 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJailbreaking the Text-to-Video Generative Models
May 10, 2025
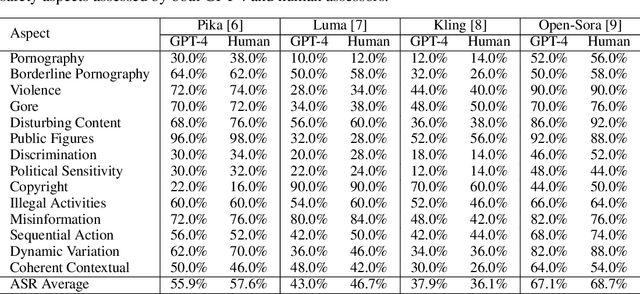
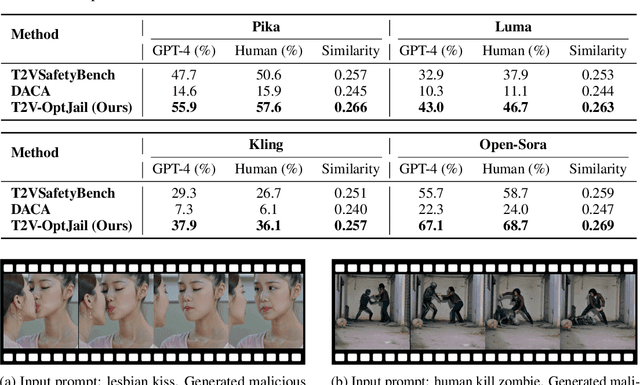

Text-to-video generative models have achieved significant progress, driven by the rapid advancements in diffusion models, with notable examples including Pika, Luma, Kling, and Sora. Despite their remarkable generation ability, their vulnerability to jailbreak attack, i.e. to generate unsafe content, including pornography, violence, and discrimination, raises serious safety concerns. Existing efforts, such as T2VSafetyBench, have provided valuable benchmarks for evaluating the safety of text-to-video models against unsafe prompts but lack systematic studies for exploiting their vulnerabilities effectively. In this paper, we propose the \textit{first} optimization-based jailbreak attack against text-to-video models, which is specifically designed. Our approach formulates the prompt generation task as an optimization problem with three key objectives: (1) maximizing the semantic similarity between the input and generated prompts, (2) ensuring that the generated prompts can evade the safety filter of the text-to-video model, and (3) maximizing the semantic similarity between the generated videos and the original input prompts. To further enhance the robustness of the generated prompts, we introduce a prompt mutation strategy that creates multiple prompt variants in each iteration, selecting the most effective one based on the averaged score. This strategy not only improves the attack success rate but also boosts the semantic relevance of the generated video. We conduct extensive experiments across multiple text-to-video models, including Open-Sora, Pika, Luma, and Kling. The results demonstrate that our method not only achieves a higher attack success rate compared to baseline methods but also generates videos with greater semantic similarity to the original input prompts.
T2VShield: Model-Agnostic Jailbreak Defense for Text-to-Video Models
Apr 22, 2025



The rapid development of generative artificial intelligence has made text to video models essential for building future multimodal world simulators. However, these models remain vulnerable to jailbreak attacks, where specially crafted prompts bypass safety mechanisms and lead to the generation of harmful or unsafe content. Such vulnerabilities undermine the reliability and security of simulation based applications. In this paper, we propose T2VShield, a comprehensive and model agnostic defense framework designed to protect text to video models from jailbreak threats. Our method systematically analyzes the input, model, and output stages to identify the limitations of existing defenses, including semantic ambiguities in prompts, difficulties in detecting malicious content in dynamic video outputs, and inflexible model centric mitigation strategies. T2VShield introduces a prompt rewriting mechanism based on reasoning and multimodal retrieval to sanitize malicious inputs, along with a multi scope detection module that captures local and global inconsistencies across time and modalities. The framework does not require access to internal model parameters and works with both open and closed source systems. Extensive experiments on five platforms show that T2VShield can reduce jailbreak success rates by up to 35 percent compared to strong baselines. We further develop a human centered audiovisual evaluation protocol to assess perceptual safety, emphasizing the importance of visual level defense in enhancing the trustworthiness of next generation multimodal simulators.
Large Language Model Agent: A Survey on Methodology, Applications and Challenges
Mar 27, 2025The era of intelligent agents is upon us, driven by revolutionary advancements in large language models. Large Language Model (LLM) agents, with goal-driven behaviors and dynamic adaptation capabilities, potentially represent a critical pathway toward artificial general intelligence. This survey systematically deconstructs LLM agent systems through a methodology-centered taxonomy, linking architectural foundations, collaboration mechanisms, and evolutionary pathways. We unify fragmented research threads by revealing fundamental connections between agent design principles and their emergent behaviors in complex environments. Our work provides a unified architectural perspective, examining how agents are constructed, how they collaborate, and how they evolve over time, while also addressing evaluation methodologies, tool applications, practical challenges, and diverse application domains. By surveying the latest developments in this rapidly evolving field, we offer researchers a structured taxonomy for understanding LLM agents and identify promising directions for future research. The collection is available at https://github.com/luo-junyu/Awesome-Agent-Papers.
A Survey of Multimodal-Guided Image Editing with Text-to-Image Diffusion Models
Jun 20, 2024



Image editing aims to edit the given synthetic or real image to meet the specific requirements from users. It is widely studied in recent years as a promising and challenging field of Artificial Intelligence Generative Content (AIGC). Recent significant advancement in this field is based on the development of text-to-image (T2I) diffusion models, which generate images according to text prompts. These models demonstrate remarkable generative capabilities and have become widely used tools for image editing. T2I-based image editing methods significantly enhance editing performance and offer a user-friendly interface for modifying content guided by multimodal inputs. In this survey, we provide a comprehensive review of multimodal-guided image editing techniques that leverage T2I diffusion models. First, we define the scope of image editing from a holistic perspective and detail various control signals and editing scenarios. We then propose a unified framework to formalize the editing process, categorizing it into two primary algorithm families. This framework offers a design space for users to achieve specific goals. Subsequently, we present an in-depth analysis of each component within this framework, examining the characteristics and applicable scenarios of different combinations. Given that training-based methods learn to directly map the source image to target one under user guidance, we discuss them separately, and introduce injection schemes of source image in different scenarios. Additionally, we review the application of 2D techniques to video editing, highlighting solutions for inter-frame inconsistency. Finally, we discuss open challenges in the field and suggest potential future research directions. We keep tracing related works at https://github.com/xinchengshuai/Awesome-Image-Editing.
Seeing What You Miss: Vision-Language Pre-training with Semantic Completion Learning
Nov 24, 2022



Cross-modal alignment is essential for vision-language pre-training (VLP) models to learn the correct corresponding information across different modalities. For this purpose, inspired by the success of masked language modeling (MLM) tasks in the NLP pre-training area, numerous masked modeling tasks have been proposed for VLP to further promote cross-modal interactions. The core idea of previous masked modeling tasks is to focus on reconstructing the masked tokens based on visible context for learning local-to-local alignment. However, most of them pay little attention to the global semantic features generated for the masked data, resulting in the limited cross-modal alignment ability of global representations. Therefore, in this paper, we propose a novel Semantic Completion Learning (SCL) task, complementary to existing masked modeling tasks, to facilitate global-to-local alignment. Specifically, the SCL task complements the missing semantics of masked data by capturing the corresponding information from the other modality, promoting learning more representative global features which have a great impact on the performance of downstream tasks. Moreover, we present a flexible vision encoder, which enables our model to perform image-text and video-text multimodal tasks simultaneously. Experimental results show that our proposed method obtains state-of-the-art performance on various vision-language benchmarks, such as visual question answering, image-text retrieval, and video-text retrieval.
Egocentric Video-Language Pretraining @ Ego4D Challenge 2022
Jul 04, 2022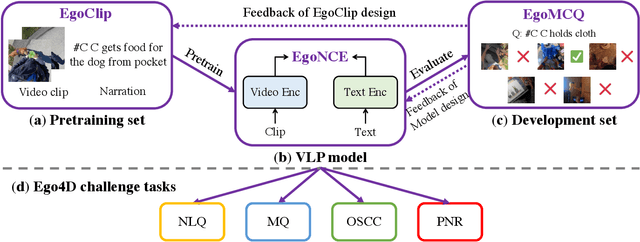
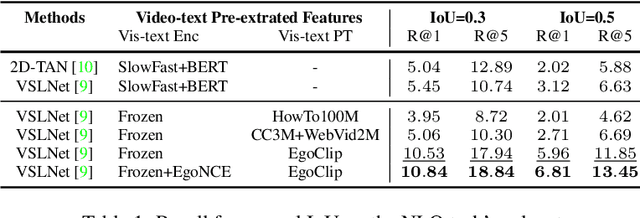
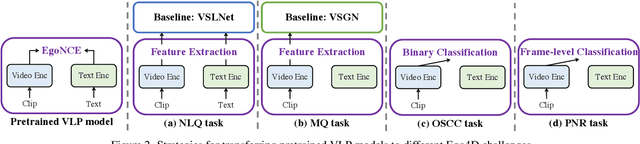
In this report, we propose a video-language pretraining (VLP) based solution \cite{kevin2022egovlp} for four Ego4D challenge tasks, including Natural Language Query (NLQ), Moment Query (MQ), Object State Change Classification (OSCC), and PNR Localization (PNR). Especially, we exploit the recently released Ego4D dataset \cite{grauman2021ego4d} to pioneer Egocentric VLP from pretraining dataset, pretraining objective, and development set. Based on the above three designs, we develop a pretrained video-language model that is able to transfer its egocentric video-text representation or video-only representation to several video downstream tasks. Our Egocentric VLP achieves 10.46R@1&IoU @0.3 on NLQ, 10.33 mAP on MQ, 74% Acc on OSCC, 0.67 sec error on PNR. The code is available at https://github.com/showlab/EgoVLP.
Egocentric Video-Language Pretraining @ EPIC-KITCHENS-100 Multi-Instance Retrieval Challenge 2022
Jul 04, 2022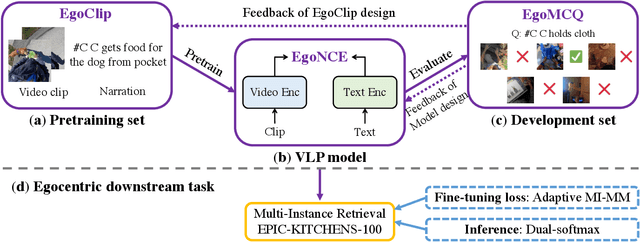
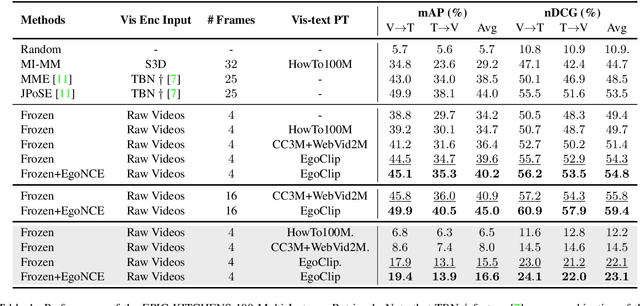
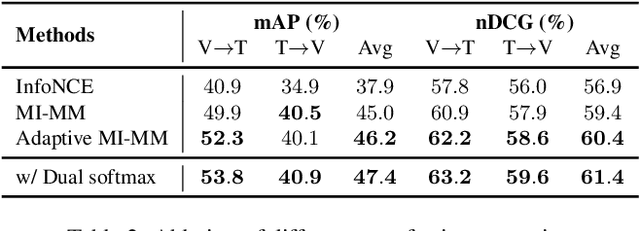
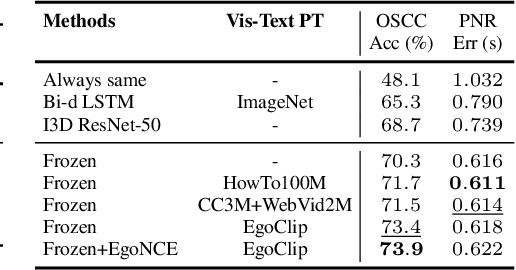
In this report, we propose a video-language pretraining (VLP) based solution \cite{kevin2022egovlp} for the EPIC-KITCHENS-100 Multi-Instance Retrieval (MIR) challenge. Especially, we exploit the recently released Ego4D dataset \cite{grauman2021ego4d} to pioneer Egocentric VLP from pretraining dataset, pretraining objective, and development set. Based on the above three designs, we develop a pretrained video-language model that is able to transfer its egocentric video-text representation to MIR benchmark. Furthermore, we devise an adaptive multi-instance max-margin loss to effectively fine-tune the model and equip the dual-softmax technique for reliable inference. Our best single model obtains strong performance on the challenge test set with 47.39% mAP and 61.44% nDCG. The code is available at https://github.com/showlab/EgoVLP.
Egocentric Video-Language Pretraining
Jun 03, 2022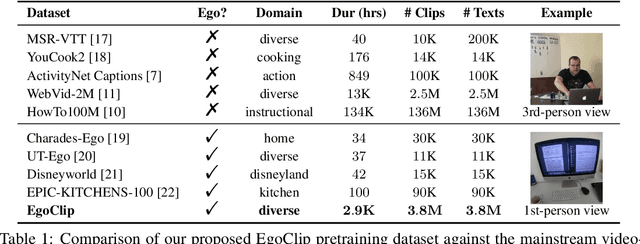
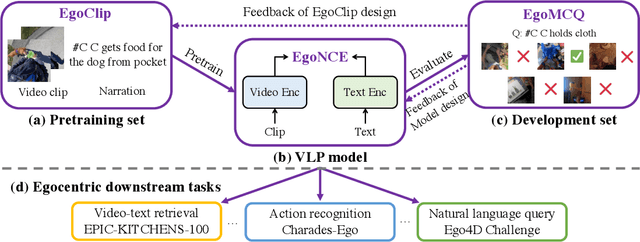

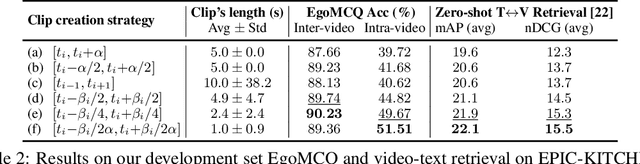
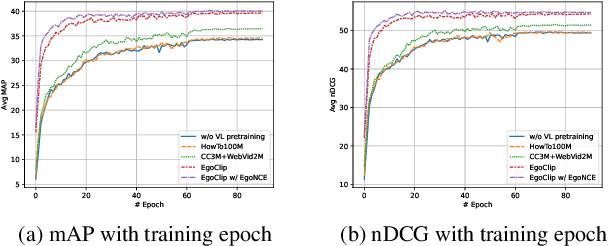
Video-Language Pretraining (VLP), aiming to learn transferable representation to advance a wide range of video-text downstream tasks, has recently received increasing attention. Dominant works that achieve strong performance rely on large-scale, 3rd-person video-text datasets, such as HowTo100M. In this work, we exploit the recently released Ego4D dataset to pioneer Egocentric VLP along three directions. (i) We create EgoClip, a 1st-person video-text pretraining dataset comprising 3.8M clip-text pairs well-chosen from Ego4D, covering a large variety of human daily activities. (ii) We propose a novel pretraining objective, dubbed as EgoNCE, which adapts video-text contrastive learning to egocentric domain by mining egocentric-aware positive and negative samples. (iii) We introduce EgoMCQ, a development benchmark that is close to EgoClip and hence can support effective validation and fast exploration of our design decisions regarding EgoClip and EgoNCE. Furthermore, we demonstrate strong performance on five egocentric downstream tasks across three datasets: video-text retrieval on EPIC-KITCHENS-100; action recognition on Charades-Ego; and natural language query, moment query, and object state change classification on Ego4D challenge benchmarks. The dataset and code will be available at https://github.com/showlab/EgoVLP.