 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuarkMedBench: A Real-World Scenario Driven Benchmark for Evaluating Large Language Models
Mar 14, 2026While Large Language Models (LLMs) excel on standardized medical exams, high scores often fail to translate to high-quality responses for real-world medical queries. Current evaluations rely heavily on multiple-choice questions, failing to capture the unstructured, ambiguous, and long-tail complexities inherent in genuine user inquiries. To bridge this gap, we introduce QuarkMedBench, an ecologically valid benchmark tailored for real-world medical LLM assessment. We compiled a massive dataset spanning Clinical Care, Wellness Health, and Professional Inquiry, comprising 20,821 single-turn queries and 3,853 multi-turn sessions. To objectively evaluate open-ended answers, we propose an automated scoring framework that integrates multi-model consensus with evidence-based retrieval to dynamically generate 220,617 fine-grained scoring rubrics (~9.8 per query). During evaluation, hierarchical weighting and safety constraints structurally quantify medical accuracy, key-point coverage, and risk interception, effectively mitigating the high costs and subjectivity of human grading. Experimental results demonstrate that the generated rubrics achieve a 91.8% concordance rate with clinical expert blind audits, establishing highly dependable medical reliability. Crucially, baseline evaluations on this benchmark reveal significant performance disparities among state-of-the-art models when navigating real-world clinical nuances, highlighting the limitations of conventional exam-based metrics. Ultimately, QuarkMedBench establishes a rigorous, reproducible yardstick for measuring LLM performance on complex health issues, while its framework inherently supports dynamic knowledge updates to prevent benchmark obsolescence.
Quark Medical Alignment: A Holistic Multi-Dimensional Alignment and Collaborative Optimization Paradigm
Feb 12, 2026While reinforcement learning for large language model alignment has progressed rapidly in recent years, transferring these paradigms to high-stakes medical question answering reveals a fundamental paradigm mismatch. Reinforcement Learning from Human Feedback relies on preference annotations that are prohibitively expensive and often fail to reflect the absolute correctness of medical facts. Reinforcement Learning from Verifiable Rewards lacks effective automatic verifiers and struggles to handle complex clinical contexts. Meanwhile, medical alignment requires the simultaneous optimization of correctness, safety, and compliance, yet multi-objective heterogeneous reward signals are prone to scale mismatch and optimization conflicts.To address these challenges, we propose a robust medical alignment paradigm. We first construct a holistic multi-dimensional medical alignment matrix that decomposes alignment objectives into four categories: fundamental capabilities, expert knowledge, online feedback, and format specifications. Within each category, we establish a closed loop of where observable metrics inform attributable diagnosis, which in turn drives optimizable rewards, thereby providing fine-grained, high-resolution supervision signals for subsequent iterative optimization. To resolve gradient domination and optimization instability problem caused by heterogeneous signals, we further propose a unified optimization mechanism. This mechanism employs Reference-Frozen Normalization to align reward scales and implements a Tri-Factor Adaptive Dynamic Weighting strategy to achieve collaborative optimization that is weakness-oriented, risk-prioritized, and redundancy-reducing. Experimental results demonstrate the effectiveness of our proposed paradigm in real-world medical scenario evaluations, establishing a new paradigm for complex alignment in vertical domains.
The Fourth Monocular Depth Estimation Challenge
Apr 24, 2025
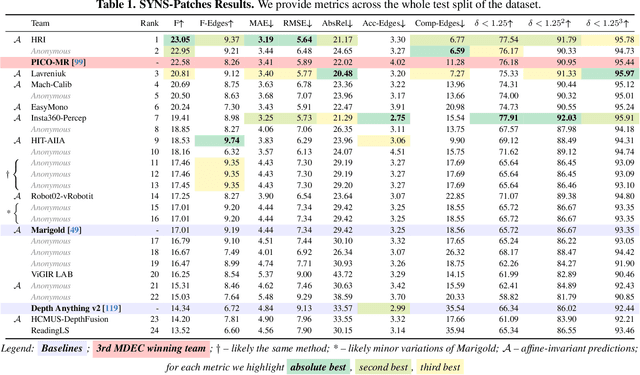
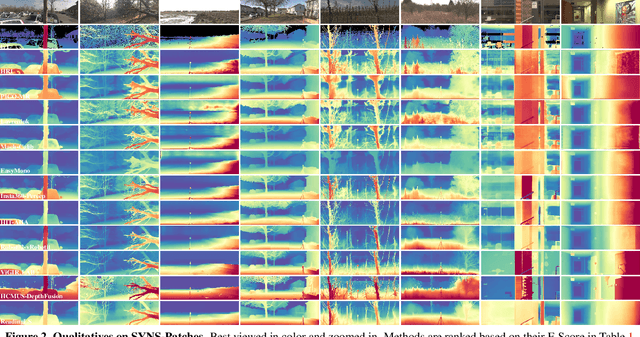
This paper presents the results of the fourth edition of the Monocular Depth Estimation Challenge (MDEC), which focuses on zero-shot generalization to the SYNS-Patches benchmark, a dataset featuring challenging environments in both natural and indoor settings. In this edition, we revised the evaluation protocol to use least-squares alignment with two degrees of freedom to support disparity and affine-invariant predictions. We also revised the baselines and included popular off-the-shelf methods: Depth Anything v2 and Marigold. The challenge received a total of 24 submissions that outperformed the baselines on the test set; 10 of these included a report describing their approach, with most leading methods relying on affine-invariant predictions. The challenge winners improved the 3D F-Score over the previous edition's best result, raising it from 22.58% to 23.05%.
Box Re-Ranking: Unsupervised False Positive Suppression for Domain Adaptive Pedestrian Detection
Feb 01, 2021
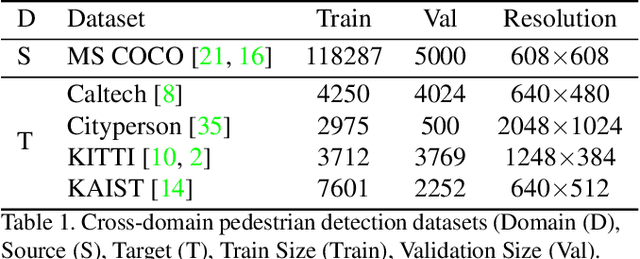
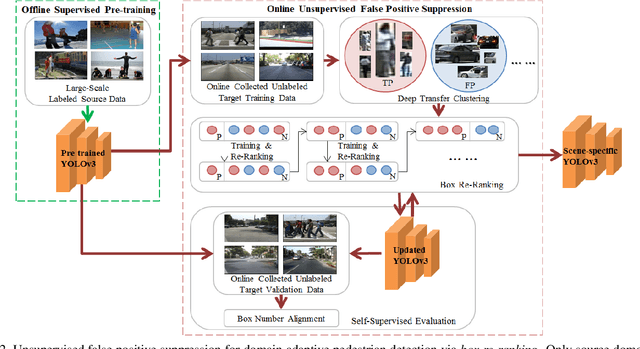
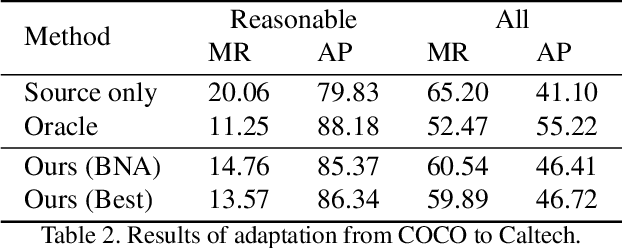
False positive is one of the most serious problems brought by agnostic domain shift in domain adaptive pedestrian detection. However, it is impossible to label each box in countless target domains. Therefore, it yields our attention to suppress false positive in each target domain in an unsupervised way. In this paper, we model an object detection task into a ranking task among positive and negative boxes innovatively, and thus transform a false positive suppression problem into a box re-ranking problem elegantly, which makes it feasible to solve without manual annotation. An attached problem during box re-ranking appears that no labeled validation data is available for cherrypicking. Considering we aim to keep the detection of true positive unchanged, we propose box number alignment, a self-supervised evaluation metric, to prevent the optimized model from capacity degeneration. Extensive experiments conducted on cross-domain pedestrian detection datasets have demonstrated the effectiveness of our proposed framework. Furthermore, the extension to two general unsupervised domain adaptive object detection benchmarks also supports our superiority to other state-of-the-arts.