 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-View Transformer for 3D Visual Grounding
Apr 05, 2022
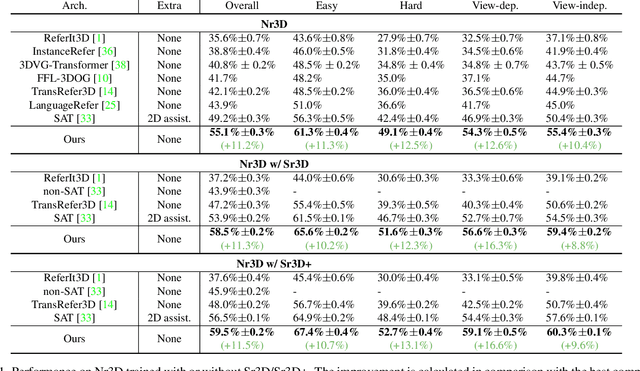
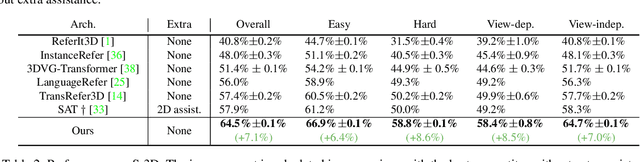
The 3D visual grounding task aims to ground a natural language description to the targeted object in a 3D scene, which is usually represented in 3D point clouds. Previous works studied visual grounding under specific views. The vision-language correspondence learned by this way can easily fail once the view changes. In this paper, we propose a Multi-View Transformer (MVT) for 3D visual grounding. We project the 3D scene to a multi-view space, in which the position information of the 3D scene under different views are modeled simultaneously and aggregated together. The multi-view space enables the network to learn a more robust multi-modal representation for 3D visual grounding and eliminates the dependence on specific views. Extensive experiments show that our approach significantly outperforms all state-of-the-art methods. Specifically, on Nr3D and Sr3D datasets, our method outperforms the best competitor by 11.2% and 7.1% and even surpasses recent work with extra 2D assistance by 5.9% and 6.6%. Our code is available at https://github.com/sega-hsj/MVT-3DVG.
Region Rebalance for Long-Tailed Semantic Segmentation
Apr 05, 2022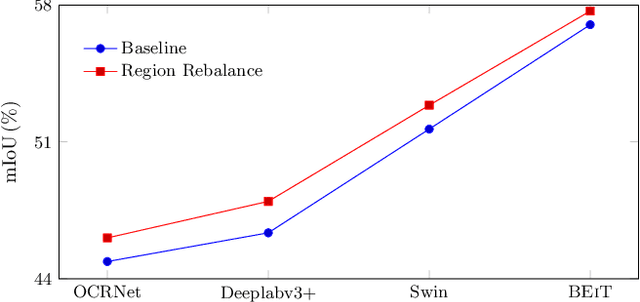

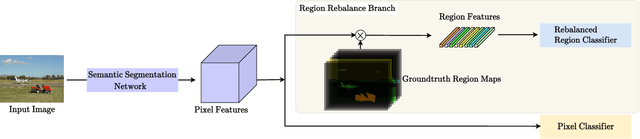

In this paper, we study the problem of class imbalance in semantic segmentation. We first investigate and identify the main challenges of addressing this issue through pixel rebalance. Then a simple and yet effective region rebalance scheme is derived based on our analysis. In our solution, pixel features belonging to the same class are grouped into region features, and a rebalanced region classifier is applied via an auxiliary region rebalance branch during training. To verify the flexibility and effectiveness of our method, we apply the region rebalance module into various semantic segmentation methods, such as Deeplabv3+, OCRNet, and Swin. Our strategy achieves consistent improvement on the challenging ADE20K and COCO-Stuff benchmark. In particular, with the proposed region rebalance scheme, state-of-the-art BEiT receives +0.7% gain in terms of mIoU on the ADE20K val set.
MAT: Mask-Aware Transformer for Large Hole Image Inpainting
Mar 30, 2022



Recent studies have shown the importance of modeling long-range interactions in the inpainting problem. To achieve this goal, existing approaches exploit either standalone attention techniques or transformers, but usually under a low resolution in consideration of computational cost. In this paper, we present a novel transformer-based model for large hole inpainting, which unifies the merits of transformers and convolutions to efficiently process high-resolution images. We carefully design each component of our framework to guarantee the high fidelity and diversity of recovered images. Specifically, we customize an inpainting-oriented transformer block, where the attention module aggregates non-local information only from partial valid tokens, indicated by a dynamic mask. Extensive experiments demonstrate the state-of-the-art performance of the new model on multiple benchmark datasets. Code is released at https://github.com/fenglinglwb/MAT.
Stratified Transformer for 3D Point Cloud Segmentation
Mar 28, 2022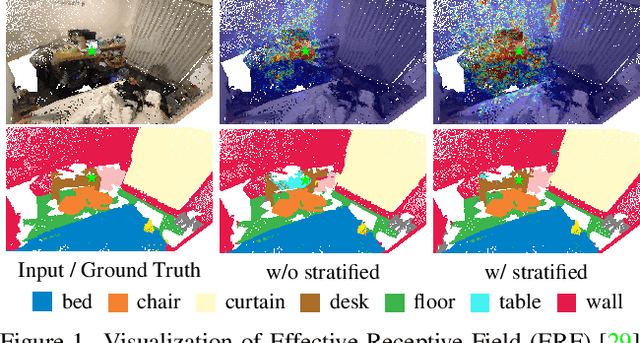
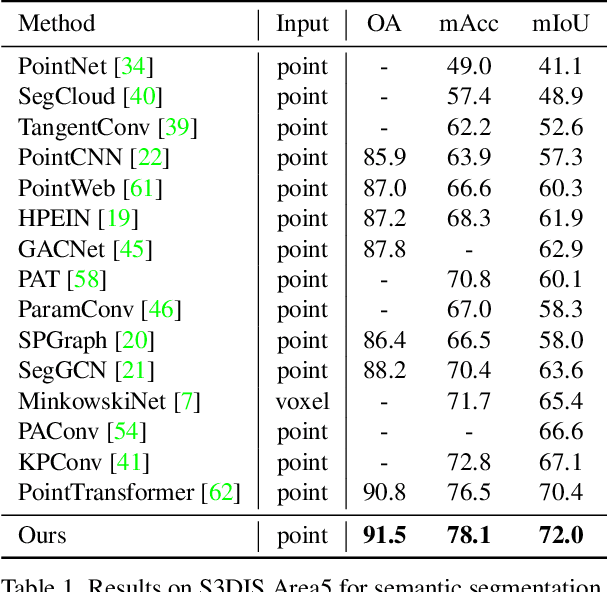
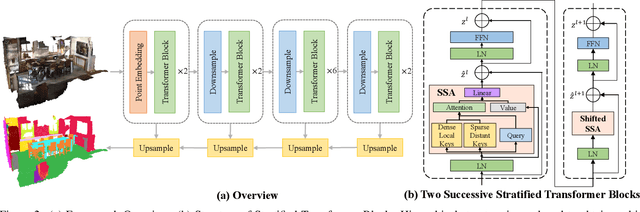
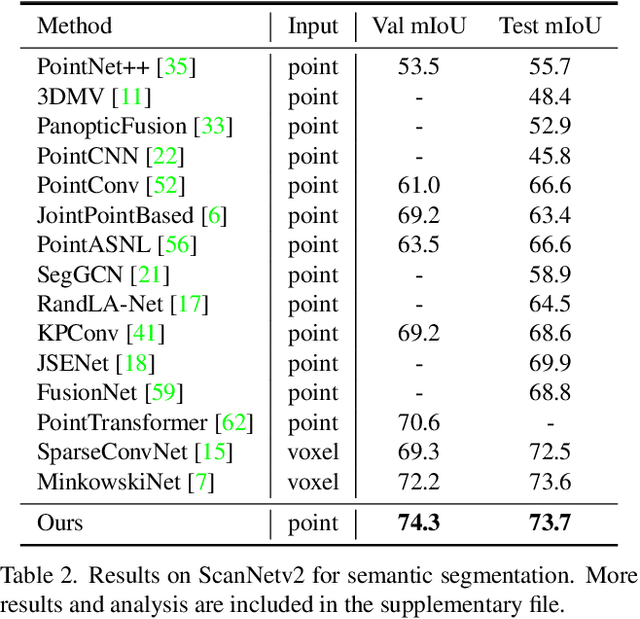
3D point cloud segmentation has made tremendous progress in recent years. Most current methods focus on aggregating local features, but fail to directly model long-range dependencies. In this paper, we propose Stratified Transformer that is able to capture long-range contexts and demonstrates strong generalization ability and high performance. Specifically, we first put forward a novel key sampling strategy. For each query point, we sample nearby points densely and distant points sparsely as its keys in a stratified way, which enables the model to enlarge the effective receptive field and enjoy long-range contexts at a low computational cost. Also, to combat the challenges posed by irregular point arrangements, we propose first-layer point embedding to aggregate local information, which facilitates convergence and boosts performance. Besides, we adopt contextual relative position encoding to adaptively capture position information. Finally, a memory-efficient implementation is introduced to overcome the issue of varying point numbers in each window. Extensive experiments demonstrate the effectiveness and superiority of our method on S3DIS, ScanNetv2 and ShapeNetPart datasets. Code is available at https://github.com/dvlab-research/Stratified-Transformer.
Rebalanced Siamese Contrastive Mining for Long-Tailed Recognition
Mar 22, 2022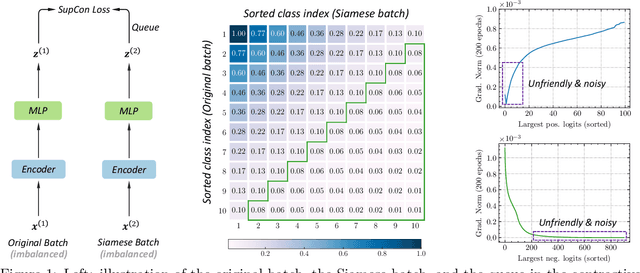
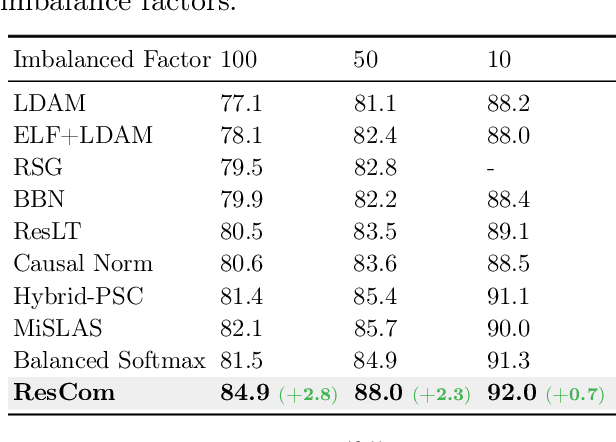
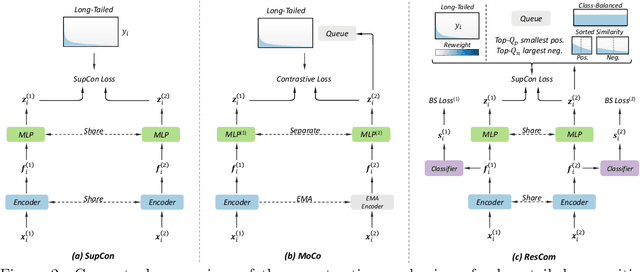
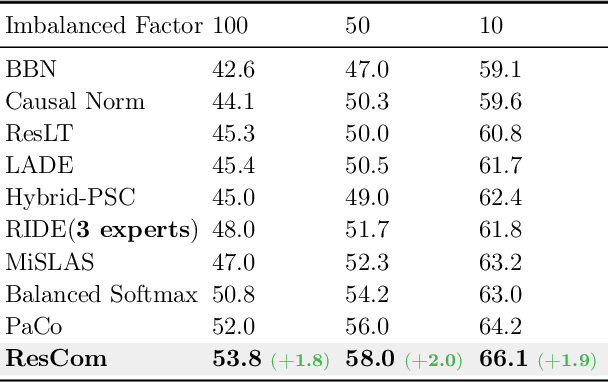
Deep neural networks perform poorly on heavily class-imbalanced datasets. Given the promising performance of contrastive learning, we propose $\mathbf{Re}$balanced $\mathbf{S}$iamese $\mathbf{Co}$ntrastive $\mathbf{m}$ining ( $\mathbf{ResCom}$) to tackle imbalanced recognition. Based on the mathematical analysis and simulation results, we claim that supervised contrastive learning suffers a dual class-imbalance problem at both the original batch and Siamese batch levels, which is more serious than long-tailed classification learning. In this paper, at the original batch level, we introduce a class-balanced supervised contrastive loss to assign adaptive weights for different classes. At the Siamese batch level, we present a class-balanced queue, which maintains the same number of keys for all classes. Furthermore, we note that the contrastive loss gradient with respect to the contrastive logits can be decoupled into the positives and negatives, and easy positives and easy negatives will make the contrastive gradient vanish. We propose supervised hard positive and negative pairs mining to pick up informative pairs for contrastive computation and improve representation learning. Finally, to approximately maximize the mutual information between the two views, we propose Siamese Balanced Softmax and joint it with the contrastive loss for one-stage training. ResCom outperforms the previous methods by large margins on multiple long-tailed recognition benchmarks. Our code will be made publicly available at: https://github.com/dvlab-research/ResCom.
A Unified Query-based Paradigm for Point Cloud Understanding
Mar 03, 2022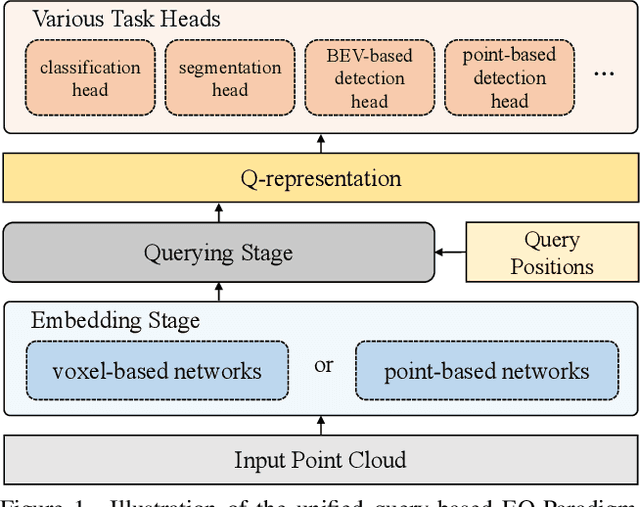
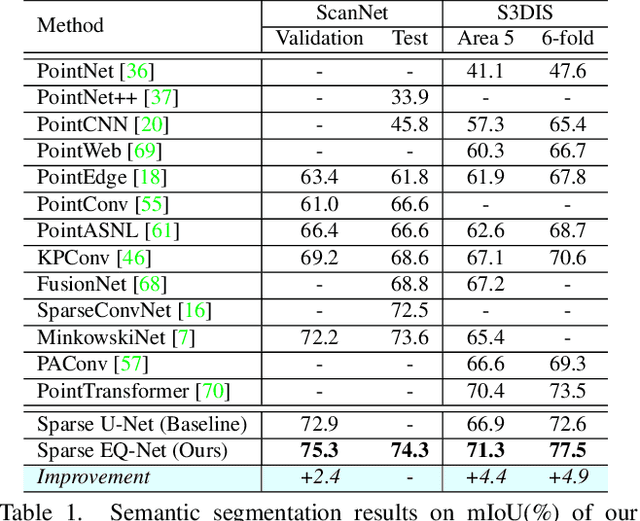
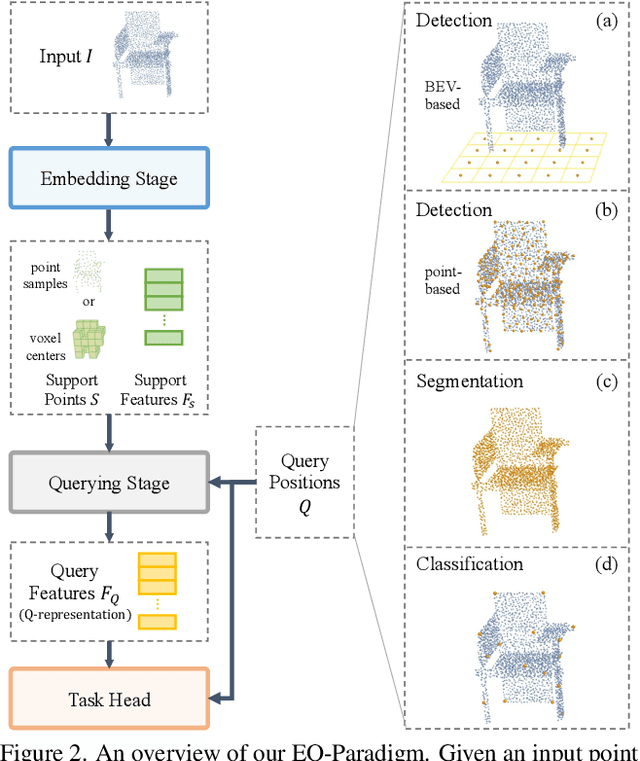
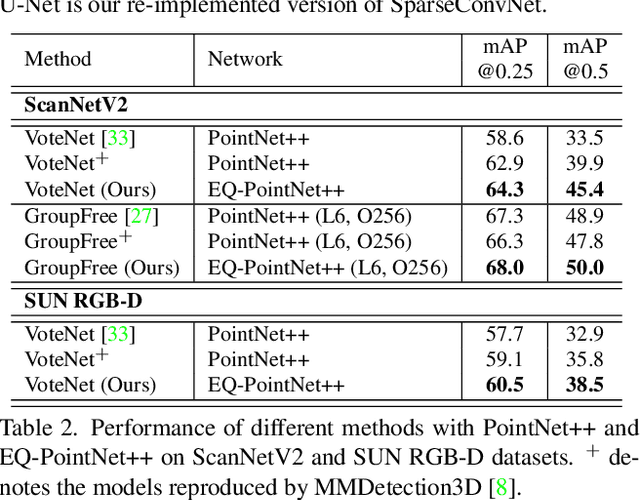
3D point cloud understanding is an important component in autonomous driving and robotics. In this paper, we present a novel Embedding-Querying paradigm (EQ-Paradigm) for 3D understanding tasks including detection, segmentation and classification. EQ-Paradigm is a unified paradigm that enables the combination of any existing 3D backbone architectures with different task heads. Under the EQ-Paradigm, the input is firstly encoded in the embedding stage with an arbitrary feature extraction architecture, which is independent of tasks and heads. Then, the querying stage enables the encoded features to be applicable for diverse task heads. This is achieved by introducing an intermediate representation, i.e., Q-representation, in the querying stage to serve as a bridge between the embedding stage and task heads. We design a novel Q-Net as the querying stage network. Extensive experimental results on various 3D tasks including semantic segmentation, object detection and shape classification show that EQ-Paradigm in tandem with Q-Net is a general and effective pipeline, which enables a flexible collaboration of backbones and heads, and further boosts the performance of the state-of-the-art methods. All codes and models will be published soon.
SEA: Bridging the Gap Between One- and Two-stage Detector Distillation via SEmantic-aware Alignment
Mar 02, 2022
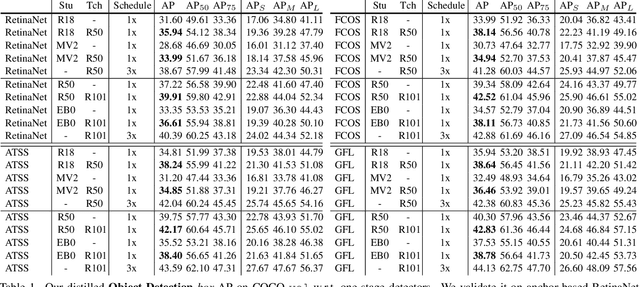
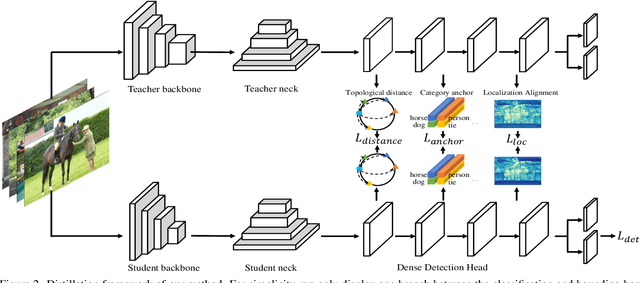
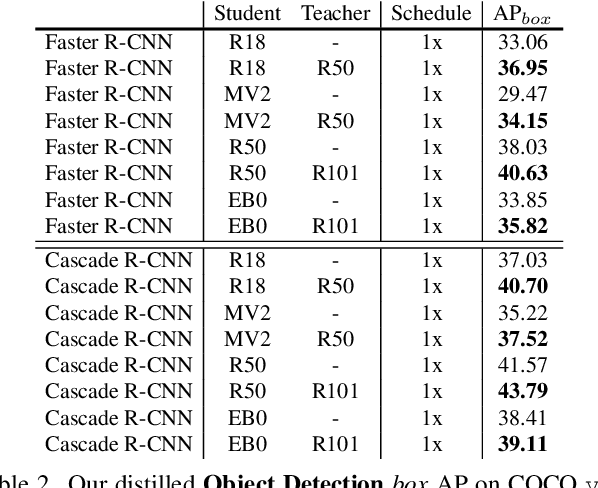
We revisit the one- and two-stage detector distillation tasks and present a simple and efficient semantic-aware framework to fill the gap between them. We address the pixel-level imbalance problem by designing the category anchor to produce a representative pattern for each category and regularize the topological distance between pixels and category anchors to further tighten their semantic bonds. We name our method SEA (SEmantic-aware Alignment) distillation given the nature of abstracting dense fine-grained information by semantic reliance to well facilitate distillation efficacy. SEA is well adapted to either detection pipeline and achieves new state-of-the-art results on the challenging COCO object detection task on both one- and two-stage detectors. Its superior performance on instance segmentation further manifests the generalization ability. Both 2x-distilled RetinaNet and FCOS with ResNet50-FPN outperform their corresponding 3x ResNet101-FPN teacher, arriving 40.64 and 43.06 AP, respectively. Code will be made publicly available.
High Quality Segmentation for Ultra High-resolution Images
Dec 26, 2021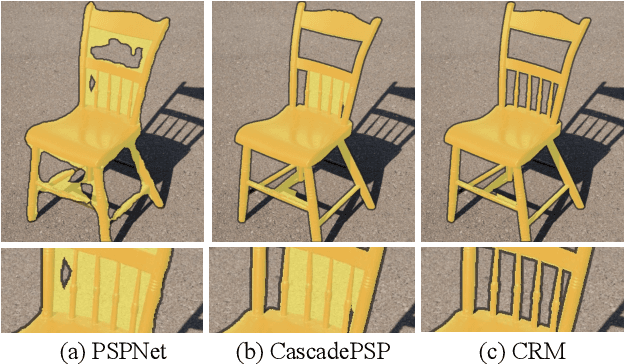
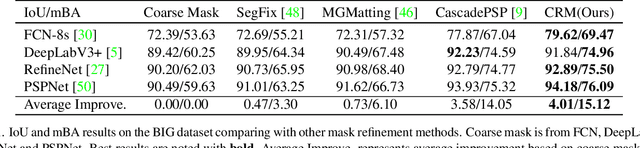
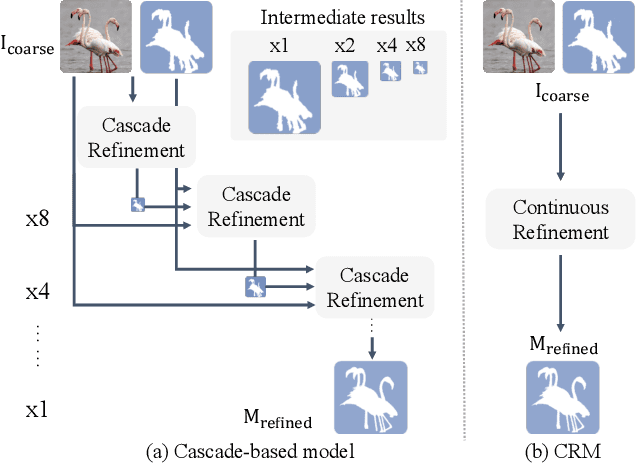
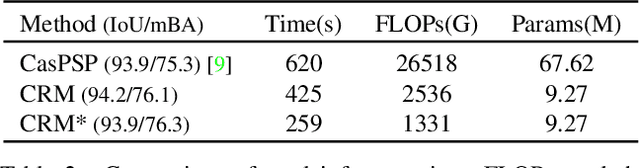
To segment 4K or 6K ultra high-resolution images needs extra computation consideration in image segmentation. Common strategies, such as down-sampling, patch cropping, and cascade model, cannot address well the balance issue between accuracy and computation cost. Motivated by the fact that humans distinguish among objects continuously from coarse to precise levels, we propose the Continuous Refinement Model~(CRM) for the ultra high-resolution segmentation refinement task. CRM continuously aligns the feature map with the refinement target and aggregates features to reconstruct these images' details. Besides, our CRM shows its significant generalization ability to fill the resolution gap between low-resolution training images and ultra high-resolution testing ones. We present quantitative performance evaluation and visualization to show that our proposed method is fast and effective on image segmentation refinement. Code will be released at https://github.com/dvlab-research/Entity.
On Efficient Transformer and Image Pre-training for Low-level Vision
Dec 19, 2021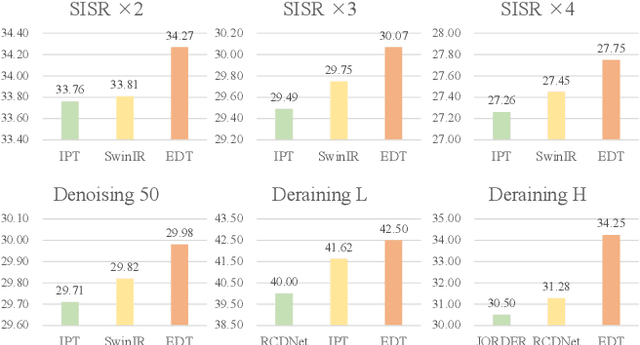
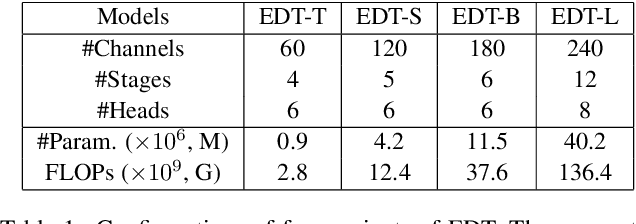
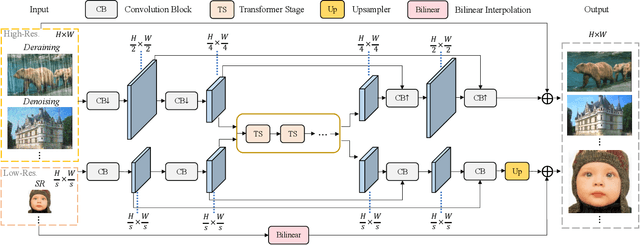
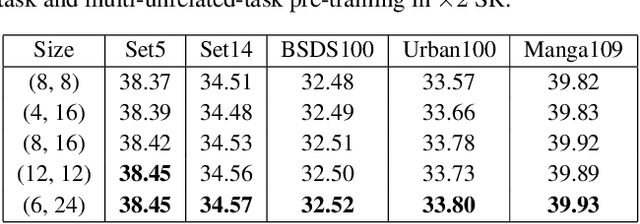
Pre-training has marked numerous state of the arts in high-level computer vision, but few attempts have ever been made to investigate how pre-training acts in image processing systems. In this paper, we present an in-depth study of image pre-training. To conduct this study on solid ground with practical value in mind, we first propose a generic, cost-effective Transformer-based framework for image processing. It yields highly competitive performance across a range of low-level tasks, though under constrained parameters and computational complexity. Then, based on this framework, we design a whole set of principled evaluation tools to seriously and comprehensively diagnose image pre-training in different tasks, and uncover its effects on internal network representations. We find pre-training plays strikingly different roles in low-level tasks. For example, pre-training introduces more local information to higher layers in super-resolution (SR), yielding significant performance gains, while pre-training hardly affects internal feature representations in denoising, resulting in a little gain. Further, we explore different methods of pre-training, revealing that multi-task pre-training is more effective and data-efficient. All codes and models will be released at https://github.com/fenglinglwb/EDT.
CaSP: Class-agnostic Semi-Supervised Pretraining for Detection and Segmentation
Dec 09, 2021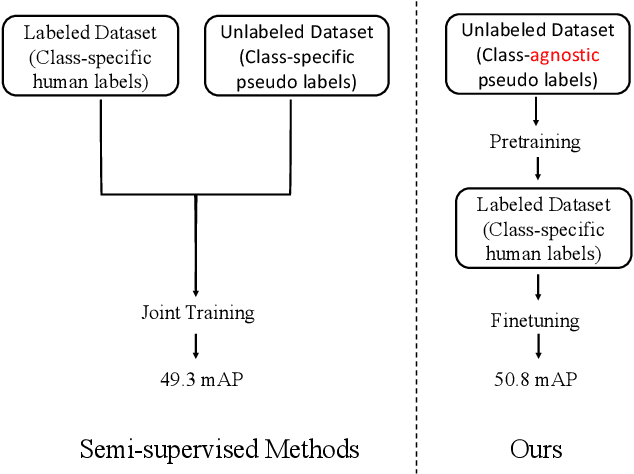
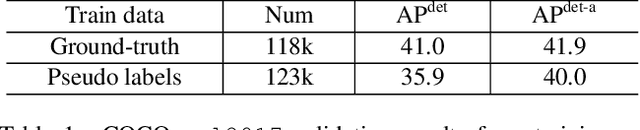
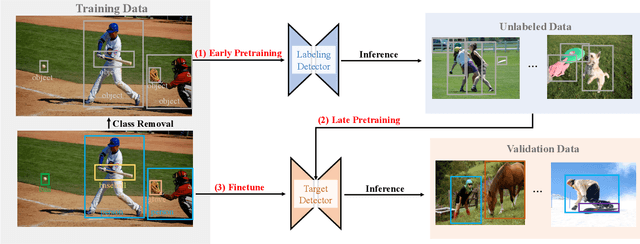
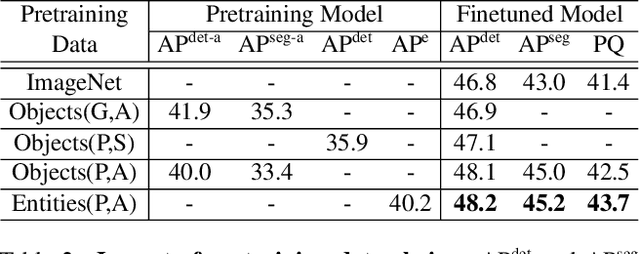
To improve instance-level detection/segmentation performance, existing self-supervised and semi-supervised methods extract either very task-unrelated or very task-specific training signals from unlabeled data. We argue that these two approaches, at the two extreme ends of the task-specificity spectrum, are suboptimal for the task performance. Utilizing too little task-specific training signals causes underfitting to the ground-truth labels of downstream tasks, while the opposite causes overfitting to the ground-truth labels. To this end, we propose a novel Class-agnostic Semi-supervised Pretraining (CaSP) framework to achieve a more favorable task-specificity balance in extracting training signals from unlabeled data. Compared to semi-supervised learning, CaSP reduces the task specificity in training signals by ignoring class information in the pseudo labels and having a separate pretraining stage that uses only task-unrelated unlabeled data. On the other hand, CaSP preserves the right amount of task specificity by leveraging box/mask-level pseudo labels. As a result, our pretrained model can better avoid underfitting/overfitting to ground-truth labels when finetuned on the downstream task. Using 3.6M unlabeled data, we achieve a remarkable performance gain of 4.7% over ImageNet-pretrained baseline on object detection. Our pretrained model also demonstrates excellent transferability to other detection and segmentation tasks/frameworks.