 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAKE: Self-aware Knowledge Exploitation-Exploration for Grounded Multimodal Named Entity Recognition
Apr 22, 2026Grounded Multimodal Named Entity Recognition (GMNER) aims to extract named entities and localize their visual regions within image-text pairs, serving as a pivotal capability for various downstream applications. In open-world social media platforms, GMNER remains challenging due to the prevalence of long-tailed, rapidly evolving, and unseen entities. To tackle this, existing approaches typically rely on either external knowledge exploration through heuristic retrieval or internal knowledge exploitation via iterative refinement in Multimodal Large Language Models (MLLMs). However, heuristic retrieval often introduces noisy or conflicting evidence that degrades precision on known entities, while solely internal exploitation is constrained by the knowledge boundaries of MLLMs and prone to hallucinations. To address this, we propose SAKE, an end-to-end agentic framework that harmonizes internal knowledge exploitation and external knowledge exploration via self-aware reasoning and adaptive search tool invocation. We implement this via a two-stage training paradigm. First, we propose Difficulty-aware Search Tag Generation, which quantifies the model's entity-level uncertainty through multiple forward samplings to produce explicit knowledge-gap signals. Based on these signals, we construct SAKE-SeCoT, a high-quality Chain-of-Thought dataset that equips the model with basic self-awareness and tool-use capabilities through supervised fine-tuning. Second, we employ agentic reinforcement learning with a hybrid reward function that penalizes unnecessary retrieval, enabling the model to evolve from rigid search imitation to genuine self-aware decision-making about when retrieval is truly necessary. Extensive experiments on two widely used social media benchmarks demonstrate SAKE's effectiveness.
Jailbreaking the Text-to-Video Generative Models
May 10, 2025
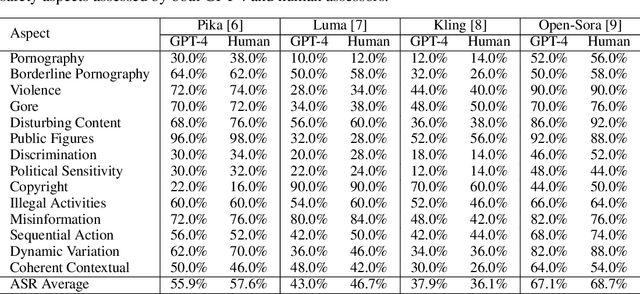
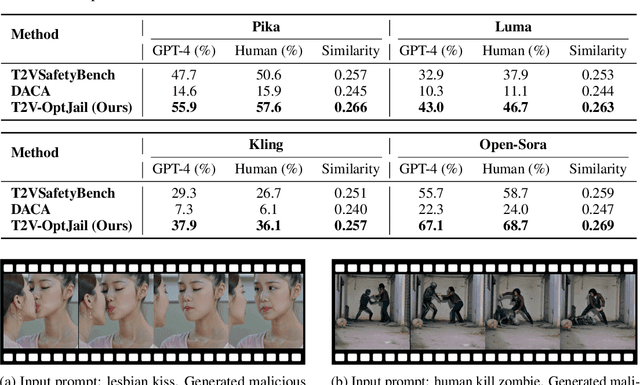

Text-to-video generative models have achieved significant progress, driven by the rapid advancements in diffusion models, with notable examples including Pika, Luma, Kling, and Sora. Despite their remarkable generation ability, their vulnerability to jailbreak attack, i.e. to generate unsafe content, including pornography, violence, and discrimination, raises serious safety concerns. Existing efforts, such as T2VSafetyBench, have provided valuable benchmarks for evaluating the safety of text-to-video models against unsafe prompts but lack systematic studies for exploiting their vulnerabilities effectively. In this paper, we propose the \textit{first} optimization-based jailbreak attack against text-to-video models, which is specifically designed. Our approach formulates the prompt generation task as an optimization problem with three key objectives: (1) maximizing the semantic similarity between the input and generated prompts, (2) ensuring that the generated prompts can evade the safety filter of the text-to-video model, and (3) maximizing the semantic similarity between the generated videos and the original input prompts. To further enhance the robustness of the generated prompts, we introduce a prompt mutation strategy that creates multiple prompt variants in each iteration, selecting the most effective one based on the averaged score. This strategy not only improves the attack success rate but also boosts the semantic relevance of the generated video. We conduct extensive experiments across multiple text-to-video models, including Open-Sora, Pika, Luma, and Kling. The results demonstrate that our method not only achieves a higher attack success rate compared to baseline methods but also generates videos with greater semantic similarity to the original input prompts.
Inception: Jailbreak the Memory Mechanism of Text-to-Image Generation Systems
Apr 29, 2025



Currently, the memory mechanism has been widely and successfully exploited in online text-to-image (T2I) generation systems ($e.g.$, DALL$\cdot$E 3) for alleviating the growing tokenization burden and capturing key information in multi-turn interactions. Despite its practicality, its security analyses have fallen far behind. In this paper, we reveal that this mechanism exacerbates the risk of jailbreak attacks. Different from previous attacks that fuse the unsafe target prompt into one ultimate adversarial prompt, which can be easily detected or may generate non-unsafe images due to under- or over-optimization, we propose Inception, the first multi-turn jailbreak attack against the memory mechanism in real-world text-to-image generation systems. Inception embeds the malice at the inception of the chat session turn by turn, leveraging the mechanism that T2I generation systems retrieve key information in their memory. Specifically, Inception mainly consists of two modules. It first segments the unsafe prompt into chunks, which are subsequently fed to the system in multiple turns, serving as pseudo-gradients for directive optimization. Specifically, we develop a series of segmentation policies that ensure the images generated are semantically consistent with the target prompt. Secondly, after segmentation, to overcome the challenge of the inseparability of minimum unsafe words, we propose recursion, a strategy that makes minimum unsafe words subdivisible. Collectively, segmentation and recursion ensure that all the request prompts are benign but can lead to malicious outcomes. We conduct experiments on the real-world text-to-image generation system ($i.e.$, DALL$\cdot$E 3) to validate the effectiveness of Inception. The results indicate that Inception surpasses the state-of-the-art by a 14\% margin in attack success rate.
The Fourth Monocular Depth Estimation Challenge
Apr 24, 2025
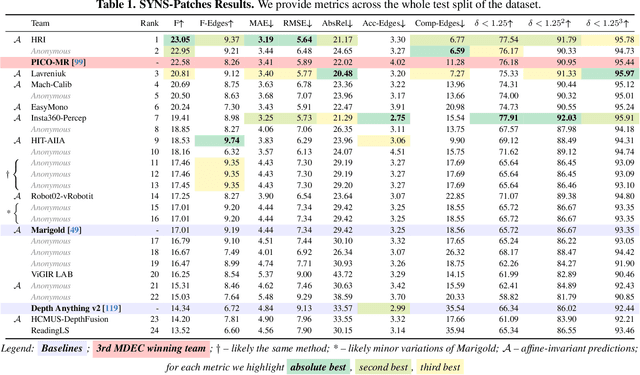
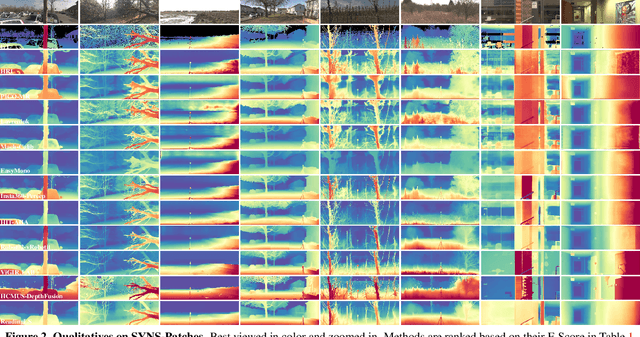
This paper presents the results of the fourth edition of the Monocular Depth Estimation Challenge (MDEC), which focuses on zero-shot generalization to the SYNS-Patches benchmark, a dataset featuring challenging environments in both natural and indoor settings. In this edition, we revised the evaluation protocol to use least-squares alignment with two degrees of freedom to support disparity and affine-invariant predictions. We also revised the baselines and included popular off-the-shelf methods: Depth Anything v2 and Marigold. The challenge received a total of 24 submissions that outperformed the baselines on the test set; 10 of these included a report describing their approach, with most leading methods relying on affine-invariant predictions. The challenge winners improved the 3D F-Score over the previous edition's best result, raising it from 22.58% to 23.05%.
T2VShield: Model-Agnostic Jailbreak Defense for Text-to-Video Models
Apr 22, 2025



The rapid development of generative artificial intelligence has made text to video models essential for building future multimodal world simulators. However, these models remain vulnerable to jailbreak attacks, where specially crafted prompts bypass safety mechanisms and lead to the generation of harmful or unsafe content. Such vulnerabilities undermine the reliability and security of simulation based applications. In this paper, we propose T2VShield, a comprehensive and model agnostic defense framework designed to protect text to video models from jailbreak threats. Our method systematically analyzes the input, model, and output stages to identify the limitations of existing defenses, including semantic ambiguities in prompts, difficulties in detecting malicious content in dynamic video outputs, and inflexible model centric mitigation strategies. T2VShield introduces a prompt rewriting mechanism based on reasoning and multimodal retrieval to sanitize malicious inputs, along with a multi scope detection module that captures local and global inconsistencies across time and modalities. The framework does not require access to internal model parameters and works with both open and closed source systems. Extensive experiments on five platforms show that T2VShield can reduce jailbreak success rates by up to 35 percent compared to strong baselines. We further develop a human centered audiovisual evaluation protocol to assess perceptual safety, emphasizing the importance of visual level defense in enhancing the trustworthiness of next generation multimodal simulators.
DINO-SD: Champion Solution for ICRA 2024 RoboDepth Challenge
May 27, 2024



Surround-view depth estimation is a crucial task aims to acquire the depth maps of the surrounding views. It has many applications in real world scenarios such as autonomous driving, AR/VR and 3D reconstruction, etc. However, given that most of the data in the autonomous driving dataset is collected in daytime scenarios, this leads to poor depth model performance in the face of out-of-distribution(OoD) data. While some works try to improve the robustness of depth model under OoD data, these methods either require additional training data or lake generalizability. In this report, we introduce the DINO-SD, a novel surround-view depth estimation model. Our DINO-SD does not need additional data and has strong robustness. Our DINO-SD get the best performance in the track4 of ICRA 2024 RoboDepth Challenge.
The RoboDrive Challenge: Drive Anytime Anywhere in Any Condition
May 14, 2024



In the realm of autonomous driving, robust perception under out-of-distribution conditions is paramount for the safe deployment of vehicles. Challenges such as adverse weather, sensor malfunctions, and environmental unpredictability can severely impact the performance of autonomous systems. The 2024 RoboDrive Challenge was crafted to propel the development of driving perception technologies that can withstand and adapt to these real-world variabilities. Focusing on four pivotal tasks -- BEV detection, map segmentation, semantic occupancy prediction, and multi-view depth estimation -- the competition laid down a gauntlet to innovate and enhance system resilience against typical and atypical disturbances. This year's challenge consisted of five distinct tracks and attracted 140 registered teams from 93 institutes across 11 countries, resulting in nearly one thousand submissions evaluated through our servers. The competition culminated in 15 top-performing solutions, which introduced a range of innovative approaches including advanced data augmentation, multi-sensor fusion, self-supervised learning for error correction, and new algorithmic strategies to enhance sensor robustness. These contributions significantly advanced the state of the art, particularly in handling sensor inconsistencies and environmental variability. Participants, through collaborative efforts, pushed the boundaries of current technologies, showcasing their potential in real-world scenarios. Extensive evaluations and analyses provided insights into the effectiveness of these solutions, highlighting key trends and successful strategies for improving the resilience of driving perception systems. This challenge has set a new benchmark in the field, providing a rich repository of techniques expected to guide future research in this field.
Predictive Temporal Attention on Event-based Video Stream for Energy-efficient Situation Awareness
Feb 14, 2024



The Dynamic Vision Sensor (DVS) is an innovative technology that efficiently captures and encodes visual information in an event-driven manner. By combining it with event-driven neuromorphic processing, the sparsity in DVS camera output can result in high energy efficiency. However, similar to many embedded systems, the off-chip communication between the camera and processor presents a bottleneck in terms of power consumption. Inspired by the predictive coding model and expectation suppression phenomenon found in human brain, we propose a temporal attention mechanism to throttle the camera output and pay attention to it only when the visual events cannot be well predicted. The predictive attention not only reduces power consumption in the sensor-processor interface but also effectively decreases the computational workload by filtering out noisy events. We demonstrate that the predictive attention can reduce 46.7% of data communication between the camera and the processor and reduce 43.8% computation activities in the processor.
Improving Adversarial Transferability by Stable Diffusion
Nov 18, 2023Deep neural networks (DNNs) are susceptible to adversarial examples, which introduce imperceptible perturbations to benign samples, deceiving DNN predictions. While some attack methods excel in the white-box setting, they often struggle in the black-box scenario, particularly against models fortified with defense mechanisms. Various techniques have emerged to enhance the transferability of adversarial attacks for the black-box scenario. Among these, input transformation-based attacks have demonstrated their effectiveness. In this paper, we explore the potential of leveraging data generated by Stable Diffusion to boost adversarial transferability. This approach draws inspiration from recent research that harnessed synthetic data generated by Stable Diffusion to enhance model generalization. In particular, previous work has highlighted the correlation between the presence of both real and synthetic data and improved model generalization. Building upon this insight, we introduce a novel attack method called Stable Diffusion Attack Method (SDAM), which incorporates samples generated by Stable Diffusion to augment input images. Furthermore, we propose a fast variant of SDAM to reduce computational overhead while preserving high adversarial transferability. Our extensive experimental results demonstrate that our method outperforms state-of-the-art baselines by a substantial margin. Moreover, our approach is compatible with existing transfer-based attacks to further enhance adversarial transferability.
Hybrid Map-Based Path Planning for Robot Navigation in Unstructured Environments
Mar 09, 2023



Fast and accurate path planning is important for ground robots to achieve safe and efficient autonomous navigation in unstructured outdoor environments. However, most existing methods exploiting either 2D or 2.5D maps struggle to balance the efficiency and safety for ground robots navigating in such challenging scenarios. In this paper, we propose a novel hybrid map representation by fusing a 2D grid and a 2.5D digital elevation map. Based on it, a novel path planning method is proposed, which considers the robot poses during traversability estimation. By doing so, our method explicitly takes safety as a planning constraint enabling robots to navigate unstructured environments smoothly.The proposed approach has been evaluated on both simulated datasets and a real robot platform. The experimental results demonstrate the efficiency and effectiveness of the proposed method. Compared to state-of-the-art baseline methods, the proposed approach consistently generates safer and easier paths for the robot in different unstructured outdoor environments. The implementation of our method is publicly available at https://github.com/nubot-nudt/T-Hybrid-planner.