 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUFC-BERT: Unifying Multi-Modal Controls for Conditional Image Synthesis
Paper and Code
May 29, 2021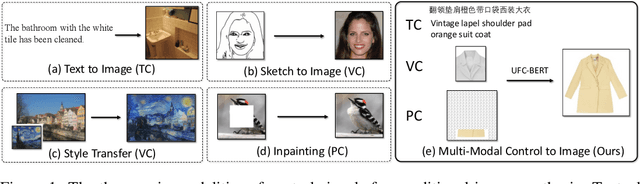

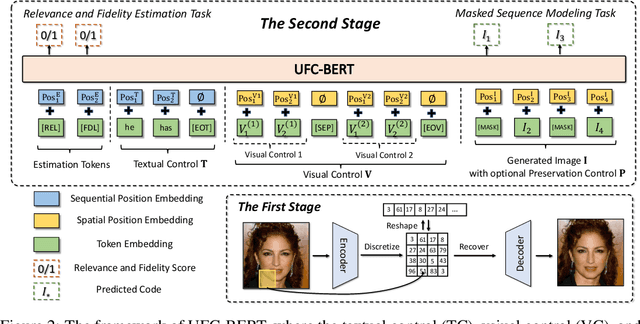
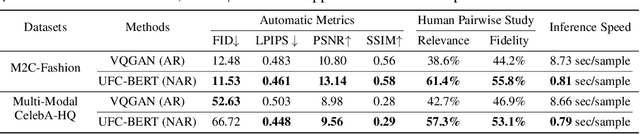
Conditional image synthesis aims to create an image according to some multi-modal guidance in the forms of textual descriptions, reference images, and image blocks to preserve, as well as their combinations. In this paper, instead of investigating these control signals separately, we propose a new two-stage architecture, UFC-BERT, to unify any number of multi-modal controls. In UFC-BERT, both the diverse control signals and the synthesized image are uniformly represented as a sequence of discrete tokens to be processed by Transformer. Different from existing two-stage autoregressive approaches such as DALL-E and VQGAN, UFC-BERT adopts non-autoregressive generation (NAR) at the second stage to enhance the holistic consistency of the synthesized image, to support preserving specified image blocks, and to improve the synthesis speed. Further, we design a progressive algorithm that iteratively improves the non-autoregressively generated image, with the help of two estimators developed for evaluating the compliance with the controls and evaluating the fidelity of the synthesized image, respectively. Extensive experiments on a newly collected large-scale clothing dataset M2C-Fashion and a facial dataset Multi-Modal CelebA-HQ verify that UFC-BERT can synthesize high-fidelity images that comply with flexible multi-modal controls.