 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM6-Rec: Generative Pretrained Language Models are Open-Ended Recommender Systems
May 19, 2022
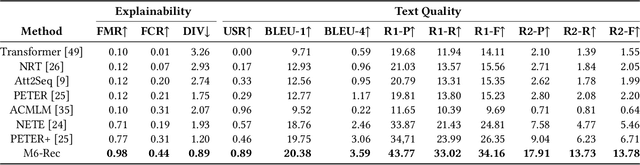
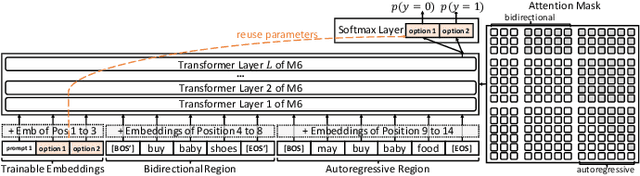

Industrial recommender systems have been growing increasingly complex, may involve \emph{diverse domains} such as e-commerce products and user-generated contents, and can comprise \emph{a myriad of tasks} such as retrieval, ranking, explanation generation, and even AI-assisted content production. The mainstream approach so far is to develop individual algorithms for each domain and each task. In this paper, we explore the possibility of developing a unified foundation model to support \emph{open-ended domains and tasks} in an industrial recommender system, which may reduce the demand on downstream settings' data and can minimize the carbon footprint by avoiding training a separate model from scratch for every task. Deriving a unified foundation is challenging due to (i) the potentially unlimited set of downstream domains and tasks, and (ii) the real-world systems' emphasis on computational efficiency. We thus build our foundation upon M6, an existing large-scale industrial pretrained language model similar to GPT-3 and T5, and leverage M6's pretrained ability for sample-efficient downstream adaptation, by representing user behavior data as plain texts and converting the tasks to either language understanding or generation. To deal with a tight hardware budget, we propose an improved version of prompt tuning that outperforms fine-tuning with negligible 1\% task-specific parameters, and employ techniques such as late interaction, early exiting, parameter sharing, and pruning to further reduce the inference time and the model size. We demonstrate the foundation model's versatility on a wide range of tasks such as retrieval, ranking, zero-shot recommendation, explanation generation, personalized content creation, and conversational recommendation, and manage to deploy it on both cloud servers and mobile devices.
Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
Feb 07, 2022
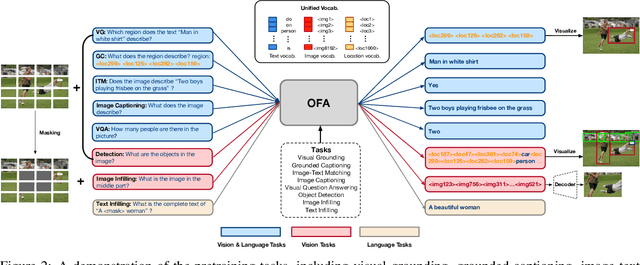
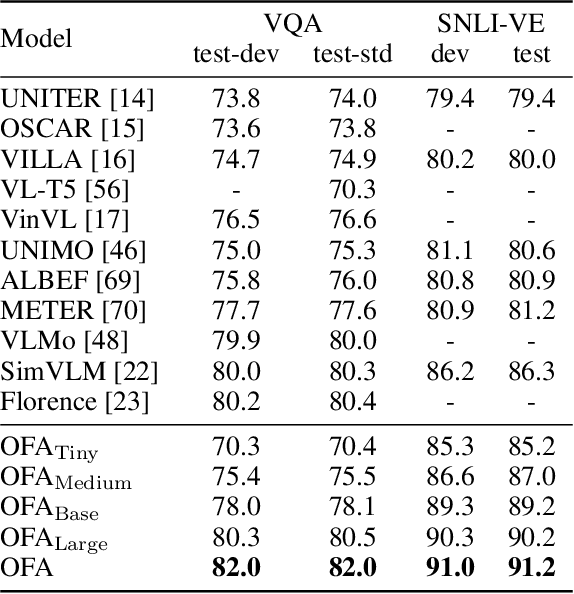
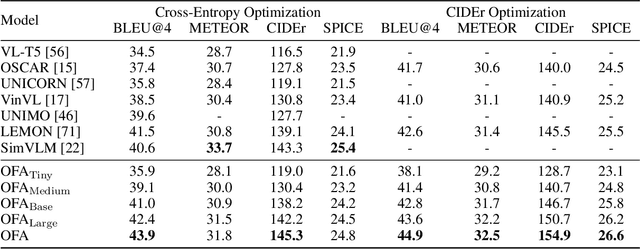
In this work, we pursue a unified paradigm for multimodal pretraining to break the scaffolds of complex task/modality-specific customization. We propose OFA, a unified multimodal pretrained model that unifies modalities (i.e., cross-modality, vision, language) and tasks (e.g., image generation, visual grounding, image captioning, image classification, text generation, etc.) to a simple sequence-to-sequence learning framework based on the encoder-decoder architecture. OFA performs pretraining and finetuning with task instructions and introduces no extra task-specific layers for finetuning. Experimental results show that OFA achieves new state-of-the-arts on a series of multimodal tasks, including image captioning (COCO test CIDEr: 149.6), text-to-image generation (COCO test FID: 10.5), VQA (test-std acc.: 80.02), SNLI-VE (test acc.: 90.20), and referring expression comprehension (RefCOCO / RefCOCO+ / RefCOCOg test acc.: 92.93 / 90.10 / 85.20). Through extensive analyses, we demonstrate that OFA reaches comparable performance with uni-modal pretrained models (e.g., BERT, MAE, MoCo v3, SimCLR v2, etc.) in uni-modal tasks, including NLU, NLG, and image classification, and it effectively transfers to unseen tasks and domains. Code shall be released soon at http://github.com/OFA-Sys/OFA
Edge-Cloud Polarization and Collaboration: A Comprehensive Survey
Nov 12, 2021
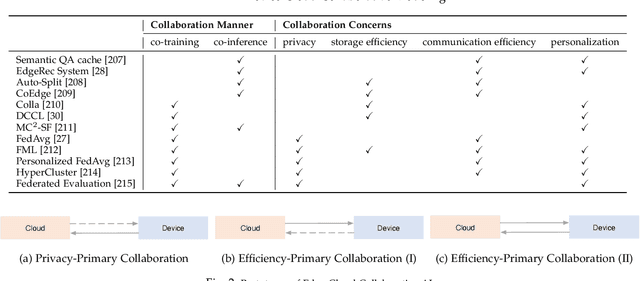
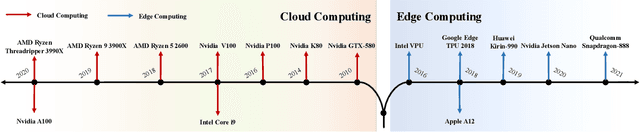
Influenced by the great success of deep learning via cloud computing and the rapid development of edge chips, research in artificial intelligence (AI) has shifted to both of the computing paradigms, i.e., cloud computing and edge computing. In recent years, we have witnessed significant progress in developing more advanced AI models on cloud servers that surpass traditional deep learning models owing to model innovations (e.g., Transformers, Pretrained families), explosion of training data and soaring computing capabilities. However, edge computing, especially edge and cloud collaborative computing, are still in its infancy to announce their success due to the resource-constrained IoT scenarios with very limited algorithms deployed. In this survey, we conduct a systematic review for both cloud and edge AI. Specifically, we are the first to set up the collaborative learning mechanism for cloud and edge modeling with a thorough review of the architectures that enable such mechanism. We also discuss potentials and practical experiences of some on-going advanced edge AI topics including pretraining models, graph neural networks and reinforcement learning. Finally, we discuss the promising directions and challenges in this field.
Learning to Rehearse in Long Sequence Memorization
Jun 02, 2021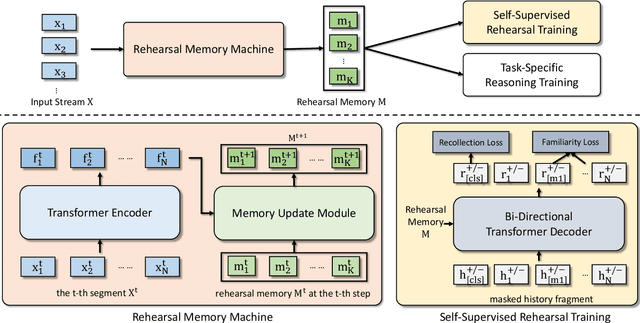
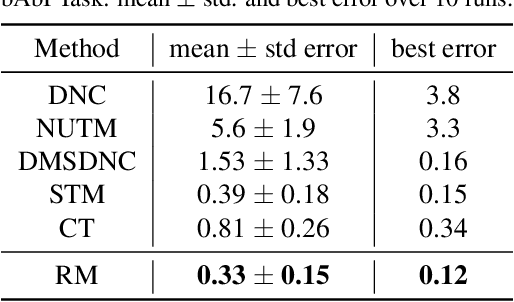
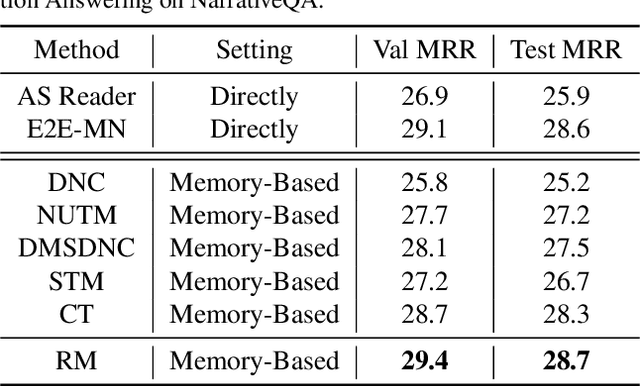
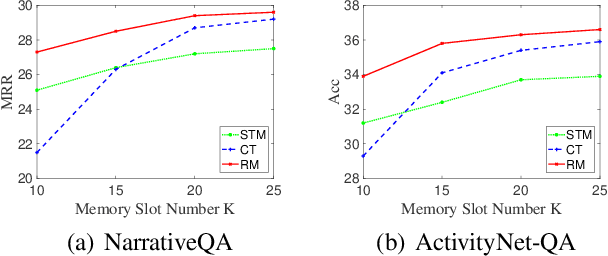
Existing reasoning tasks often have an important assumption that the input contents can be always accessed while reasoning, requiring unlimited storage resources and suffering from severe time delay on long sequences. To achieve efficient reasoning on long sequences with limited storage resources, memory augmented neural networks introduce a human-like write-read memory to compress and memorize the long input sequence in one pass, trying to answer subsequent queries only based on the memory. But they have two serious drawbacks: 1) they continually update the memory from current information and inevitably forget the early contents; 2) they do not distinguish what information is important and treat all contents equally. In this paper, we propose the Rehearsal Memory (RM) to enhance long-sequence memorization by self-supervised rehearsal with a history sampler. To alleviate the gradual forgetting of early information, we design self-supervised rehearsal training with recollection and familiarity tasks. Further, we design a history sampler to select informative fragments for rehearsal training, making the memory focus on the crucial information. We evaluate the performance of our rehearsal memory by the synthetic bAbI task and several downstream tasks, including text/video question answering and recommendation on long sequences.
UFC-BERT: Unifying Multi-Modal Controls for Conditional Image Synthesis
May 29, 2021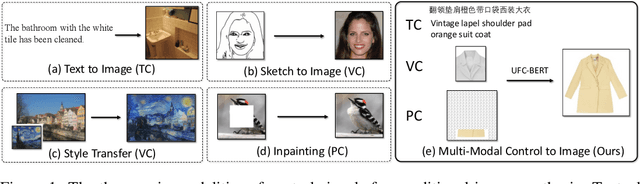

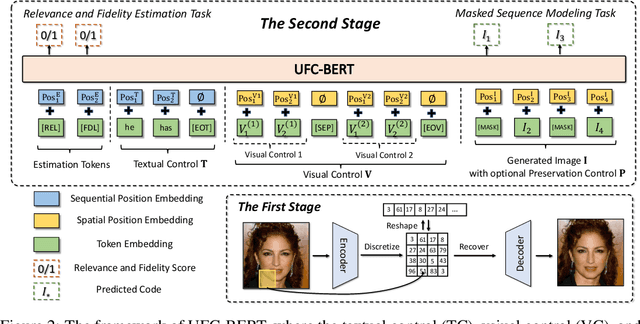
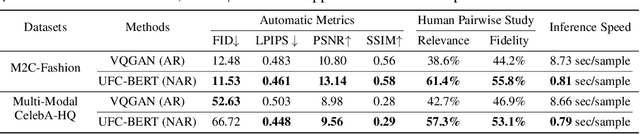
Conditional image synthesis aims to create an image according to some multi-modal guidance in the forms of textual descriptions, reference images, and image blocks to preserve, as well as their combinations. In this paper, instead of investigating these control signals separately, we propose a new two-stage architecture, UFC-BERT, to unify any number of multi-modal controls. In UFC-BERT, both the diverse control signals and the synthesized image are uniformly represented as a sequence of discrete tokens to be processed by Transformer. Different from existing two-stage autoregressive approaches such as DALL-E and VQGAN, UFC-BERT adopts non-autoregressive generation (NAR) at the second stage to enhance the holistic consistency of the synthesized image, to support preserving specified image blocks, and to improve the synthesis speed. Further, we design a progressive algorithm that iteratively improves the non-autoregressively generated image, with the help of two estimators developed for evaluating the compliance with the controls and evaluating the fidelity of the synthesized image, respectively. Extensive experiments on a newly collected large-scale clothing dataset M2C-Fashion and a facial dataset Multi-Modal CelebA-HQ verify that UFC-BERT can synthesize high-fidelity images that comply with flexible multi-modal controls.
M6: A Chinese Multimodal Pretrainer
Mar 02, 2021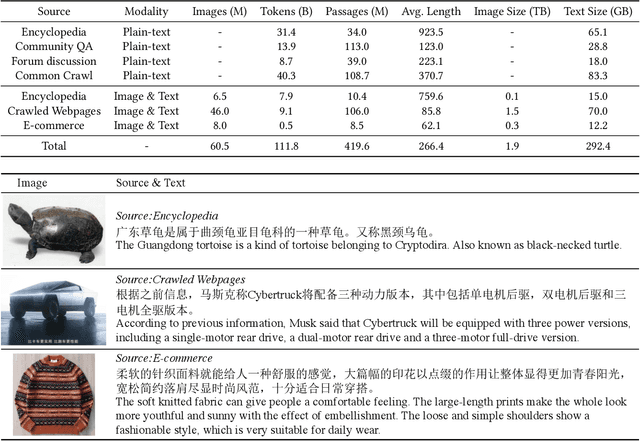
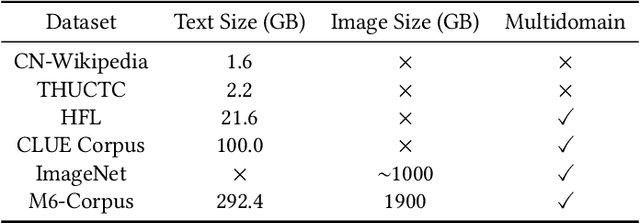

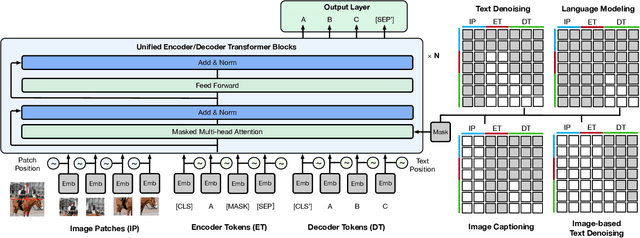
In this work, we construct the largest dataset for multimodal pretraining in Chinese, which consists of over 1.9TB images and 292GB texts that cover a wide range of domains. We propose a cross-modal pretraining method called M6, referring to Multi-Modality to Multi-Modality Multitask Mega-transformer, for unified pretraining on the data of single modality and multiple modalities. We scale the model size up to 10 billion and 100 billion parameters, and build the largest pretrained model in Chinese. We apply the model to a series of downstream applications, and demonstrate its outstanding performance in comparison with strong baselines. Furthermore, we specifically design a downstream task of text-guided image generation, and show that the finetuned M6 can create high-quality images with high resolution and abundant details.
Inductive Granger Causal Modeling for Multivariate Time Series
Feb 10, 2021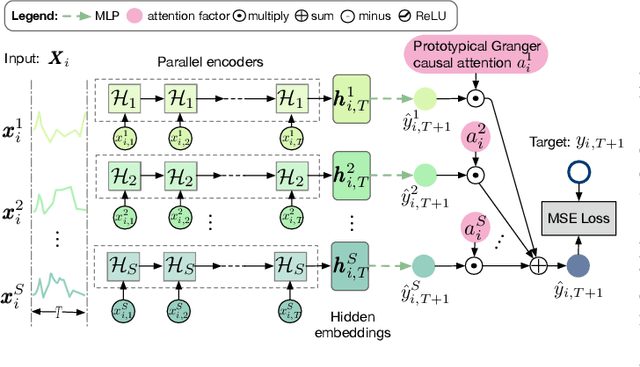
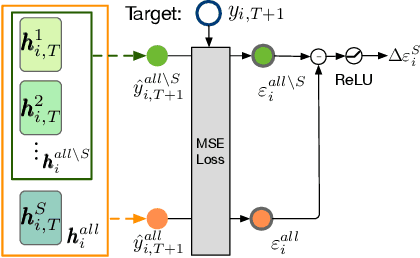

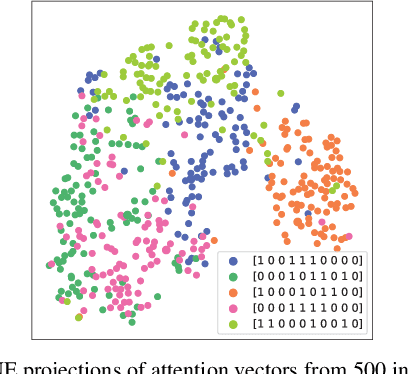
Granger causal modeling is an emerging topic that can uncover Granger causal relationship behind multivariate time series data. In many real-world systems, it is common to encounter a large amount of multivariate time series data collected from different individuals with sharing commonalities. However, there are ongoing concerns regarding Granger causality's applicability in such large scale complex scenarios, presenting both challenges and opportunities for Granger causal structure reconstruction. Existing methods usually train a distinct model for each individual, suffering from inefficiency and over-fitting issues. To bridge this gap, we propose an Inductive GRanger cAusal modeling (InGRA) framework for inductive Granger causality learning and common causal structure detection on multivariate time series, which exploits the shared commonalities underlying the different individuals. In particular, we train one global model for individuals with different Granger causal structures through a novel attention mechanism, called prototypical Granger causal attention. The model can detect common causal structures for different individuals and infer Granger causal structures for newly arrived individuals. Extensive experiments, as well as an online A/B test on an E-commercial advertising platform, demonstrate the superior performances of InGRA.
Contrastive Learning for Debiased Candidate Generation in Large-Scale Recommender Systems
Jun 11, 2020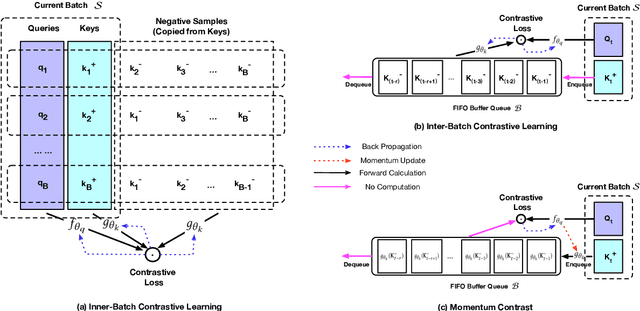
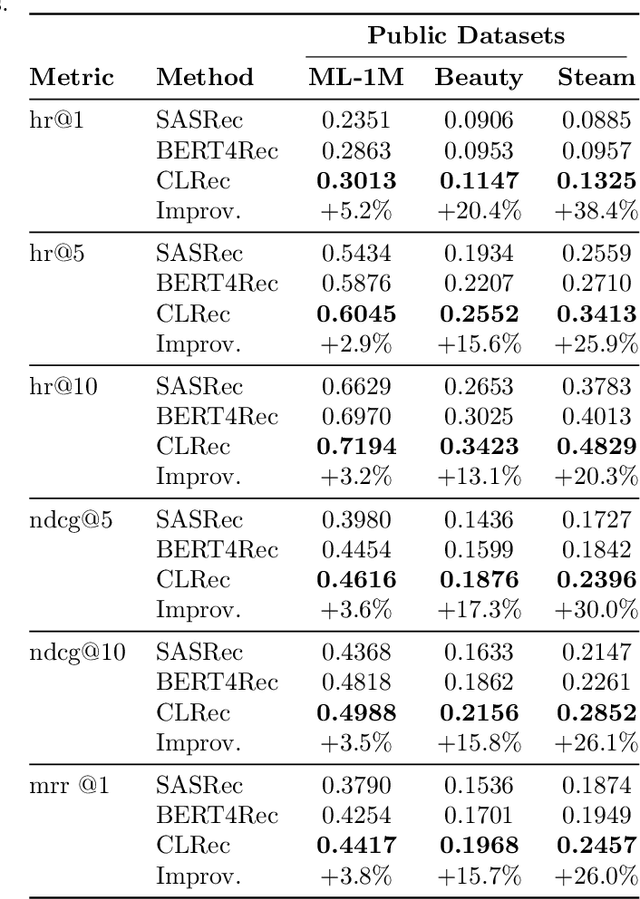

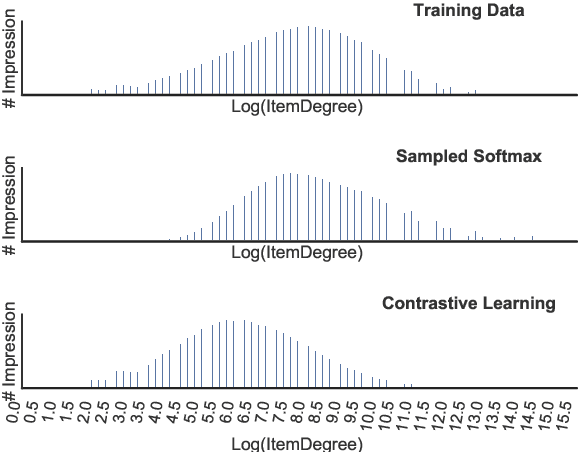
Deep candidate generation (DCG) that narrows down the collection of relevant items from billions to hundreds via representation learning is essential to large-scale recommender systems. Standard approaches approximate maximum likelihood estimation (MLE) through sampling for better scalability and address the problem of DCG in a way similar to language modeling. However, live recommender systems face severe unfairness of exposure with a vocabulary several orders of magnitude larger than that of natural language, implying that (1) MLE will preserve and even exacerbate the exposure bias in the long run in order to faithfully fit the observed samples, and (2) suboptimal sampling and inadequate use of item features can lead to inferior representations for the unfairly ignored items. In this paper, we introduce CLRec, a Contrastive Learning paradigm that has been successfully deployed in a real-world massive recommender system, to alleviate exposure bias in DCG. We theoretically prove that a popular choice of contrastive loss is equivalently reducing the exposure bias via inverse propensity scoring, which provides a new perspective on the effectiveness of contrastive learning. We further employ a fixed-size queue to store the items' representations computed in previously processed batches, and use the queue to serve as an effective sampler of negative examples. This queue-based design provides great efficiency in incorporating rich features of the thousand negative items per batch thanks to computation reuse. Extensive offline analyses and four-month online A/B tests in Mobile Taobao demonstrate substantial improvement, including a dramatic reduction in the Matthew effect.
Learning Disentangled Representations for Recommendation
Oct 31, 2019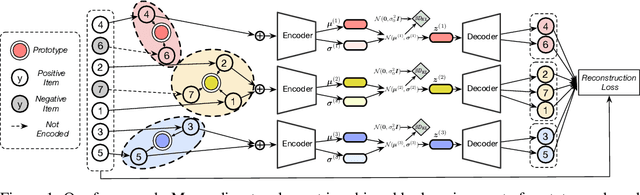
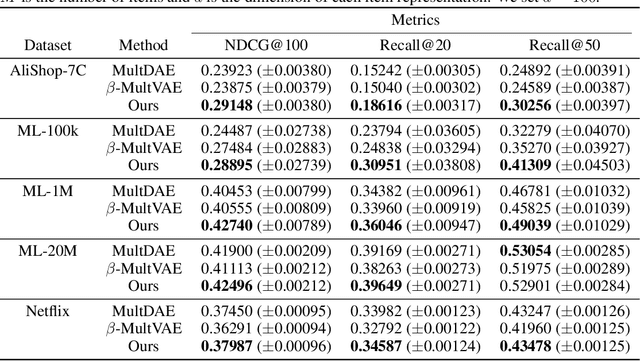
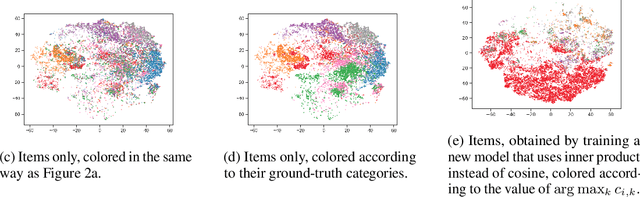
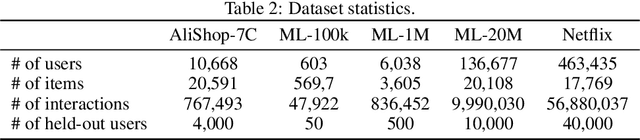
User behavior data in recommender systems are driven by the complex interactions of many latent factors behind the users' decision making processes. The factors are highly entangled, and may range from high-level ones that govern user intentions, to low-level ones that characterize a user's preference when executing an intention. Learning representations that uncover and disentangle these latent factors can bring enhanced robustness, interpretability, and controllability. However, learning such disentangled representations from user behavior is challenging, and remains largely neglected by the existing literature. In this paper, we present the MACRo-mIcro Disentangled Variational Auto-Encoder (MacridVAE) for learning disentangled representations from user behavior. Our approach achieves macro disentanglement by inferring the high-level concepts associated with user intentions (e.g., to buy a shirt or a cellphone), while capturing the preference of a user regarding the different concepts separately. A micro-disentanglement regularizer, stemming from an information-theoretic interpretation of VAEs, then forces each dimension of the representations to independently reflect an isolated low-level factor (e.g., the size or the color of a shirt). Empirical results show that our approach can achieve substantial improvement over the state-of-the-art baselines. We further demonstrate that the learned representations are interpretable and controllable, which can potentially lead to a new paradigm for recommendation where users are given fine-grained control over targeted aspects of the recommendation lists.