 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADAPT: Vision-Language Navigation with Modality-Aligned Action Prompts
May 31, 2022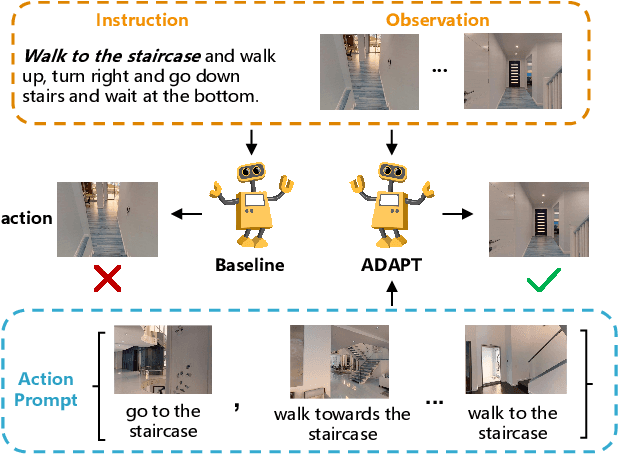

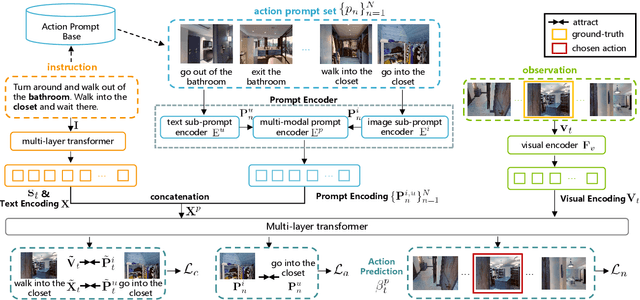
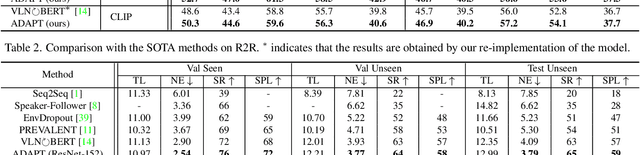
Vision-Language Navigation (VLN) is a challenging task that requires an embodied agent to perform action-level modality alignment, i.e., make instruction-asked actions sequentially in complex visual environments. Most existing VLN agents learn the instruction-path data directly and cannot sufficiently explore action-level alignment knowledge inside the multi-modal inputs. In this paper, we propose modAlity-aligneD Action PrompTs (ADAPT), which provides the VLN agent with action prompts to enable the explicit learning of action-level modality alignment to pursue successful navigation. Specifically, an action prompt is defined as a modality-aligned pair of an image sub-prompt and a text sub-prompt, where the former is a single-view observation and the latter is a phrase like ''walk past the chair''. When starting navigation, the instruction-related action prompt set is retrieved from a pre-built action prompt base and passed through a prompt encoder to obtain the prompt feature. Then the prompt feature is concatenated with the original instruction feature and fed to a multi-layer transformer for action prediction. To collect high-quality action prompts into the prompt base, we use the Contrastive Language-Image Pretraining (CLIP) model which has powerful cross-modality alignment ability. A modality alignment loss and a sequential consistency loss are further introduced to enhance the alignment of the action prompt and enforce the agent to focus on the related prompt sequentially. Experimental results on both R2R and RxR show the superiority of ADAPT over state-of-the-art methods.
Diversity Matters: Fully Exploiting Depth Clues for Reliable Monocular 3D Object Detection
May 19, 2022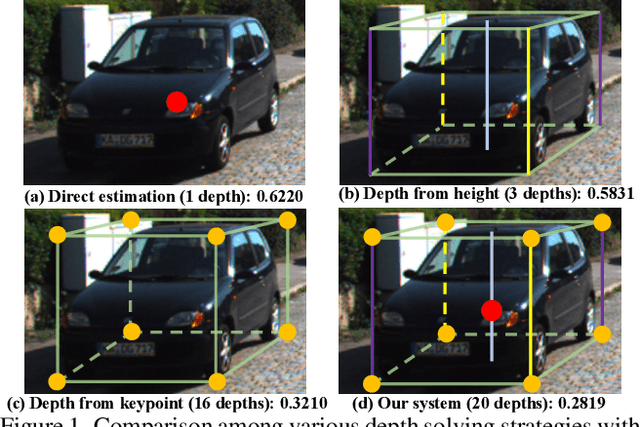
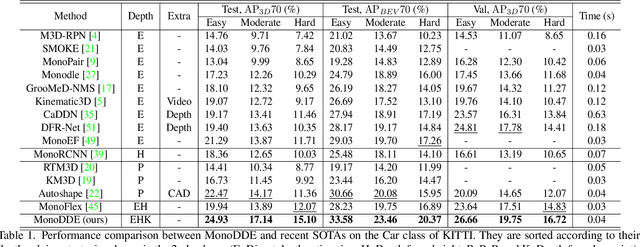
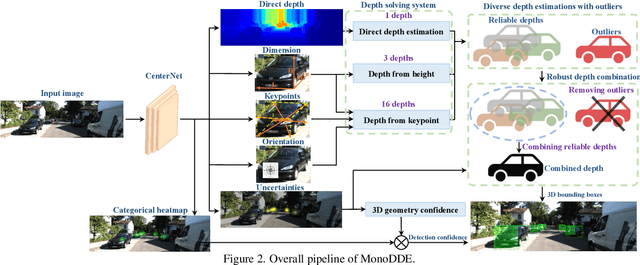
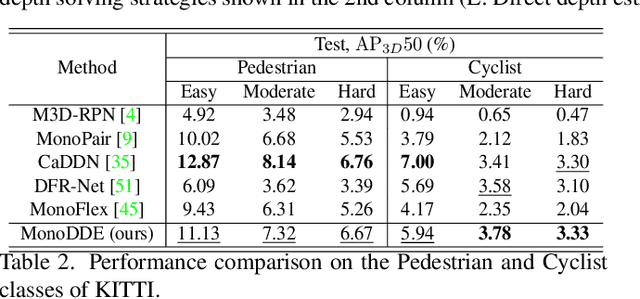
As an inherently ill-posed problem, depth estimation from single images is the most challenging part of monocular 3D object detection (M3OD). Many existing methods rely on preconceived assumptions to bridge the missing spatial information in monocular images, and predict a sole depth value for every object of interest. However, these assumptions do not always hold in practical applications. To tackle this problem, we propose a depth solving system that fully explores the visual clues from the subtasks in M3OD and generates multiple estimations for the depth of each target. Since the depth estimations rely on different assumptions in essence, they present diverse distributions. Even if some assumptions collapse, the estimations established on the remaining assumptions are still reliable. In addition, we develop a depth selection and combination strategy. This strategy is able to remove abnormal estimations caused by collapsed assumptions, and adaptively combine the remaining estimations into a single one. In this way, our depth solving system becomes more precise and robust. Exploiting the clues from multiple subtasks of M3OD and without introducing any extra information, our method surpasses the current best method by more than 20% relatively on the Moderate level of test split in the KITTI 3D object detection benchmark, while still maintaining real-time efficiency.
Prompt Distribution Learning
May 06, 2022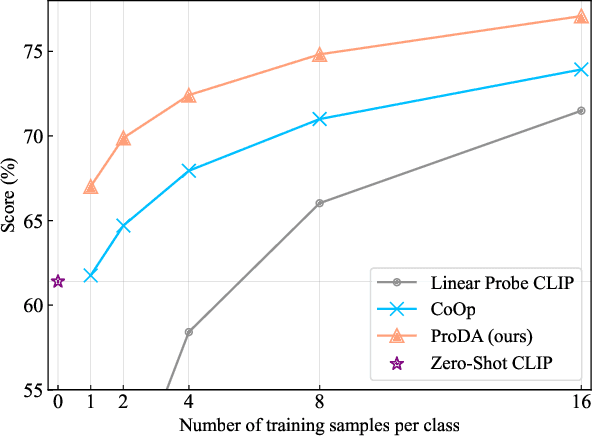
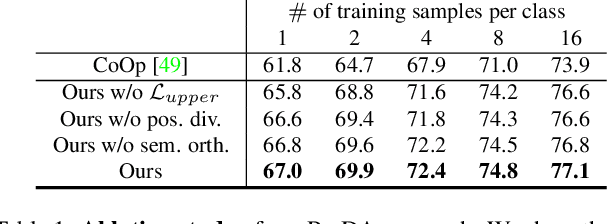
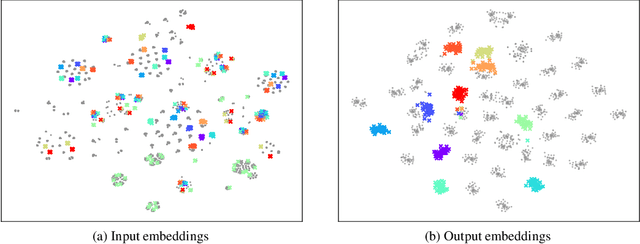

We present prompt distribution learning for effectively adapting a pre-trained vision-language model to address downstream recognition tasks. Our method not only learns low-bias prompts from a few samples but also captures the distribution of diverse prompts to handle the varying visual representations. In this way, we provide high-quality task-related content for facilitating recognition. This prompt distribution learning is realized by an efficient approach that learns the output embeddings of prompts instead of the input embeddings. Thus, we can employ a Gaussian distribution to model them effectively and derive a surrogate loss for efficient training. Extensive experiments on 12 datasets demonstrate that our method consistently and significantly outperforms existing methods. For example, with 1 sample per category, it relatively improves the average result by 9.1% compared to human-crafted prompts.
Learning Enriched Illuminants for Cross and Single Sensor Color Constancy
Mar 21, 2022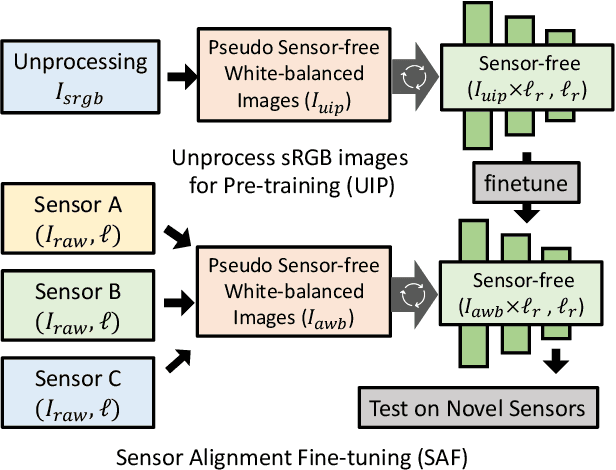
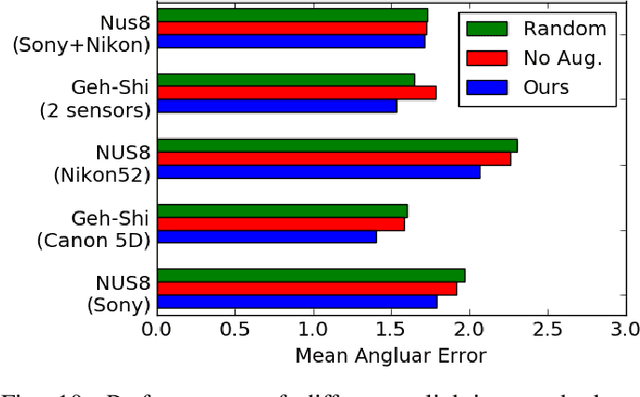

Color constancy aims to restore the constant colors of a scene under different illuminants. However, due to the existence of camera spectral sensitivity, the network trained on a certain sensor, cannot work well on others. Also, since the training datasets are collected in certain environments, the diversity of illuminants is limited for complex real world prediction. In this paper, we tackle these problems via two aspects. First, we propose cross-sensor self-supervised training to train the network. In detail, we consider both the general sRGB images and the white-balanced RAW images from current available datasets as the white-balanced agents. Then, we train the network by randomly sampling the artificial illuminants in a sensor-independent manner for scene relighting and supervision. Second, we analyze a previous cascaded framework and present a more compact and accurate model by sharing the backbone parameters with learning attention specifically. Experiments show that our cross-sensor model and single-sensor model outperform other state-of-the-art methods by a large margin on cross and single sensor evaluations, respectively, with only 16% parameters of the previous best model.
Differentiated Relevances Embedding for Group-based Referring Expression Comprehension
Mar 12, 2022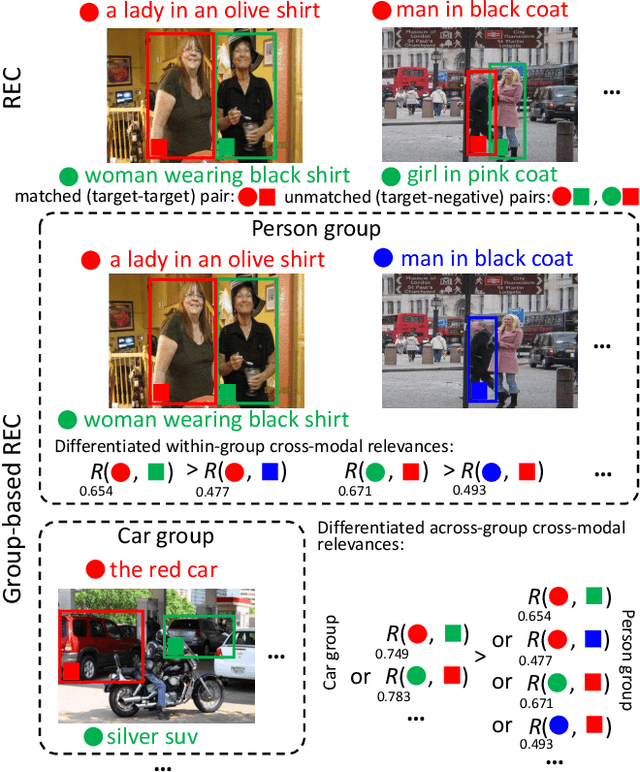
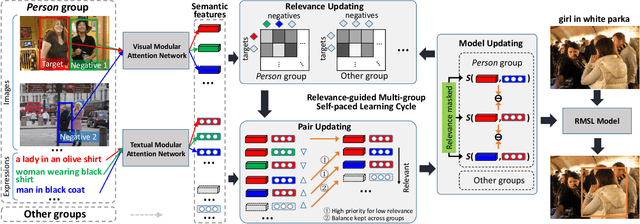

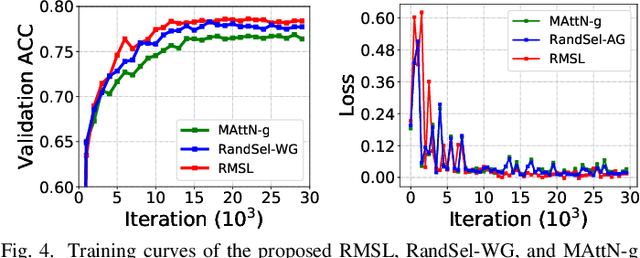
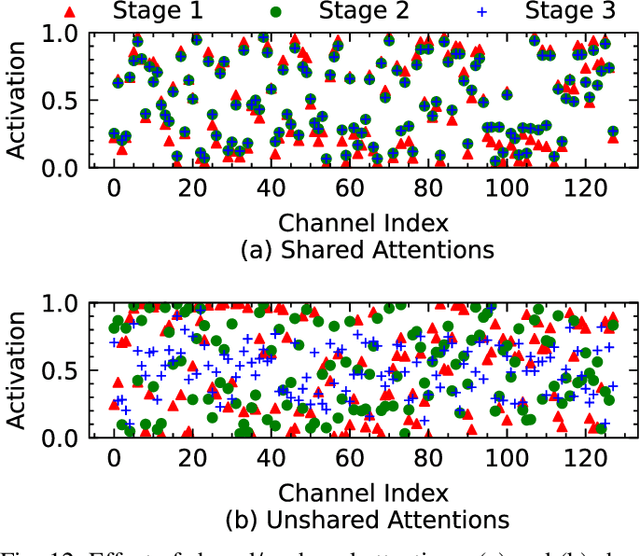
Referring expression comprehension (REC) aims to locate a certain object in an image referred by a natural language expression. For joint understanding of regions and expressions, existing REC works typically target on modeling the cross-modal relevance in each region-expression pair within each single image. In this paper, we explore a new but general REC-related problem, named Group-based REC, where the regions and expressions can come from different subject-related images (images in the same group), e.g., sets of photo albums or video frames. Different from REC, Group-based REC involves differentiated cross-modal relevances within each group and across different groups, which, however, are neglected in the existing one-line paradigm. To this end, we propose a novel relevance-guided multi-group self-paced learning schema (termed RMSL), where the within-group region-expression pairs are adaptively assigned with different priorities according to their cross-modal relevances, and the bias of the group priority is balanced via an across-group relevance constraint simultaneously. In particular, based on the visual and textual semantic features, RMSL conducts an adaptive learning cycle upon triplet ranking, where (1) the target-negative region-expression pairs with low within-group relevances are used preferentially in model training to distinguish the primary semantics of the target objects, and (2) an across-group relevance regularization is integrated into model training to balance the bias of group priority. The relevances, the pairs, and the model parameters are alternatively updated upon a unified self-paced hinge loss.
SiamTrans: Zero-Shot Multi-Frame Image Restoration with Pre-Trained Siamese Transformers
Dec 17, 2021
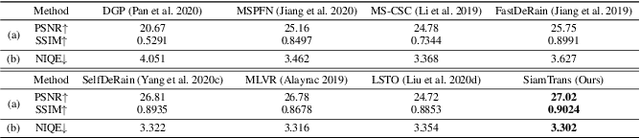
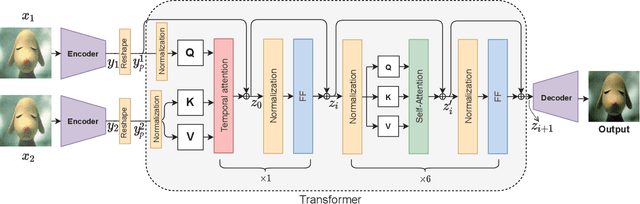
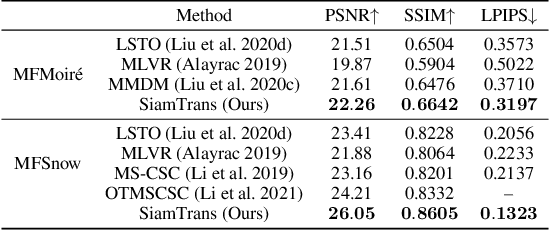
We propose a novel zero-shot multi-frame image restoration method for removing unwanted obstruction elements (such as rains, snow, and moire patterns) that vary in successive frames. It has three stages: transformer pre-training, zero-shot restoration, and hard patch refinement. Using the pre-trained transformers, our model is able to tell the motion difference between the true image information and the obstructing elements. For zero-shot image restoration, we design a novel model, termed SiamTrans, which is constructed by Siamese transformers, encoders, and decoders. Each transformer has a temporal attention layer and several self-attention layers, to capture both temporal and spatial information of multiple frames. Only pre-trained (self-supervised) on the denoising task, SiamTrans is tested on three different low-level vision tasks (deraining, demoireing, and desnowing). Compared with related methods, ours achieves the best performances, even outperforming those with supervised learning.
IntraQ: Learning Synthetic Images with Intra-Class Heterogeneity for Zero-Shot Network Quantization
Dec 03, 2021
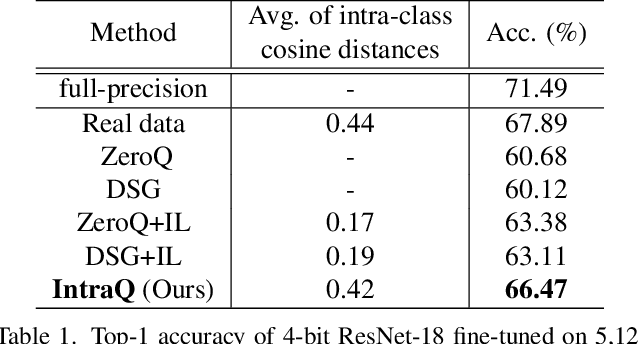
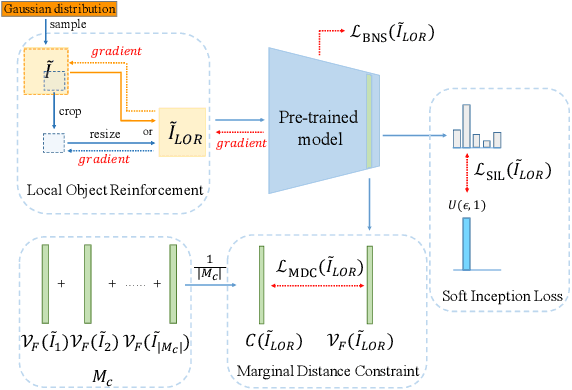
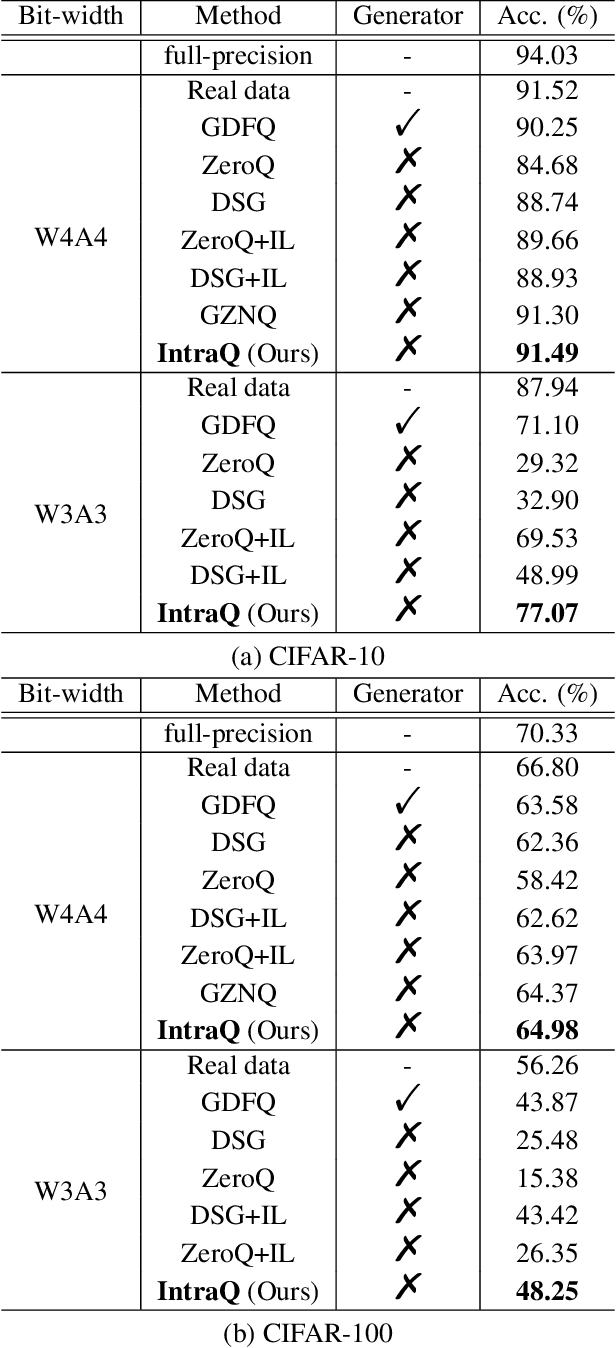
Learning to synthesize data has emerged as a promising direction in zero-shot quantization (ZSQ), which represents neural networks by low-bit integer without accessing any of the real data. In this paper, we observe an interesting phenomenon of intra-class heterogeneity in real data and show that existing methods fail to retain this property in their synthetic images, which causes a limited performance increase. To address this issue, we propose a novel zero-shot quantization method referred to as IntraQ. First, we propose a local object reinforcement that locates the target objects at different scales and positions of the synthetic images. Second, we introduce a marginal distance constraint to form class-related features distributed in a coarse area. Lastly, we devise a soft inception loss which injects a soft prior label to prevent the synthetic images from being overfitting to a fixed object. Our IntraQ is demonstrated to well retain the intra-class heterogeneity in the synthetic images and also observed to perform state-of-the-art. For example, compared to the advanced ZSQ, our IntraQ obtains 9.17\% increase of the top-1 accuracy on ImageNet when all layers of MobileNetV1 are quantized to 4-bit. Code is at https://github.com/zysxmu/InterQ.
Motion Deblurring with Real Events
Sep 28, 2021
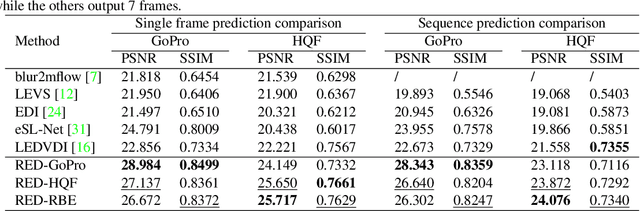
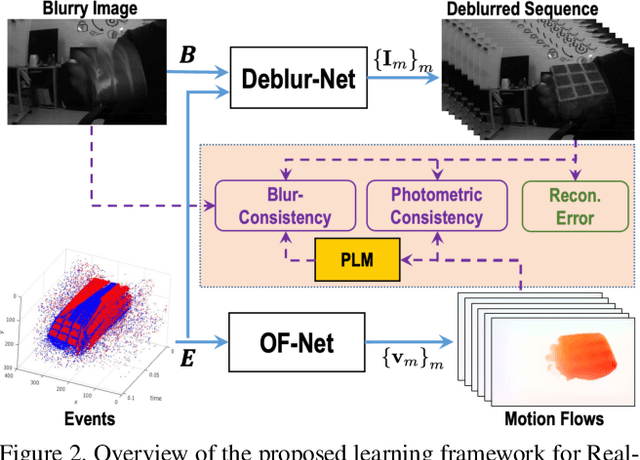
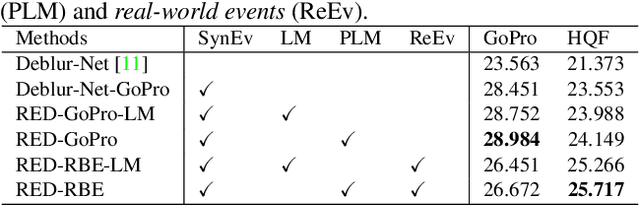
In this paper, we propose an end-to-end learning framework for event-based motion deblurring in a self-supervised manner, where real-world events are exploited to alleviate the performance degradation caused by data inconsistency. To achieve this end, optical flows are predicted from events, with which the blurry consistency and photometric consistency are exploited to enable self-supervision on the deblurring network with real-world data. Furthermore, a piece-wise linear motion model is proposed to take into account motion non-linearities and thus leads to an accurate model for the physical formation of motion blurs in the real-world scenario. Extensive evaluation on both synthetic and real motion blur datasets demonstrates that the proposed algorithm bridges the gap between simulated and real-world motion blurs and shows remarkable performance for event-based motion deblurring in real-world scenarios.
Prioritized Subnet Sampling for Resource-Adaptive Supernet Training
Sep 12, 2021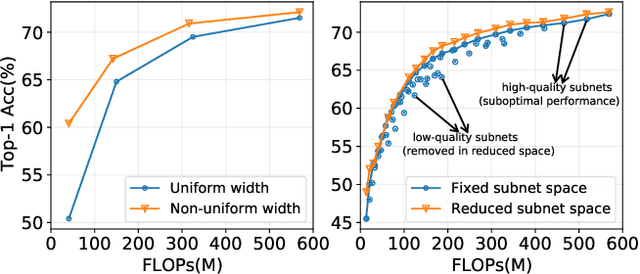
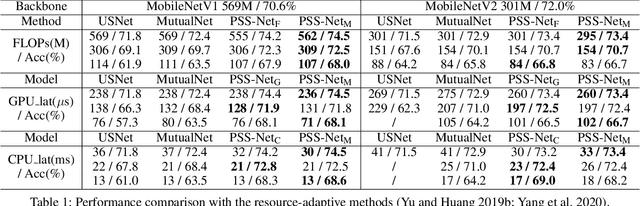
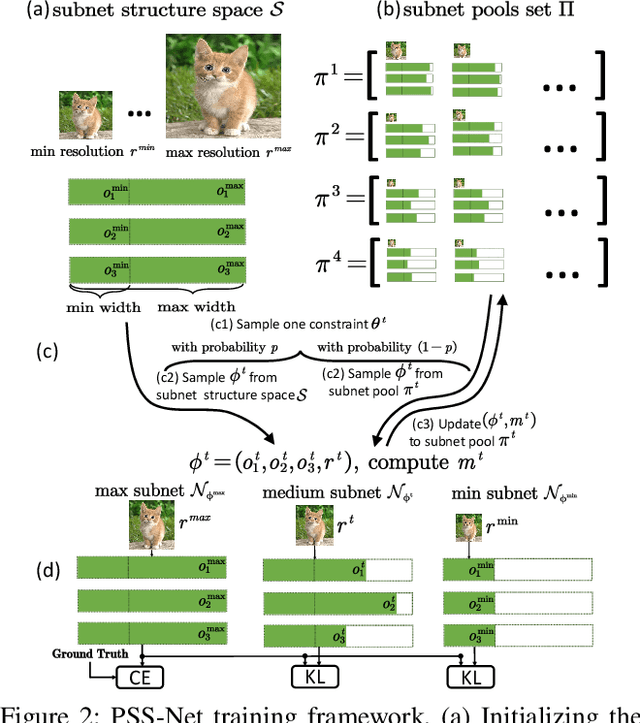
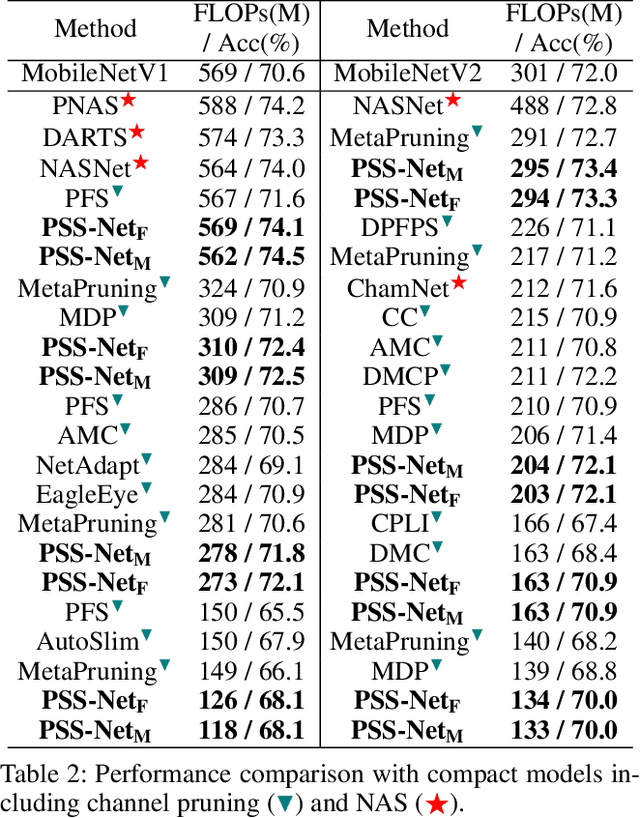
A resource-adaptive supernet adjusts its subnets for inference to fit the dynamically available resources. In this paper, we propose Prioritized Subnet Sampling to train a resource-adaptive supernet, termed PSS-Net. We maintain multiple subnet pools, each of which stores the information of substantial subnets with similar resource consumption. Considering a resource constraint, subnets conditioned on this resource constraint are sampled from a pre-defined subnet structure space and high-quality ones will be inserted into the corresponding subnet pool. Then, the sampling will gradually be prone to sampling subnets from the subnet pools. Moreover, the one with a better performance metric is assigned with higher priority to train our PSS-Net, if sampling is from a subnet pool. At the end of training, our PSS-Net retains the best subnet in each pool to entitle a fast switch of high-quality subnets for inference when the available resources vary. Experiments on ImageNet using MobileNetV1/V2 show that our PSS-Net can well outperform state-of-the-art resource-adaptive supernets. Our project is at https://github.com/chenbong/PSS-Net.
Wavelet-Based Network For High Dynamic Range Imaging
Aug 03, 2021


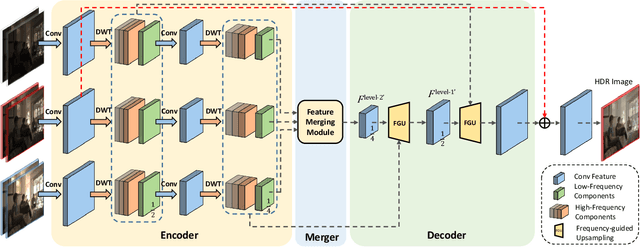
High dynamic range (HDR) imaging from multiple low dynamic range (LDR) images has been suffering from ghosting artifacts caused by scene and objects motion. Existing methods, such as optical flow based and end-to-end deep learning based solutions, are error-prone either in detail restoration or ghosting artifacts removal. Comprehensive empirical evidence shows that ghosting artifacts caused by large foreground motion are mainly low-frequency signals and the details are mainly high-frequency signals. In this work, we propose a novel frequency-guided end-to-end deep neural network (FHDRNet) to conduct HDR fusion in the frequency domain, and Discrete Wavelet Transform (DWT) is used to decompose inputs into different frequency bands. The low-frequency signals are used to avoid specific ghosting artifacts, while the high-frequency signals are used for preserving details. Using a U-Net as the backbone, we propose two novel modules: merging module and frequency-guided upsampling module. The merging module applies the attention mechanism to the low-frequency components to deal with the ghost caused by large foreground motion. The frequency-guided upsampling module reconstructs details from multiple frequency-specific components with rich details. In addition, a new RAW dataset is created for training and evaluating multi-frame HDR imaging algorithms in the RAW domain. Extensive experiments are conducted on public datasets and our RAW dataset, showing that the proposed FHDRNet achieves state-of-the-art performance.