 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask Alignment: A simple and effective proxy for model merging in computer vision
Apr 14, 2026Efficiently merging several models fine-tuned for different tasks, but stemming from the same pretrained base model, is of great practical interest. Despite extensive prior work, most evaluations of model merging in computer vision are restricted to image classification using CLIP, where different classification datasets define different tasks. In this work, our goal is to make model merging more practical and show its relevance on challenging scenarios beyond this specific setting. In most vision scenarios, different tasks rely on trainable and usually heterogeneous decoders. Differently from previous studies with frozen decoders, where merged models can be evaluated right away, the non-trivial cost of decoder training renders hyperparameter selection based on downstream performance impractical. To address this, we introduce the task alignment proxy, and show how it can be used to speed up hyperparameter selection by orders of magnitude while retaining performance. Equipped with the task alignment proxy, we extend the applicability of model merging to multi-task vision models beyond CLIP-based classification.
ELViS: Efficient Visual Similarity from Local Descriptors that Generalizes Across Domains
Mar 30, 2026Large-scale instance-level training data is scarce, so models are typically trained on domain-specific datasets. Yet in real-world retrieval, they must handle diverse domains, making generalization to unseen data critical. We introduce ELViS, an image-to-image similarity model that generalizes effectively to unseen domains. Unlike conventional approaches, our model operates in similarity space rather than representation space, promoting cross-domain transfer. It leverages local descriptor correspondences, refines their similarities through an optimal transport step with data-dependent gains that suppress uninformative descriptors, and aggregates strong correspondences via a voting process into an image-level similarity. This design injects strong inductive biases, yielding a simple, efficient, and interpretable model. To assess generalization, we compile a benchmark of eight datasets spanning landmarks, artworks, products, and multi-domain collections, and evaluate ELViS as a re-ranking method. Our experiments show that ELViS outperforms competing methods by a large margin in out-of-domain scenarios and on average, while requiring only a fraction of their computational cost. Code available at: https://github.com/pavelsuma/ELViS/
LPOSS: Label Propagation Over Patches and Pixels for Open-vocabulary Semantic Segmentation
Mar 25, 2025We propose a training-free method for open-vocabulary semantic segmentation using Vision-and-Language Models (VLMs). Our approach enhances the initial per-patch predictions of VLMs through label propagation, which jointly optimizes predictions by incorporating patch-to-patch relationships. Since VLMs are primarily optimized for cross-modal alignment and not for intra-modal similarity, we use a Vision Model (VM) that is observed to better capture these relationships. We address resolution limitations inherent to patch-based encoders by applying label propagation at the pixel level as a refinement step, significantly improving segmentation accuracy near class boundaries. Our method, called LPOSS+, performs inference over the entire image, avoiding window-based processing and thereby capturing contextual interactions across the full image. LPOSS+ achieves state-of-the-art performance among training-free methods, across a diverse set of datasets. Code: https://github.com/vladan-stojnic/LPOSS
DUNE: Distilling a Universal Encoder from Heterogeneous 2D and 3D Teachers
Mar 18, 2025Recent multi-teacher distillation methods have unified the encoders of multiple foundation models into a single encoder, achieving competitive performance on core vision tasks like classification, segmentation, and depth estimation. This led us to ask: Could similar success be achieved when the pool of teachers also includes vision models specialized in diverse tasks across both 2D and 3D perception? In this paper, we define and investigate the problem of heterogeneous teacher distillation, or co-distillation, a challenging multi-teacher distillation scenario where teacher models vary significantly in both (a) their design objectives and (b) the data they were trained on. We explore data-sharing strategies and teacher-specific encoding, and introduce DUNE, a single encoder excelling in 2D vision, 3D understanding, and 3D human perception. Our model achieves performance comparable to that of its larger teachers, sometimes even outperforming them, on their respective tasks. Notably, DUNE surpasses MASt3R in Map-free Visual Relocalization with a much smaller encoder.
UNIC: Universal Classification Models via Multi-teacher Distillation
Aug 09, 2024Pretrained models have become a commodity and offer strong results on a broad range of tasks. In this work, we focus on classification and seek to learn a unique encoder able to take from several complementary pretrained models. We aim at even stronger generalization across a variety of classification tasks. We propose to learn such an encoder via multi-teacher distillation. We first thoroughly analyse standard distillation when driven by multiple strong teachers with complementary strengths. Guided by this analysis, we gradually propose improvements to the basic distillation setup. Among those, we enrich the architecture of the encoder with a ladder of expendable projectors, which increases the impact of intermediate features during distillation, and we introduce teacher dropping, a regularization mechanism that better balances the teachers' influence. Our final distillation strategy leads to student models of the same capacity as any of the teachers, while retaining or improving upon the performance of the best teacher for each task. Project page and code: https://europe.naverlabs.com/unic
Label Propagation for Zero-shot Classification with Vision-Language Models
Apr 05, 2024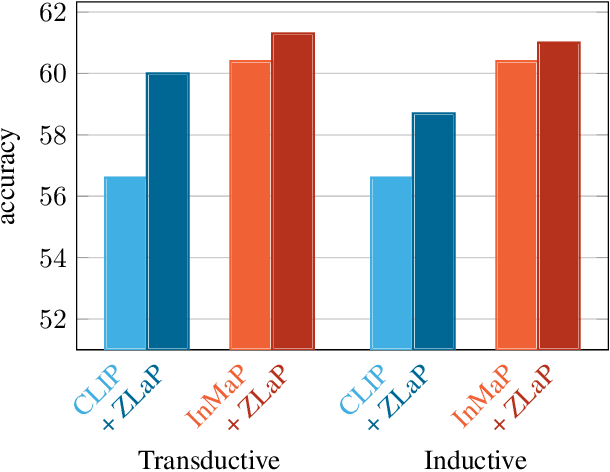

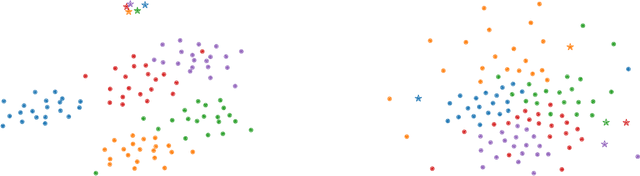
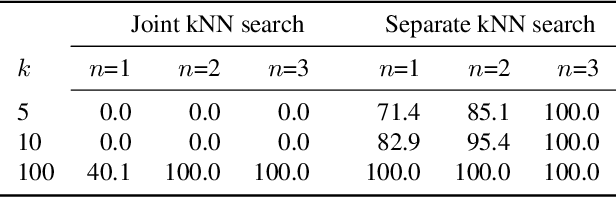
Vision-Language Models (VLMs) have demonstrated impressive performance on zero-shot classification, i.e. classification when provided merely with a list of class names. In this paper, we tackle the case of zero-shot classification in the presence of unlabeled data. We leverage the graph structure of the unlabeled data and introduce ZLaP, a method based on label propagation (LP) that utilizes geodesic distances for classification. We tailor LP to graphs containing both text and image features and further propose an efficient method for performing inductive inference based on a dual solution and a sparsification step. We perform extensive experiments to evaluate the effectiveness of our method on 14 common datasets and show that ZLaP outperforms the latest related works. Code: https://github.com/vladan-stojnic/ZLaP
Weatherproofing Retrieval for Localization with Generative AI and Geometric Consistency
Feb 14, 2024



State-of-the-art visual localization approaches generally rely on a first image retrieval step whose role is crucial. Yet, retrieval often struggles when facing varying conditions, due to e.g. weather or time of day, with dramatic consequences on the visual localization accuracy. In this paper, we improve this retrieval step and tailor it to the final localization task. Among the several changes we advocate for, we propose to synthesize variants of the training set images, obtained from generative text-to-image models, in order to automatically expand the training set towards a number of nameable variations that particularly hurt visual localization. After expanding the training set, we propose a training approach that leverages the specificities and the underlying geometry of this mix of real and synthetic images. We experimentally show that those changes translate into large improvements for the most challenging visual localization datasets. Project page: https://europe.naverlabs.com/ret4loc
Rethinking matching-based few-shot action recognition
Mar 28, 2023Few-shot action recognition, i.e. recognizing new action classes given only a few examples, benefits from incorporating temporal information. Prior work either encodes such information in the representation itself and learns classifiers at test time, or obtains frame-level features and performs pairwise temporal matching. We first evaluate a number of matching-based approaches using features from spatio-temporal backbones, a comparison missing from the literature, and show that the gap in performance between simple baselines and more complicated methods is significantly reduced. Inspired by this, we propose Chamfer++, a non-temporal matching function that achieves state-of-the-art results in few-shot action recognition. We show that, when starting from temporal features, our parameter-free and interpretable approach can outperform all other matching-based and classifier methods for one-shot action recognition on three common datasets without using temporal information in the matching stage. Project page: https://jbertrand89.github.io/matching-based-fsar
Fake it till you make it: Learning from a synthetic ImageNet clone
Dec 16, 2022



Recent large-scale image generation models such as Stable Diffusion have exhibited an impressive ability to generate fairly realistic images starting from a very simple text prompt. Could such models render real images obsolete for training image prediction models? In this paper, we answer part of this provocative question by questioning the need for real images when training models for ImageNet classification. More precisely, provided only with the class names that have been used to build the dataset, we explore the ability of Stable Diffusion to generate synthetic clones of ImageNet and measure how useful they are for training classification models from scratch. We show that with minimal and class-agnostic prompt engineering those ImageNet clones we denote as ImageNet-SD are able to close a large part of the gap between models produced by synthetic images and models trained with real images for the several standard classification benchmarks that we consider in this study. More importantly, we show that models trained on synthetic images exhibit strong generalization properties and perform on par with models trained on real data.
Granularity-aware Adaptation for Image Retrieval over Multiple Tasks
Oct 05, 2022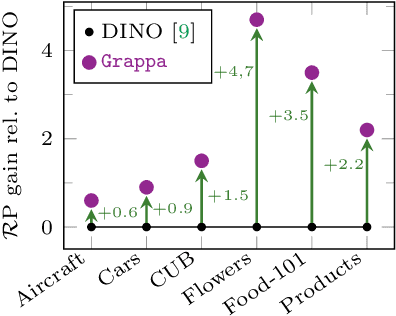
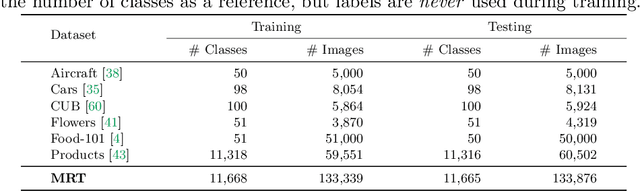
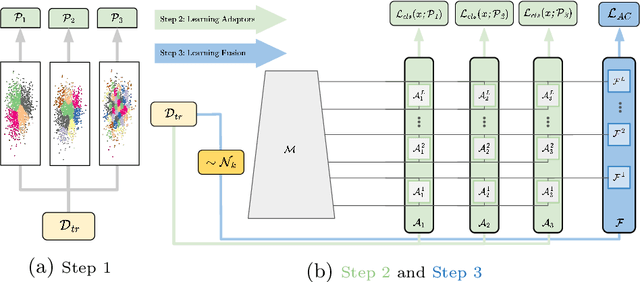
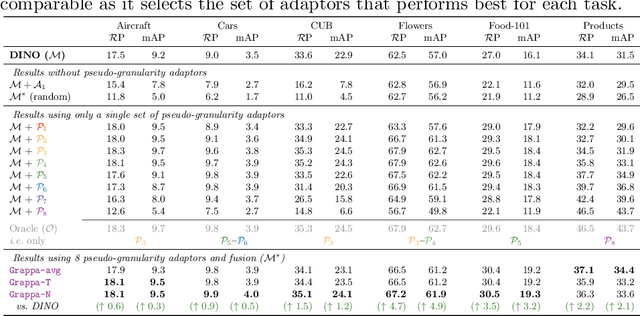
Strong image search models can be learned for a specific domain, ie. set of labels, provided that some labeled images of that domain are available. A practical visual search model, however, should be versatile enough to solve multiple retrieval tasks simultaneously, even if those cover very different specialized domains. Additionally, it should be able to benefit from even unlabeled images from these various retrieval tasks. This is the more practical scenario that we consider in this paper. We address it with the proposed Grappa, an approach that starts from a strong pretrained model, and adapts it to tackle multiple retrieval tasks concurrently, using only unlabeled images from the different task domains. We extend the pretrained model with multiple independently trained sets of adaptors that use pseudo-label sets of different sizes, effectively mimicking different pseudo-granularities. We reconcile all adaptor sets into a single unified model suited for all retrieval tasks by learning fusion layers that we guide by propagating pseudo-granularity attentions across neighbors in the feature space. Results on a benchmark composed of six heterogeneous retrieval tasks show that the unsupervised Grappa model improves the zero-shot performance of a state-of-the-art self-supervised learning model, and in some places reaches or improves over a task label-aware oracle that selects the most fitting pseudo-granularity per task.