language-Action Model for Combat Tasks in 3D Action Role-Playing Games
Mar 12, 2025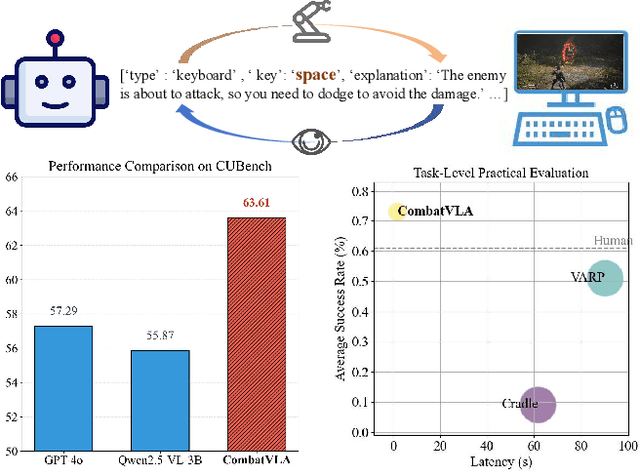
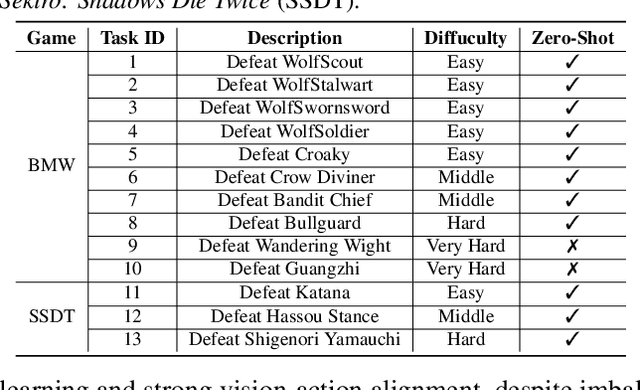
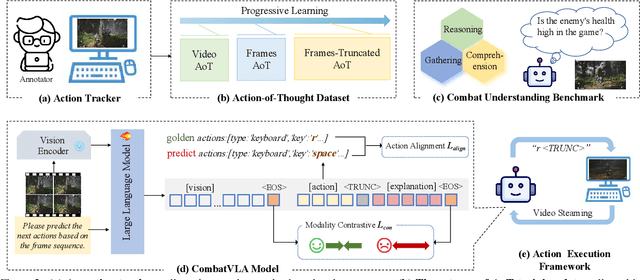
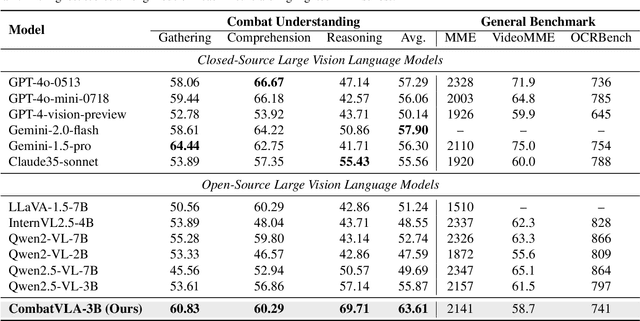
Recent advances in Vision-Language-Action models (VLAs) have expanded the capabilities of embodied intelligence. However, significant challenges remain in real-time decision-making in complex 3D environments, which demand second-level responses, high-resolution perception, and tactical reasoning under dynamic conditions. To advance the field, we introduce CombatVLA, an efficient VLA model optimized for combat tasks in 3D action role-playing games(ARPGs). Specifically, our CombatVLA is a 3B model trained on video-action pairs collected by an action tracker, where the data is formatted as action-of-thought (AoT) sequences. Thereafter, CombatVLA seamlessly integrates into an action execution framework, allowing efficient inference through our truncated AoT strategy. Experimental results demonstrate that CombatVLA not only outperforms all existing models on the combat understanding benchmark but also achieves a 50-fold acceleration in game combat. Moreover, it has a higher task success rate than human players. We will open-source all resources, including the action tracker, dataset, benchmark, model weights, training code, and the implementation of the framework at https://combatvla.github.io/.
"I know myself better, but not really greatly": Using LLMs to Detect and Explain LLM-Generated Texts
Feb 18, 2025Large language models (LLMs) have demonstrated impressive capabilities in generating human-like texts, but the potential misuse of such LLM-generated texts raises the need to distinguish between human-generated and LLM-generated content. This paper explores the detection and explanation capabilities of LLM-based detectors of LLM-generated texts, in the context of a binary classification task (human-generated texts vs LLM-generated texts) and a ternary classification task (human-generated texts, LLM-generated texts, and undecided). By evaluating on six close/open-source LLMs with different sizes, our findings reveal that while self-detection consistently outperforms cross-detection, i.e., LLMs can detect texts generated by themselves more accurately than those generated by other LLMs, the performance of self-detection is still far from ideal, indicating that further improvements are needed. We also show that extending the binary to the ternary classification task with a new class "Undecided" can enhance both detection accuracy and explanation quality, with improvements being statistically significant and consistent across all LLMs. We finally conducted comprehensive qualitative and quantitative analyses on the explanation errors, which are categorized into three types: reliance on inaccurate features (the most frequent error), hallucinations, and incorrect reasoning. These findings with our human-annotated dataset emphasize the need for further research into improving both self-detection and self-explanation, particularly to address overfitting issues that may hinder generalization.
ArtCrafter: Text-Image Aligning Style Transfer via Embedding Reframing
Jan 03, 2025



Recent years have witnessed significant advancements in text-guided style transfer, primarily attributed to innovations in diffusion models. These models excel in conditional guidance, utilizing text or images to direct the sampling process. However, despite their capabilities, direct conditional guidance approaches often face challenges in balancing the expressiveness of textual semantics with the diversity of output results while capturing stylistic features. To address these challenges, we introduce ArtCrafter, a novel framework for text-to-image style transfer. Specifically, we introduce an attention-based style extraction module, meticulously engineered to capture the subtle stylistic elements within an image. This module features a multi-layer architecture that leverages the capabilities of perceiver attention mechanisms to integrate fine-grained information. Additionally, we present a novel text-image aligning augmentation component that adeptly balances control over both modalities, enabling the model to efficiently map image and text embeddings into a shared feature space. We achieve this through attention operations that enable smooth information flow between modalities. Lastly, we incorporate an explicit modulation that seamlessly blends multimodal enhanced embeddings with original embeddings through an embedding reframing design, empowering the model to generate diverse outputs. Extensive experiments demonstrate that ArtCrafter yields impressive results in visual stylization, exhibiting exceptional levels of stylistic intensity, controllability, and diversity.
InterDance:Reactive 3D Dance Generation with Realistic Duet Interactions
Dec 22, 2024



Humans perform a variety of interactive motions, among which duet dance is one of the most challenging interactions. However, in terms of human motion generative models, existing works are still unable to generate high-quality interactive motions, especially in the field of duet dance. On the one hand, it is due to the lack of large-scale high-quality datasets. On the other hand, it arises from the incomplete representation of interactive motion and the lack of fine-grained optimization of interactions. To address these challenges, we propose, InterDance, a large-scale duet dance dataset that significantly enhances motion quality, data scale, and the variety of dance genres. Built upon this dataset, we propose a new motion representation that can accurately and comprehensively describe interactive motion. We further introduce a diffusion-based framework with an interaction refinement guidance strategy to optimize the realism of interactions progressively. Extensive experiments demonstrate the effectiveness of our dataset and algorithm.
Large Language Models and Artificial Intelligence Generated Content Technologies Meet Communication Networks
Nov 12, 2024



Artificial intelligence generated content (AIGC) technologies, with a predominance of large language models (LLMs), have demonstrated remarkable performance improvements in various applications, which have attracted great interests from both academia and industry. Although some noteworthy advancements have been made in this area, a comprehensive exploration of the intricate relationship between AIGC and communication networks remains relatively limited. To address this issue, this paper conducts an exhaustive survey from dual standpoints: firstly, it scrutinizes the integration of LLMs and AIGC technologies within the domain of communication networks; secondly, it investigates how the communication networks can further bolster the capabilities of LLMs and AIGC. Additionally, this research explores the promising applications along with the challenges encountered during the incorporation of these AI technologies into communication networks. Through these detailed analyses, our work aims to deepen the understanding of how LLMs and AIGC can synergize with and enhance the development of advanced intelligent communication networks, contributing to a more profound comprehension of next-generation intelligent communication networks.
Lodge++: High-quality and Long Dance Generation with Vivid Choreography Patterns
Oct 27, 2024



We propose Lodge++, a choreography framework to generate high-quality, ultra-long, and vivid dances given the music and desired genre. To handle the challenges in computational efficiency, the learning of complex and vivid global choreography patterns, and the physical quality of local dance movements, Lodge++ adopts a two-stage strategy to produce dances from coarse to fine. In the first stage, a global choreography network is designed to generate coarse-grained dance primitives that capture complex global choreography patterns. In the second stage, guided by these dance primitives, a primitive-based dance diffusion model is proposed to further generate high-quality, long-sequence dances in parallel, faithfully adhering to the complex choreography patterns. Additionally, to improve the physical plausibility, Lodge++ employs a penetration guidance module to resolve character self-penetration, a foot refinement module to optimize foot-ground contact, and a multi-genre discriminator to maintain genre consistency throughout the dance. Lodge++ is validated by extensive experiments, which show that our method can rapidly generate ultra-long dances suitable for various dance genres, ensuring well-organized global choreography patterns and high-quality local motion.
GlossyGS: Inverse Rendering of Glossy Objects with 3D Gaussian Splatting
Oct 17, 2024



Reconstructing objects from posed images is a crucial and complex task in computer graphics and computer vision. While NeRF-based neural reconstruction methods have exhibited impressive reconstruction ability, they tend to be time-comsuming. Recent strategies have adopted 3D Gaussian Splatting (3D-GS) for inverse rendering, which have led to quick and effective outcomes. However, these techniques generally have difficulty in producing believable geometries and materials for glossy objects, a challenge that stems from the inherent ambiguities of inverse rendering. To address this, we introduce GlossyGS, an innovative 3D-GS-based inverse rendering framework that aims to precisely reconstruct the geometry and materials of glossy objects by integrating material priors. The key idea is the use of micro-facet geometry segmentation prior, which helps to reduce the intrinsic ambiguities and improve the decomposition of geometries and materials. Additionally, we introduce a normal map prefiltering strategy to more accurately simulate the normal distribution of reflective surfaces. These strategies are integrated into a hybrid geometry and material representation that employs both explicit and implicit methods to depict glossy objects. We demonstrate through quantitative analysis and qualitative visualization that the proposed method is effective to reconstruct high-fidelity geometries and materials of glossy objects, and performs favorably against state-of-the-arts.
Parameterize Structure with Differentiable Template for 3D Shape Generation
Oct 15, 2024



Structural representation is crucial for reconstructing and generating editable 3D shapes with part semantics. Recent 3D shape generation works employ complicated networks and structure definitions relying on hierarchical annotations and pay less attention to the details inside parts. In this paper, we propose the method that parameterizes the shared structure in the same category using a differentiable template and corresponding fixed-length parameters. Specific parameters are fed into the template to calculate cuboids that indicate a concrete shape. We utilize the boundaries of three-view drawings of each cuboid to further describe the inside details. Shapes are represented with the parameters and three-view details inside cuboids, from which the SDF can be calculated to recover the object. Benefiting from our fixed-length parameters and three-view details, our networks for reconstruction and generation are simple and effective to learn the latent space. Our method can reconstruct or generate diverse shapes with complicated details, and interpolate them smoothly. Extensive evaluations demonstrate the superiority of our method on reconstruction from point cloud, generation, and interpolation.
IRSAM: Advancing Segment Anything Model for Infrared Small Target Detection
Jul 10, 2024



The recent Segment Anything Model (SAM) is a significant advancement in natural image segmentation, exhibiting potent zero-shot performance suitable for various downstream image segmentation tasks. However, directly utilizing the pretrained SAM for Infrared Small Target Detection (IRSTD) task falls short in achieving satisfying performance due to a notable domain gap between natural and infrared images. Unlike a visible light camera, a thermal imager reveals an object's temperature distribution by capturing infrared radiation. Small targets often show a subtle temperature transition at the object's boundaries. To address this issue, we propose the IRSAM model for IRSTD, which improves SAM's encoder-decoder architecture to learn better feature representation of infrared small objects. Specifically, we design a Perona-Malik diffusion (PMD)-based block and incorporate it into multiple levels of SAM's encoder to help it capture essential structural features while suppressing noise. Additionally, we devise a Granularity-Aware Decoder (GAD) to fuse the multi-granularity feature from the encoder to capture structural information that may be lost in long-distance modeling. Extensive experiments on the public datasets, including NUAA-SIRST, NUDT-SIRST, and IRSTD-1K, validate the design choice of IRSAM and its significant superiority over representative state-of-the-art methods. The source code are available at: github.com/IPIC-Lab/IRSAM.