 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Framework for All: Cross-Modal Membership Inference for Generative Models
Jul 05, 2026Large generative models across text-to-text, text-to-image, and image-to-text modalities have been shown to pose significant privacy risks. One fundamental threat is membership inference attacks (MIA), which aim to determine whether a given data point was used in a model's training set. Although prior work has investigated MIAs against these three classes of generative models, existing approaches treat them in isolation and are not cross-applicable, thereby limiting their real-world utility. To address this limitation, we present the first comprehensive study of a unified membership inference framework that applies across text-to-text, text-to-image, and image-to-text modalities. Our approach is grounded in a key modality-agnostic observation: the output distribution of a generative model can approximate its training data distribution. Leveraging this property, we model the distributions of model-generated outputs and auxiliary non-member samples in a shared embedding space, and perform membership inference via likelihood ratio testing. We conduct extensive experiments in a strict black-box setting under both partial-knowledge and zero-knowledge threat models, and evaluate membership inference against both fine-tuning and pre-training data. Experimental results demonstrate our approach's superior performance in comparison to existing state-of-the-art methods, which are typically optimized for a single model class.
AudioDER: A Deduplication-Enhanced Reasoning Dataset for Post-Training Large Audio-Language Models
Jun 12, 2026Large Audio-Language Models (LALMs) have shown strong performance on a wide range of audio understanding tasks, yet they still struggle with complex audio reasoning. A practical way to improve such capabilities is post-training, whose effectiveness critically depends on the quality and diversity of training data. However, existing audio-language datasets often contain substantial redundancy, where many samples are highly similar in acoustic content and thus provide overlapping supervisory signals. Such redundancy not only increases annotation cost, but also limits corpus diversity and reduces the effectiveness of post-training. To address this issue, we propose a redundancy-aware data construction pipeline for building reasoning-oriented supervision for LALMs. Specifically, we first perform acoustic similarity-based deduplication across raw audio datasets to improve corpus diversity. We then integrate existing audio captions and question-answer pairs into a unified multiple-choice format. Based on these unified annotations, we leverage Qwen3-30B to generate chain-of-thought (CoT) rationales for reasoning-oriented supervision. Based on this pipeline, we construct AudioDER, a reasoning-oriented post-training dataset containing approximately 191k samples spanning sound, speech, and music. Each sample consists of an audio clip, a multiple-choice question, four answer candidates, an audio caption, and a CoT rationale. Extensive experiments show that post-training on AudioDER consistently improves the performance of Qwen2-Audio-7B-Instruct on multiple audio reasoning benchmarks, including MMAU-mini, MMSU, and MMAR. We hope AudioDER can serve as a valuable resource for advancing audio reasoning research and the development of more capable LALMs.
Game-Theoretic Machine Unlearning: Mitigating Extra Privacy Leakage
Nov 06, 2024With the extensive use of machine learning technologies, data providers encounter increasing privacy risks. Recent legislation, such as GDPR, obligates organizations to remove requested data and its influence from a trained model. Machine unlearning is an emerging technique designed to enable machine learning models to erase users' private information. Although several efficient machine unlearning schemes have been proposed, these methods still have limitations. First, removing the contributions of partial data may lead to model performance degradation. Second, discrepancies between the original and generated unlearned models can be exploited by attackers to obtain target sample's information, resulting in additional privacy leakage risks. To address above challenges, we proposed a game-theoretic machine unlearning algorithm that simulates the competitive relationship between unlearning performance and privacy protection. This algorithm comprises unlearning and privacy modules. The unlearning module possesses a loss function composed of model distance and classification error, which is used to derive the optimal strategy. The privacy module aims to make it difficult for an attacker to infer membership information from the unlearned data, thereby reducing the privacy leakage risk during the unlearning process. Additionally, the experimental results on real-world datasets demonstrate that this game-theoretic unlearning algorithm's effectiveness and its ability to generate an unlearned model with a performance similar to that of the retrained one while mitigating extra privacy leakage risks.
EAFP-Med: An Efficient Adaptive Feature Processing Module Based on Prompts for Medical Image Detection
Nov 27, 2023



In the face of rapid advances in medical imaging, cross-domain adaptive medical image detection is challenging due to the differences in lesion representations across various medical imaging technologies. To address this issue, we draw inspiration from large language models to propose EAFP-Med, an efficient adaptive feature processing module based on prompts for medical image detection. EAFP-Med can efficiently extract lesion features of different scales from a diverse range of medical images based on prompts while being flexible and not limited by specific imaging techniques. Furthermore, it serves as a feature preprocessing module that can be connected to any model front-end to enhance the lesion features in input images. Moreover, we propose a novel adaptive disease detection model named EAFP-Med ST, which utilizes the Swin Transformer V2 - Tiny (SwinV2-T) as its backbone and connects it to EAFP-Med. We have compared our method to nine state-of-the-art methods. Experimental results demonstrate that EAFP-Med ST achieves the best performance on all three datasets (chest X-ray images, cranial magnetic resonance imaging images, and skin images). EAFP-Med can efficiently extract lesion features from various medical images based on prompts, enhancing the model's performance. This holds significant potential for improving medical image analysis and diagnosis.
Multi-Prototype Networks for Unconstrained Set-based Face Recognition
Mar 23, 2019
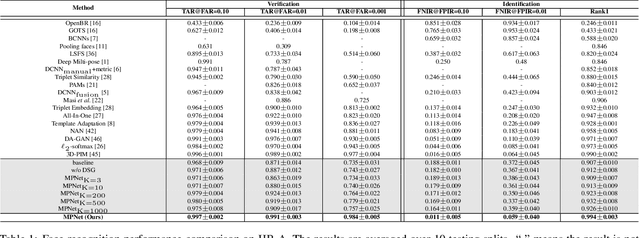
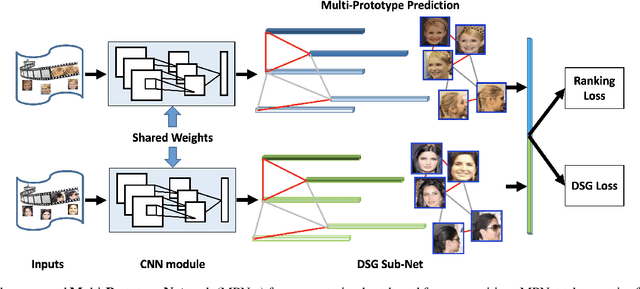
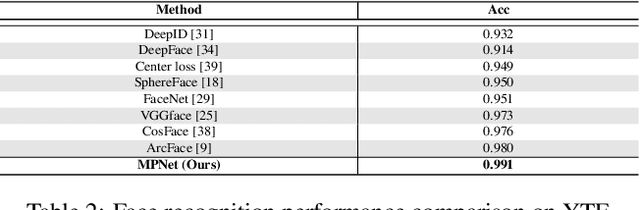
In this paper, we study the challenging unconstrained set-based face recognition problem where each subject face is instantiated by a set of media (images and videos) instead of a single image. Naively aggregating information from all the media within a set would suffer from the large intra-set variance caused by heterogeneous factors (e.g., varying media modalities, poses and illuminations) and fail to learn discriminative face representations. A novel Multi-Prototype Network (MPNet) model is thus proposed to learn multiple prototype face representations adaptively from the media sets. Each learned prototype is representative for the subject face under certain condition in terms of pose, illumination and media modality. Instead of handcrafting the set partition for prototype learning, MPNet introduces a Dense SubGraph (DSG) learning sub-net that implicitly untangles inconsistent media and learns a number of representative prototypes. Qualitative and quantitative experiments clearly demonstrate superiority of the proposed model over state-of-the-arts.
Look Across Elapse: Disentangled Representation Learning and Photorealistic Cross-Age Face Synthesis for Age-Invariant Face Recognition
Oct 04, 2018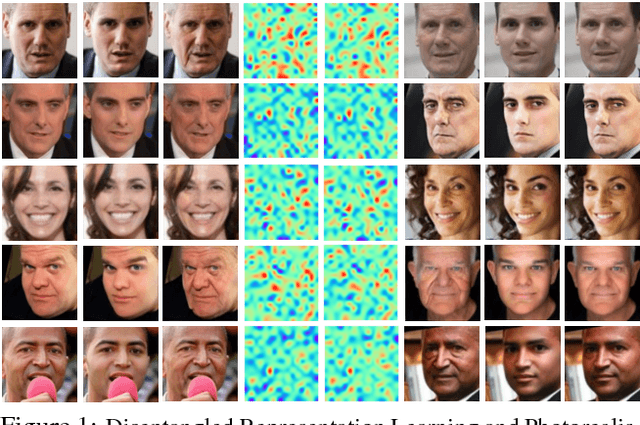
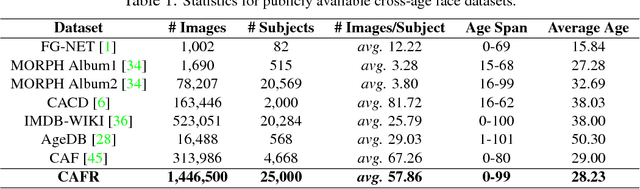
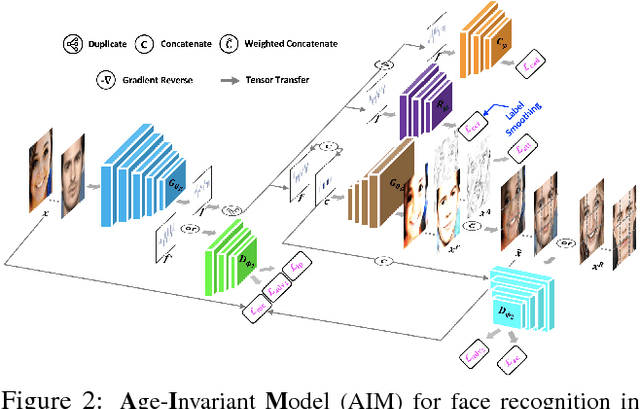
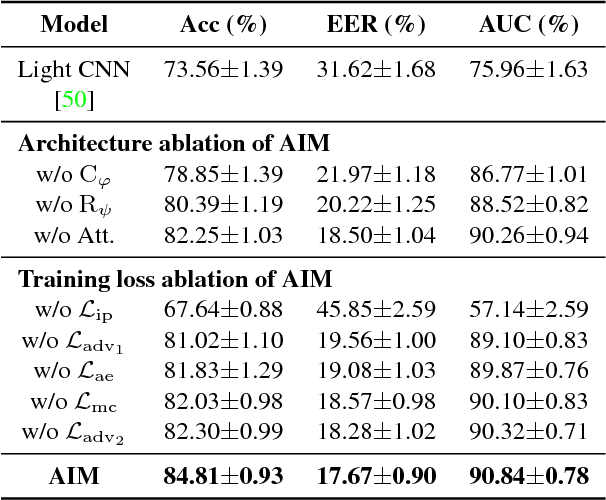
Despite the remarkable progress in face recognition related technologies, reliably recognizing faces across ages still remains a big challenge. The appearance of a human face changes substantially over time, resulting in significant intra-class variations. As opposed to current techniques for age-invariant face recognition, which either directly extract age-invariant features for recognition, or first synthesize a face that matches target age before feature extraction, we argue that it is more desirable to perform both tasks jointly so that they can leverage each other. To this end, we propose a deep Age-Invariant Model (AIM) for face recognition in the wild with three distinct novelties. First, AIM presents a novel unified deep architecture jointly performing cross-age face synthesis and recognition in a mutual boosting way. Second, AIM achieves continuous face rejuvenation/aging with remarkable photorealistic and identity-preserving properties, avoiding the requirement of paired data and the true age of testing samples. Third, we develop effective and novel training strategies for end-to-end learning the whole deep architecture, which generates powerful age-invariant face representations explicitly disentangled from the age variation. Moreover, we propose a new large-scale Cross-Age Face Recognition (CAFR) benchmark dataset to facilitate existing efforts and push the frontiers of age-invariant face recognition research. Extensive experiments on both our CAFR and several other cross-age datasets (MORPH, CACD and FG-NET) demonstrate the superiority of the proposed AIM model over the state-of-the-arts. Benchmarking our model on one of the most popular unconstrained face recognition datasets IJB-C additionally verifies the promising generalizability of AIM in recognizing faces in the wild.
Learning for Disparity Estimation through Feature Constancy
Mar 28, 2018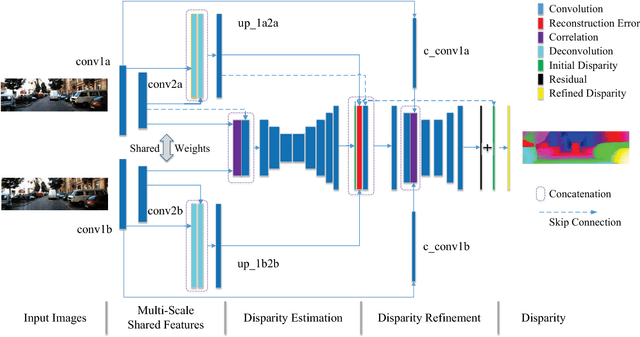
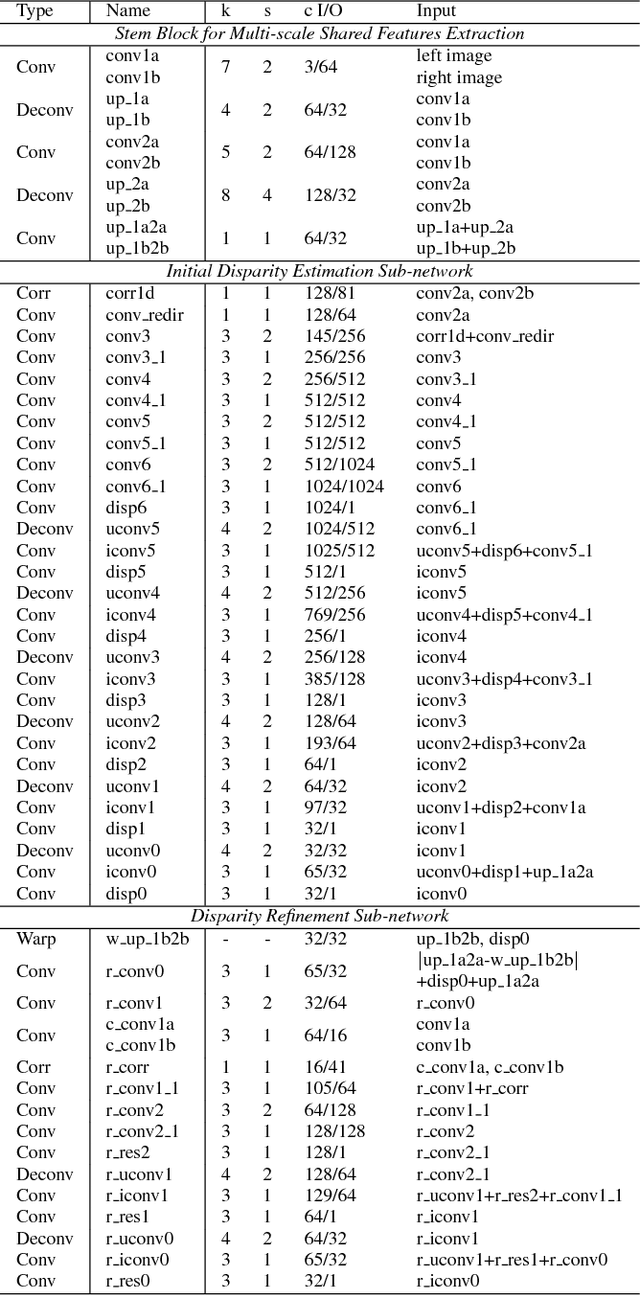

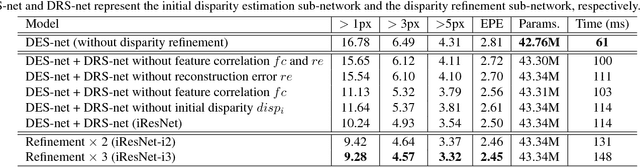
Stereo matching algorithms usually consist of four steps, including matching cost calculation, matching cost aggregation, disparity calculation, and disparity refinement. Existing CNN-based methods only adopt CNN to solve parts of the four steps, or use different networks to deal with different steps, making them difficult to obtain the overall optimal solution. In this paper, we propose a network architecture to incorporate all steps of stereo matching. The network consists of three parts. The first part calculates the multi-scale shared features. The second part performs matching cost calculation, matching cost aggregation and disparity calculation to estimate the initial disparity using shared features. The initial disparity and the shared features are used to calculate the feature constancy that measures correctness of the correspondence between two input images. The initial disparity and the feature constancy are then fed to a sub-network to refine the initial disparity. The proposed method has been evaluated on the Scene Flow and KITTI datasets. It achieves the state-of-the-art performance on the KITTI 2012 and KITTI 2015 benchmarks while maintaining a very fast running time.