 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Forgery Detection Challenge 2022: Push the Frontier of Unconstrained and Diverse Forgery Detection
Jul 27, 2022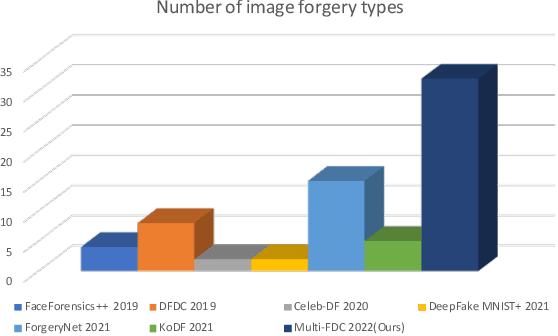

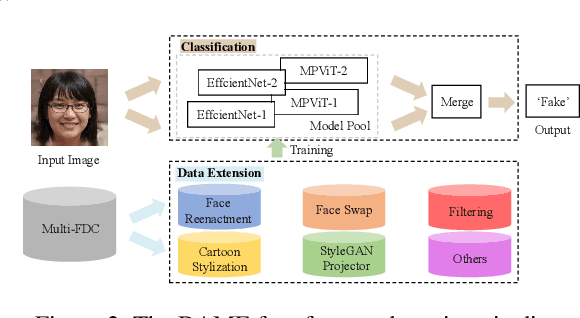
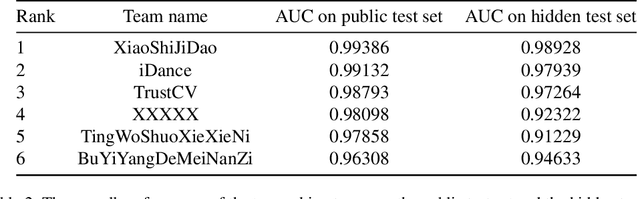
In this paper, we present the Multi-Forgery Detection Challenge held concurrently with the IEEE Computer Society Workshop on Biometrics at CVPR 2022. Our Multi-Forgery Detection Challenge aims to detect automatic image manipulations including but not limited to image editing, image synthesis, image generation, image photoshop, etc. Our challenge has attracted 674 teams from all over the world, with about 2000 valid result submission counts. We invited the Top 10 teams to present their solutions to the challenge, from which three teams are awarded prizes in the grand finale. In this paper, we present the solutions from the Top 3 teams, in order to boost the research work in the field of image forgery detection.
CelebA-Spoof Challenge 2020 on Face Anti-Spoofing: Methods and Results
Feb 26, 2021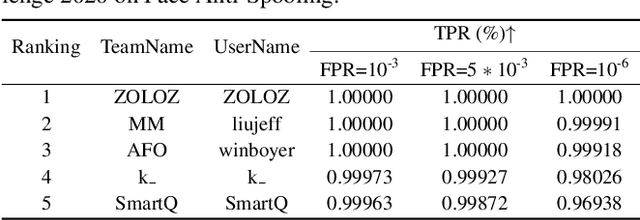
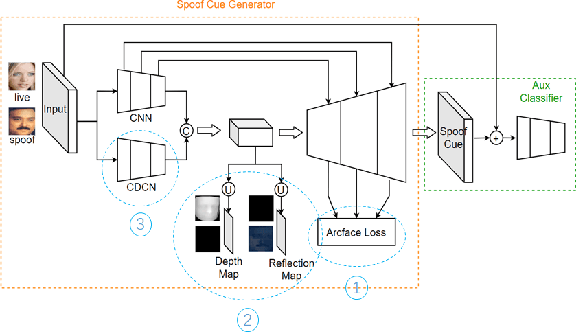
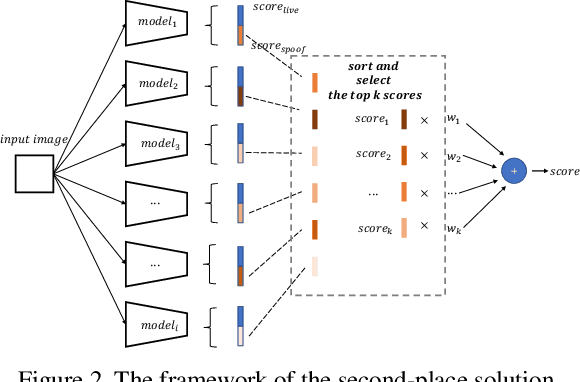
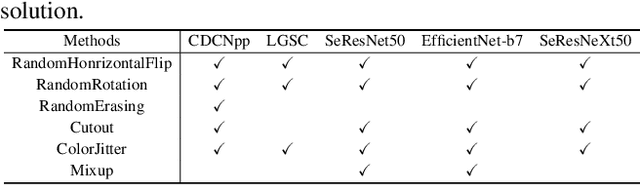
As facial interaction systems are prevalently deployed, security and reliability of these systems become a critical issue, with substantial research efforts devoted. Among them, face anti-spoofing emerges as an important area, whose objective is to identify whether a presented face is live or spoof. Recently, a large-scale face anti-spoofing dataset, CelebA-Spoof which comprised of 625,537 pictures of 10,177 subjects has been released. It is the largest face anti-spoofing dataset in terms of the numbers of the data and the subjects. This paper reports methods and results in the CelebA-Spoof Challenge 2020 on Face AntiSpoofing which employs the CelebA-Spoof dataset. The model evaluation is conducted online on the hidden test set. A total of 134 participants registered for the competition, and 19 teams made valid submissions. We will analyze the top ranked solutions and present some discussion on future work directions.
Multi-Prototype Networks for Unconstrained Set-based Face Recognition
Mar 23, 2019
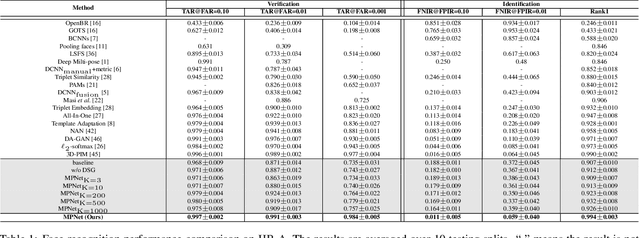
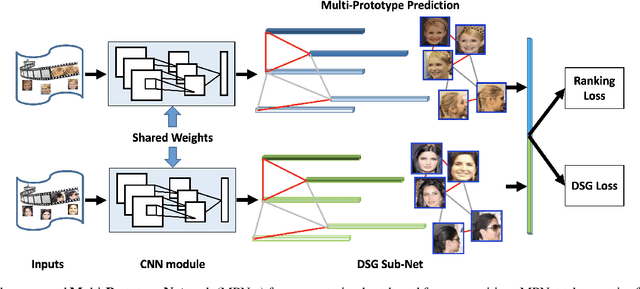
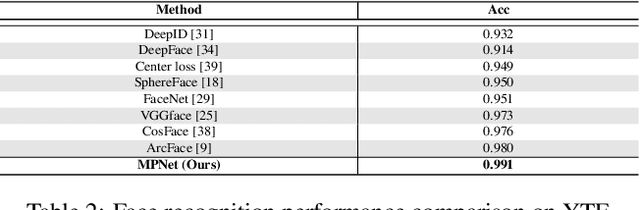
In this paper, we study the challenging unconstrained set-based face recognition problem where each subject face is instantiated by a set of media (images and videos) instead of a single image. Naively aggregating information from all the media within a set would suffer from the large intra-set variance caused by heterogeneous factors (e.g., varying media modalities, poses and illuminations) and fail to learn discriminative face representations. A novel Multi-Prototype Network (MPNet) model is thus proposed to learn multiple prototype face representations adaptively from the media sets. Each learned prototype is representative for the subject face under certain condition in terms of pose, illumination and media modality. Instead of handcrafting the set partition for prototype learning, MPNet introduces a Dense SubGraph (DSG) learning sub-net that implicitly untangles inconsistent media and learns a number of representative prototypes. Qualitative and quantitative experiments clearly demonstrate superiority of the proposed model over state-of-the-arts.
Learning Generalizable and Identity-Discriminative Representations for Face Anti-Spoofing
Jan 17, 2019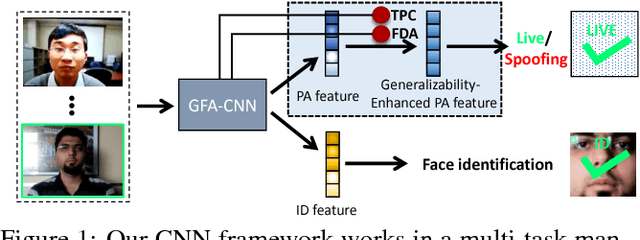
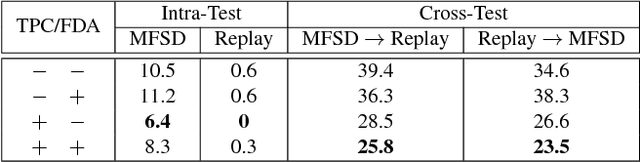
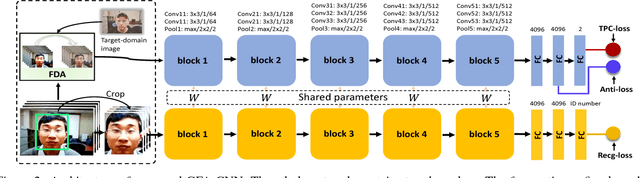

Face anti-spoofing (a.k.a presentation attack detection) has drawn growing attention due to the high-security demand in face authentication systems. Existing CNN-based approaches usually well recognize the spoofing faces when training and testing spoofing samples display similar patterns, but their performance would drop drastically on testing spoofing faces of unseen scenes. In this paper, we try to boost the generalizability and applicability of these methods by designing a CNN model with two major novelties. First, we propose a simple yet effective Total Pairwise Confusion (TPC) loss for CNN training, which enhances the generalizability of the learned Presentation Attack (PA) representations. Secondly, we incorporate a Fast Domain Adaptation (FDA) component into the CNN model to alleviate negative effects brought by domain changes. Besides, our proposed model, which is named Generalizable Face Authentication CNN (GFA-CNN), works in a multi-task manner, performing face anti-spoofing and face recognition simultaneously. Experimental results show that GFA-CNN outperforms previous face anti-spoofing approaches and also well preserves the identity information of input face images.
$A^2$-Nets: Double Attention Networks
Oct 27, 2018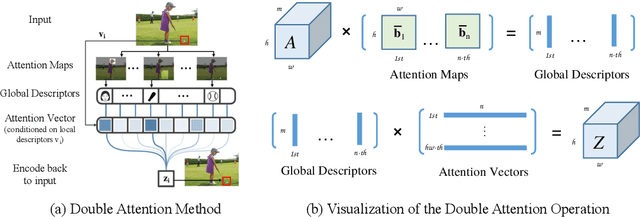
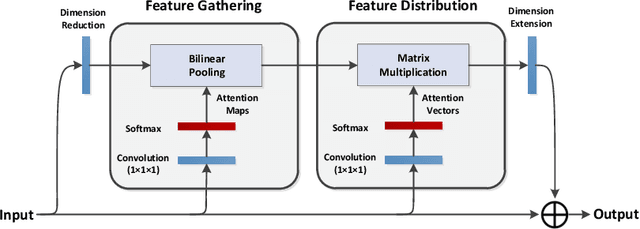
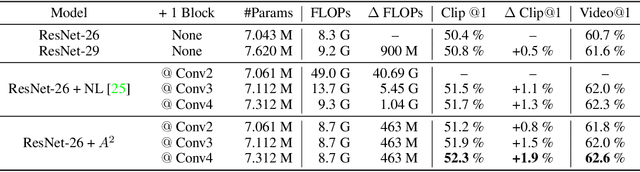
Learning to capture long-range relations is fundamental to image/video recognition. Existing CNN models generally rely on increasing depth to model such relations which is highly inefficient. In this work, we propose the "double attention block", a novel component that aggregates and propagates informative global features from the entire spatio-temporal space of input images/videos, enabling subsequent convolution layers to access features from the entire space efficiently. The component is designed with a double attention mechanism in two steps, where the first step gathers features from the entire space into a compact set through second-order attention pooling and the second step adaptively selects and distributes features to each location via another attention. The proposed double attention block is easy to adopt and can be plugged into existing deep neural networks conveniently. We conduct extensive ablation studies and experiments on both image and video recognition tasks for evaluating its performance. On the image recognition task, a ResNet-50 equipped with our double attention blocks outperforms a much larger ResNet-152 architecture on ImageNet-1k dataset with over 40% less the number of parameters and less FLOPs. On the action recognition task, our proposed model achieves the state-of-the-art results on the Kinetics and UCF-101 datasets with significantly higher efficiency than recent works.
Look Across Elapse: Disentangled Representation Learning and Photorealistic Cross-Age Face Synthesis for Age-Invariant Face Recognition
Oct 04, 2018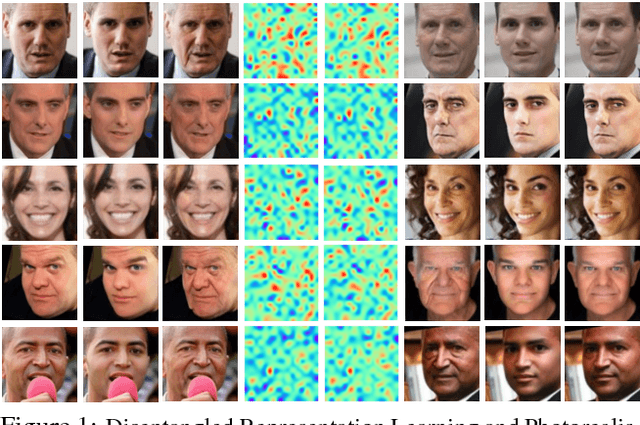
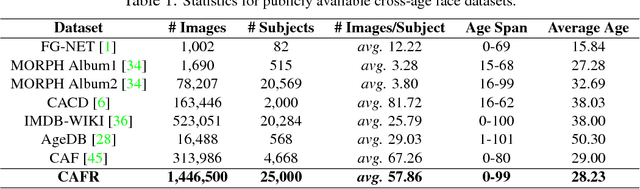
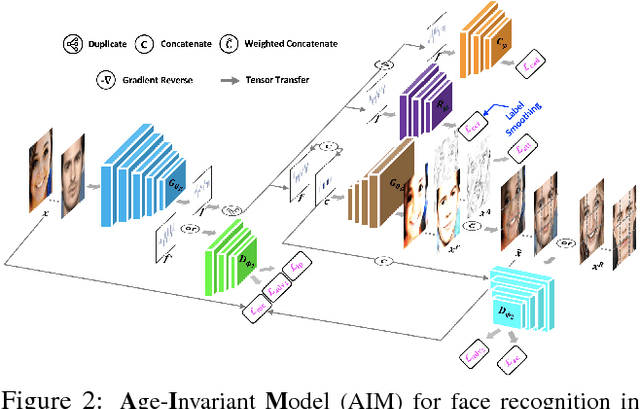
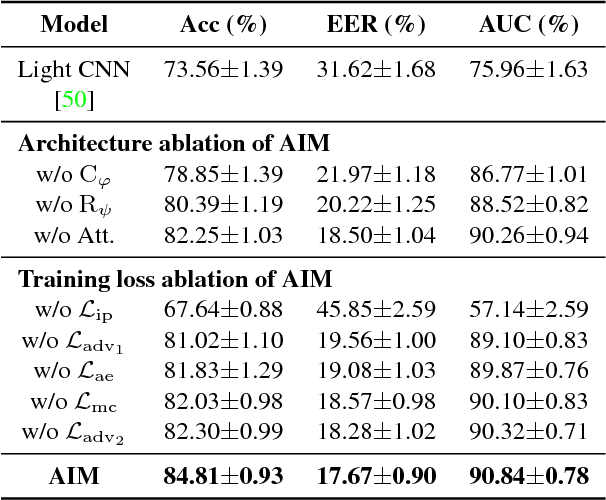
Despite the remarkable progress in face recognition related technologies, reliably recognizing faces across ages still remains a big challenge. The appearance of a human face changes substantially over time, resulting in significant intra-class variations. As opposed to current techniques for age-invariant face recognition, which either directly extract age-invariant features for recognition, or first synthesize a face that matches target age before feature extraction, we argue that it is more desirable to perform both tasks jointly so that they can leverage each other. To this end, we propose a deep Age-Invariant Model (AIM) for face recognition in the wild with three distinct novelties. First, AIM presents a novel unified deep architecture jointly performing cross-age face synthesis and recognition in a mutual boosting way. Second, AIM achieves continuous face rejuvenation/aging with remarkable photorealistic and identity-preserving properties, avoiding the requirement of paired data and the true age of testing samples. Third, we develop effective and novel training strategies for end-to-end learning the whole deep architecture, which generates powerful age-invariant face representations explicitly disentangled from the age variation. Moreover, we propose a new large-scale Cross-Age Face Recognition (CAFR) benchmark dataset to facilitate existing efforts and push the frontiers of age-invariant face recognition research. Extensive experiments on both our CAFR and several other cross-age datasets (MORPH, CACD and FG-NET) demonstrate the superiority of the proposed AIM model over the state-of-the-arts. Benchmarking our model on one of the most popular unconstrained face recognition datasets IJB-C additionally verifies the promising generalizability of AIM in recognizing faces in the wild.
Multi-Fiber Networks for Video Recognition
Sep 18, 2018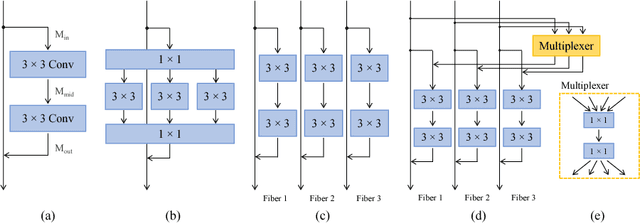
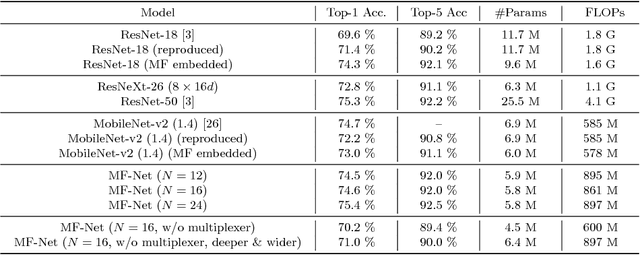
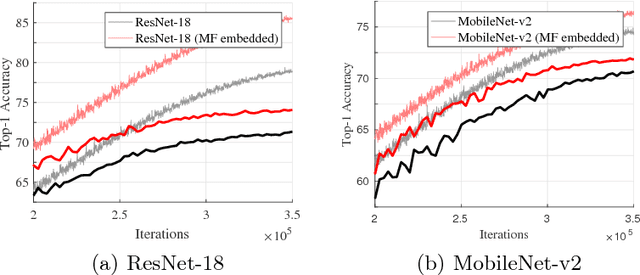
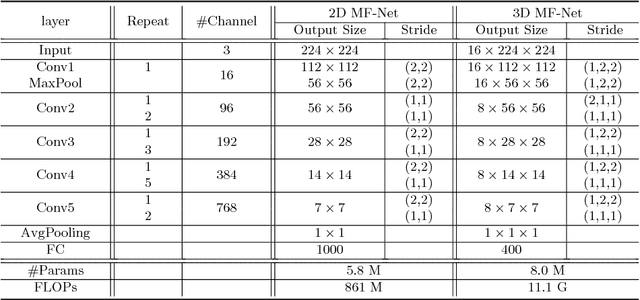
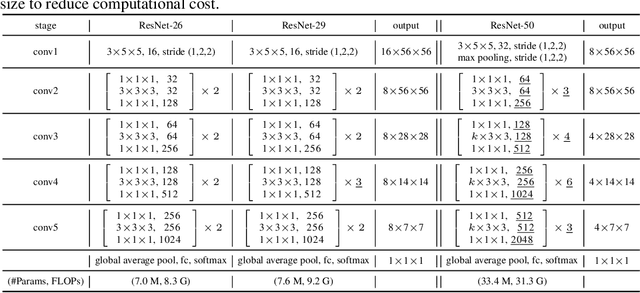
In this paper, we aim to reduce the computational cost of spatio-temporal deep neural networks, making them run as fast as their 2D counterparts while preserving state-of-the-art accuracy on video recognition benchmarks. To this end, we present the novel Multi-Fiber architecture that slices a complex neural network into an ensemble of lightweight networks or fibers that run through the network. To facilitate information flow between fibers we further incorporate multiplexer modules and end up with an architecture that reduces the computational cost of 3D networks by an order of magnitude, while increasing recognition performance at the same time. Extensive experimental results show that our multi-fiber architecture significantly boosts the efficiency of existing convolution networks for both image and video recognition tasks, achieving state-of-the-art performance on UCF-101, HMDB-51 and Kinetics datasets. Our proposed model requires over 9x and 13x less computations than the I3D and R(2+1)D models, respectively, yet providing higher accuracy.
Object Relation Detection Based on One-shot Learning
Jul 16, 2018
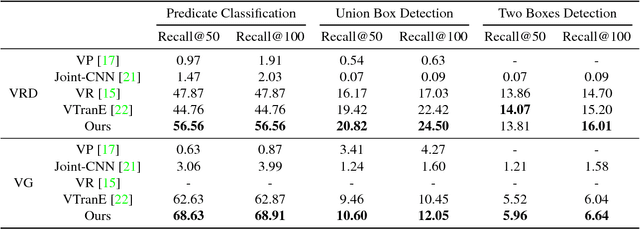

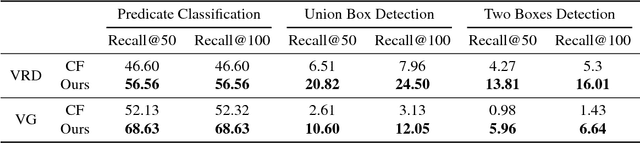
Detecting the relations among objects, such as "cat on sofa" and "person ride horse", is a crucial task in image understanding, and beneficial to bridging the semantic gap between images and natural language. Despite the remarkable progress of deep learning in detection and recognition of individual objects, it is still a challenging task to localize and recognize the relations between objects due to the complex combinatorial nature of various kinds of object relations. Inspired by the recent advances in one-shot learning, we propose a simple yet effective Semantics Induced Learner (SIL) model for solving this challenging task. Learning in one-shot manner can enable a detection model to adapt to a huge number of object relations with diverse appearance effectively and robustly. In addition, the SIL combines bottom-up and top-down attention mech- anisms, therefore enabling attention at the level of vision and semantics favorably. Within our proposed model, the bottom-up mechanism, which is based on Faster R-CNN, proposes objects regions, and the top-down mechanism selects and integrates visual features according to semantic information. Experiments demonstrate the effectiveness of our framework over other state-of-the-art methods on two large-scale data sets for object relation detection.
Understanding Humans in Crowded Scenes: Deep Nested Adversarial Learning and A New Benchmark for Multi-Human Parsing
Jul 06, 2018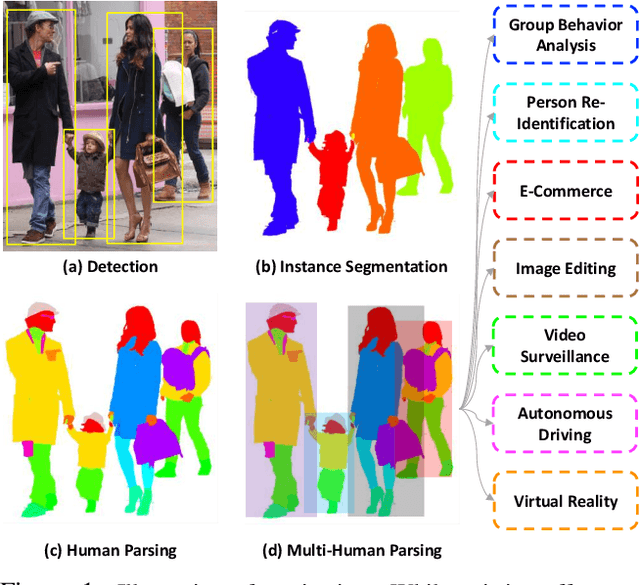
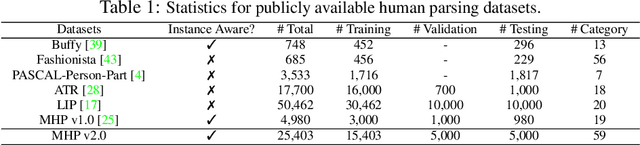

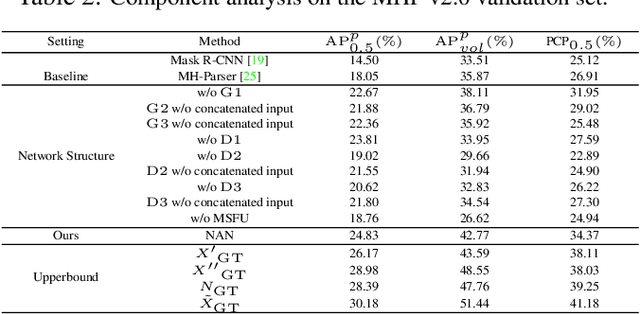
Despite the noticeable progress in perceptual tasks like detection, instance segmentation and human parsing, computers still perform unsatisfactorily on visually understanding humans in crowded scenes, such as group behavior analysis, person re-identification and autonomous driving, etc. To this end, models need to comprehensively perceive the semantic information and the differences between instances in a multi-human image, which is recently defined as the multi-human parsing task. In this paper, we present a new large-scale database "Multi-Human Parsing (MHP)" for algorithm development and evaluation, and advances the state-of-the-art in understanding humans in crowded scenes. MHP contains 25,403 elaborately annotated images with 58 fine-grained semantic category labels, involving 2-26 persons per image and captured in real-world scenes from various viewpoints, poses, occlusion, interactions and background. We further propose a novel deep Nested Adversarial Network (NAN) model for multi-human parsing. NAN consists of three Generative Adversarial Network (GAN)-like sub-nets, respectively performing semantic saliency prediction, instance-agnostic parsing and instance-aware clustering. These sub-nets form a nested structure and are carefully designed to learn jointly in an end-to-end way. NAN consistently outperforms existing state-of-the-art solutions on our MHP and several other datasets, and serves as a strong baseline to drive the future research for multi-human parsing.
Multiple-Human Parsing in the Wild
Mar 15, 2018

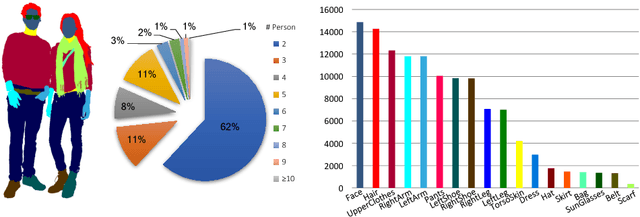
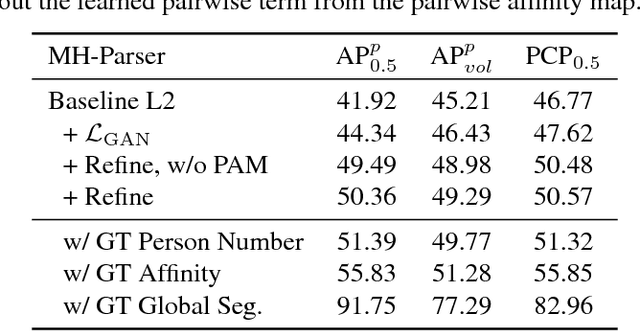
Human parsing is attracting increasing research attention. In this work, we aim to push the frontier of human parsing by introducing the problem of multi-human parsing in the wild. Existing works on human parsing mainly tackle single-person scenarios, which deviates from real-world applications where multiple persons are present simultaneously with interaction and occlusion. To address the multi-human parsing problem, we introduce a new multi-human parsing (MHP) dataset and a novel multi-human parsing model named MH-Parser. The MHP dataset contains multiple persons captured in real-world scenes with pixel-level fine-grained semantic annotations in an instance-aware setting. The MH-Parser generates global parsing maps and person instance masks simultaneously in a bottom-up fashion with the help of a new Graph-GAN model. We envision that the MHP dataset will serve as a valuable data resource to develop new multi-human parsing models, and the MH-Parser offers a strong baseline to drive future research for multi-human parsing in the wild.