 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnbiased Regression Loss for DETRs
Oct 30, 2024



In this paper, we introduce a novel unbiased regression loss for DETR-based detectors. The conventional $L_{1}$ regression loss tends to bias towards larger boxes, as they disproportionately contribute more towards the overall loss compared to smaller boxes. Consequently, the detection performance for small objects suffers. To alleviate this bias, the proposed new unbiased loss, termed Sized $L_{1}$ loss, normalizes the size of all boxes based on their individual width and height. Our experiments demonstrate consistent improvements in both fully-supervised and semi-supervised settings using the MS-COCO benchmark dataset.
EnvBridge: Bridging Diverse Environments with Cross-Environment Knowledge Transfer for Embodied AI
Oct 22, 2024



In recent years, Large Language Models (LLMs) have demonstrated high reasoning capabilities, drawing attention for their applications as agents in various decision-making processes. One notably promising application of LLM agents is robotic manipulation. Recent research has shown that LLMs can generate text planning or control code for robots, providing substantial flexibility and interaction capabilities. However, these methods still face challenges in terms of flexibility and applicability across different environments, limiting their ability to adapt autonomously. Current approaches typically fall into two categories: those relying on environment-specific policy training, which restricts their transferability, and those generating code actions based on fixed prompts, which leads to diminished performance when confronted with new environments. These limitations significantly constrain the generalizability of agents in robotic manipulation. To address these limitations, we propose a novel method called EnvBridge. This approach involves the retention and transfer of successful robot control codes from source environments to target environments. EnvBridge enhances the agent's adaptability and performance across diverse settings by leveraging insights from multiple environments. Notably, our approach alleviates environmental constraints, offering a more flexible and generalizable solution for robotic manipulation tasks. We validated the effectiveness of our method using robotic manipulation benchmarks: RLBench, MetaWorld, and CALVIN. Our experiments demonstrate that LLM agents can successfully leverage diverse knowledge sources to solve complex tasks. Consequently, our approach significantly enhances the adaptability and robustness of robotic manipulation agents in planning across diverse environments.
Decoding BACnet Packets: A Large Language Model Approach for Packet Interpretation
Jul 22, 2024



The Industrial Control System (ICS) environment encompasses a wide range of intricate communication protocols, posing substantial challenges for Security Operations Center (SOC) analysts tasked with monitoring, interpreting, and addressing network activities and security incidents. Conventional monitoring tools and techniques often struggle to provide a clear understanding of the nature and intent of ICS-specific communications. To enhance comprehension, we propose a software solution powered by a Large Language Model (LLM). This solution currently focused on BACnet protocol, processes a packet file data and extracts context by using a mapping database, and contemporary context retrieval methods for Retrieval Augmented Generation (RAG). The processed packet information, combined with the extracted context, serves as input to the LLM, which generates a concise packet file summary for the user. The software delivers a clear, coherent, and easily understandable summary of network activities, enabling SOC analysts to better assess the current state of the control system.
RAP: Retrieval-Augmented Planning with Contextual Memory for Multimodal LLM Agents
Feb 06, 2024



Owing to recent advancements, Large Language Models (LLMs) can now be deployed as agents for increasingly complex decision-making applications in areas including robotics, gaming, and API integration. However, reflecting past experiences in current decision-making processes, an innate human behavior, continues to pose significant challenges. Addressing this, we propose Retrieval-Augmented Planning (RAP) framework, designed to dynamically leverage past experiences corresponding to the current situation and context, thereby enhancing agents' planning capabilities. RAP distinguishes itself by being versatile: it excels in both text-only and multimodal environments, making it suitable for a wide range of tasks. Empirical evaluations demonstrate RAP's effectiveness, where it achieves SOTA performance in textual scenarios and notably enhances multimodal LLM agents' performance for embodied tasks. These results highlight RAP's potential in advancing the functionality and applicability of LLM agents in complex, real-world applications.
Invariant Feature Regularization for Fair Face Recognition
Oct 23, 2023



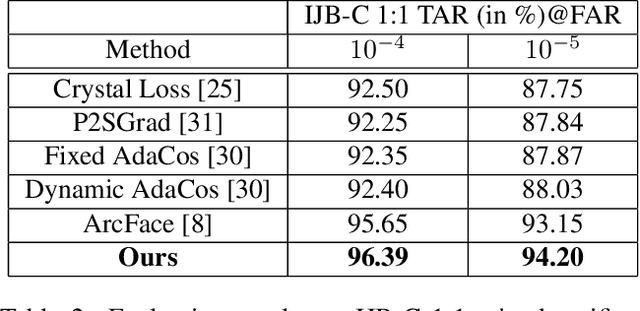
Fair face recognition is all about learning invariant feature that generalizes to unseen faces in any demographic group. Unfortunately, face datasets inevitably capture the imbalanced demographic attributes that are ubiquitous in real-world observations, and the model learns biased feature that generalizes poorly in the minority group. We point out that the bias arises due to the confounding demographic attributes, which mislead the model to capture the spurious demographic-specific feature. The confounding effect can only be removed by causal intervention, which requires the confounder annotations. However, such annotations can be prohibitively expensive due to the diversity of the demographic attributes. To tackle this, we propose to generate diverse data partitions iteratively in an unsupervised fashion. Each data partition acts as a self-annotated confounder, enabling our Invariant Feature Regularization (INV-REG) to deconfound. INV-REG is orthogonal to existing methods, and combining INV-REG with two strong baselines (Arcface and CIFP) leads to new state-of-the-art that improves face recognition on a variety of demographic groups. Code is available at https://github.com/PanasonicConnect/InvReg.
Equivariance and Invariance Inductive Bias for Learning from Insufficient Data
Jul 25, 2022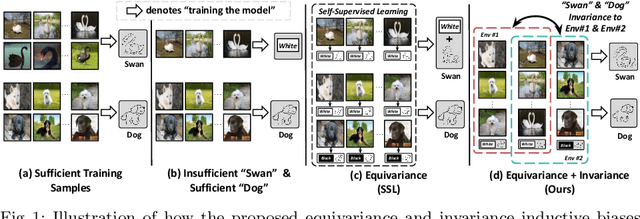
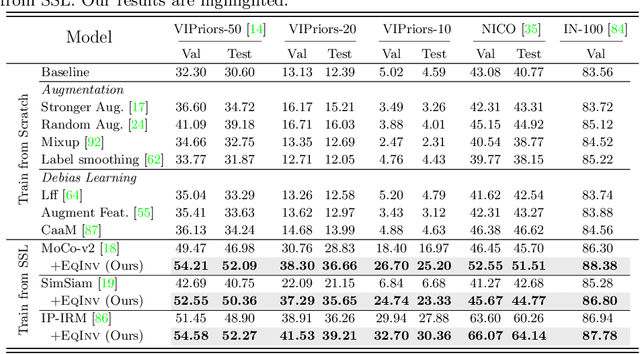
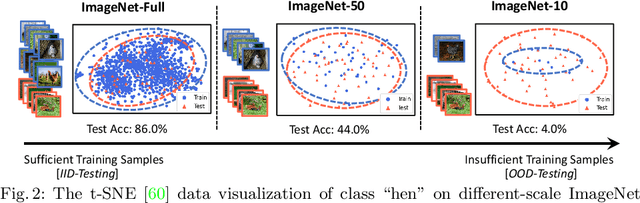

We are interested in learning robust models from insufficient data, without the need for any externally pre-trained checkpoints. First, compared to sufficient data, we show why insufficient data renders the model more easily biased to the limited training environments that are usually different from testing. For example, if all the training swan samples are "white", the model may wrongly use the "white" environment to represent the intrinsic class swan. Then, we justify that equivariance inductive bias can retain the class feature while invariance inductive bias can remove the environmental feature, leaving the class feature that generalizes to any environmental changes in testing. To impose them on learning, for equivariance, we demonstrate that any off-the-shelf contrastive-based self-supervised feature learning method can be deployed; for invariance, we propose a class-wise invariant risk minimization (IRM) that efficiently tackles the challenge of missing environmental annotation in conventional IRM. State-of-the-art experimental results on real-world benchmarks (VIPriors, ImageNet100 and NICO) validate the great potential of equivariance and invariance in data-efficient learning. The code is available at https://github.com/Wangt-CN/EqInv
Deep Face Recognition Model Compression via Knowledge Transfer and Distillation
Jun 03, 2019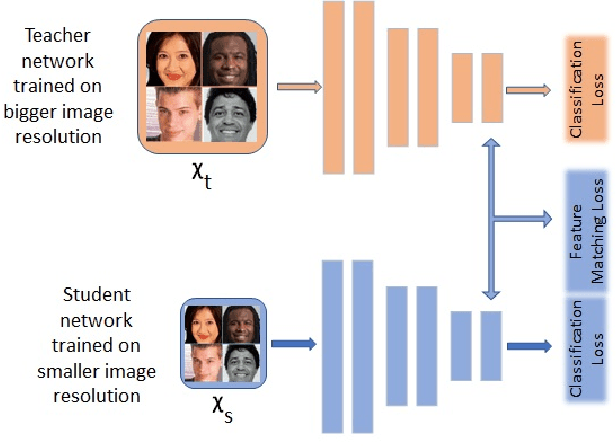
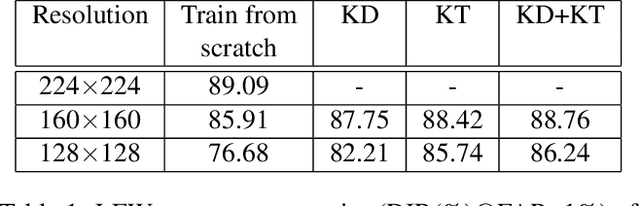
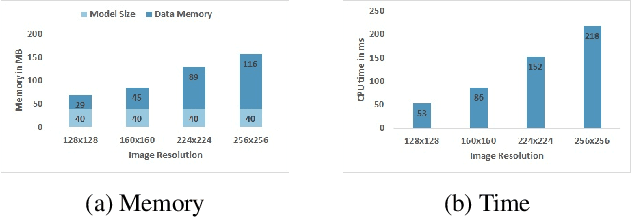
Fully convolutional networks (FCNs) have become de facto tool to achieve very high-level performance for many vision and non-vision tasks in general and face recognition in particular. Such high-level accuracies are normally obtained by very deep networks or their ensemble. However, deploying such high performing models to resource constraint devices or real-time applications is challenging. In this paper, we present a novel model compression approach based on student-teacher paradigm for face recognition applications. The proposed approach consists of training teacher FCN at bigger image resolution while student FCNs are trained at lower image resolutions than that of teacher FCN. We explored three different approaches to train student FCNs: knowledge transfer (KT), knowledge distillation (KD) and their combination. Experimental evaluation on LFW and IJB-C datasets demonstrate comparable improvements in accuracies with these approaches. Training low-resolution student FCNs from higher resolution teacher offer fourfold advantage of accelerated training, accelerated inference, reduced memory requirements and improved accuracies. We evaluated all models on IJB-C dataset and achieved state-of-the-art results on this benchmark. The teacher network and some student networks even achieved Top-1 performance on IJB-C dataset. The proposed approach is simple and hardware friendly, thus enables the deployment of high performing face recognition deep models to resource constraint devices.
Anomaly Detection with Adversarial Dual Autoencoders
Feb 19, 2019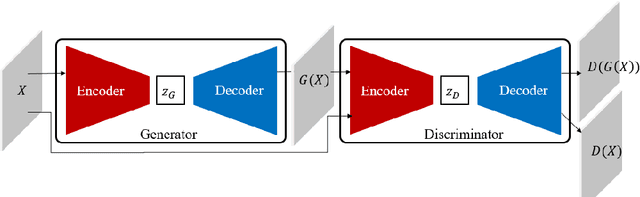
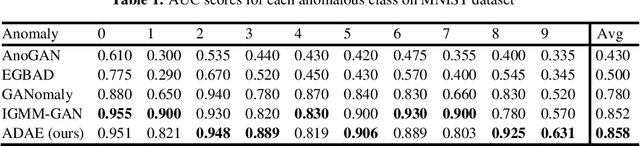
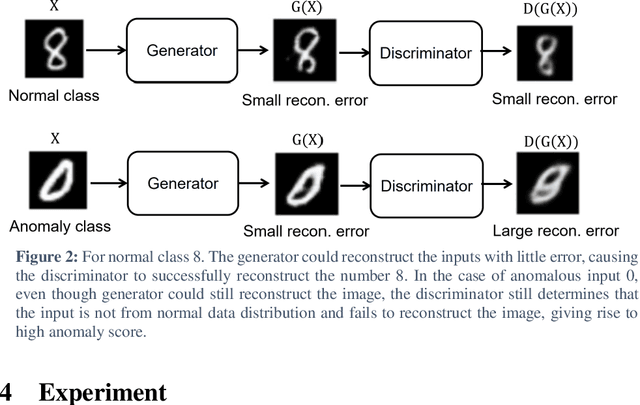

Semi-supervised and unsupervised Generative Adversarial Networks (GAN)-based methods have been gaining popularity in anomaly detection task recently. However, GAN training is somewhat challenging and unstable. Inspired from previous work in GAN-based image generation, we introduce a GAN-based anomaly detection framework - Adversarial Dual Autoencoders (ADAE) - consists of two autoencoders as generator and discriminator to increase training stability. We also employ discriminator reconstruction error as anomaly score for better detection performance. Experiments across different datasets of varying complexity show strong evidence of a robust model that can be used in different scenarios, one of which is brain tumor detection.
Look Across Elapse: Disentangled Representation Learning and Photorealistic Cross-Age Face Synthesis for Age-Invariant Face Recognition
Oct 04, 2018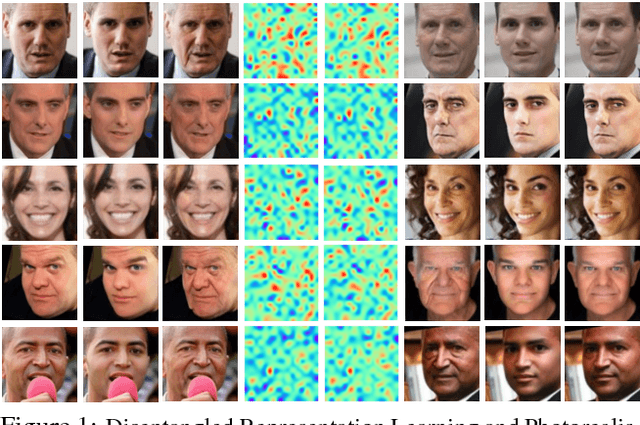
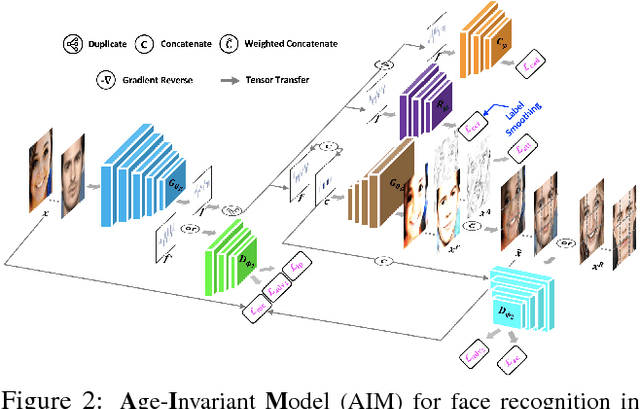
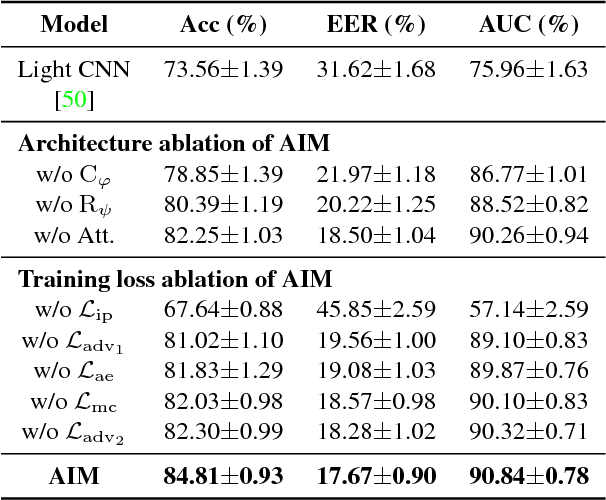
Despite the remarkable progress in face recognition related technologies, reliably recognizing faces across ages still remains a big challenge. The appearance of a human face changes substantially over time, resulting in significant intra-class variations. As opposed to current techniques for age-invariant face recognition, which either directly extract age-invariant features for recognition, or first synthesize a face that matches target age before feature extraction, we argue that it is more desirable to perform both tasks jointly so that they can leverage each other. To this end, we propose a deep Age-Invariant Model (AIM) for face recognition in the wild with three distinct novelties. First, AIM presents a novel unified deep architecture jointly performing cross-age face synthesis and recognition in a mutual boosting way. Second, AIM achieves continuous face rejuvenation/aging with remarkable photorealistic and identity-preserving properties, avoiding the requirement of paired data and the true age of testing samples. Third, we develop effective and novel training strategies for end-to-end learning the whole deep architecture, which generates powerful age-invariant face representations explicitly disentangled from the age variation. Moreover, we propose a new large-scale Cross-Age Face Recognition (CAFR) benchmark dataset to facilitate existing efforts and push the frontiers of age-invariant face recognition research. Extensive experiments on both our CAFR and several other cross-age datasets (MORPH, CACD and FG-NET) demonstrate the superiority of the proposed AIM model over the state-of-the-arts. Benchmarking our model on one of the most popular unconstrained face recognition datasets IJB-C additionally verifies the promising generalizability of AIM in recognizing faces in the wild.
Person re-identification with fusion of hand-crafted and deep pose-based body region features
Mar 27, 2018

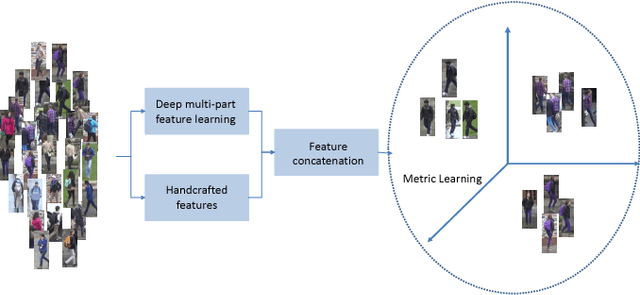
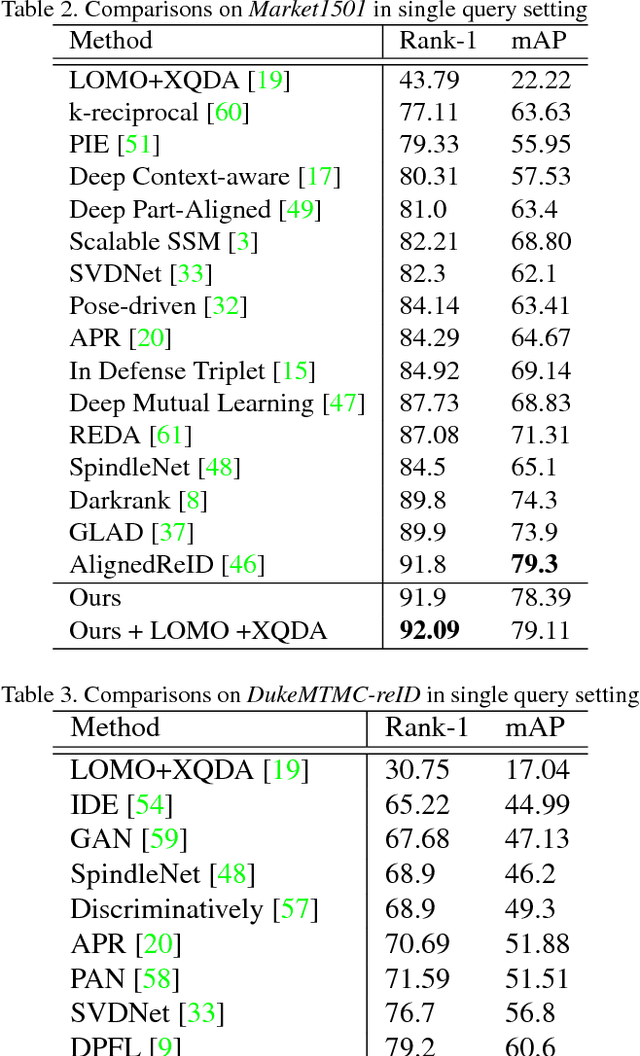
Person re-identification (re-ID) aims to accurately re- trieve a person from a large-scale database of images cap- tured across multiple cameras. Existing works learn deep representations using a large training subset of unique per- sons. However, identifying unseen persons is critical for a good re-ID algorithm. Moreover, the misalignment be- tween person crops to detection errors or pose variations leads to poor feature matching. In this work, we present a fusion of handcrafted features and deep feature representa- tion learned using multiple body parts to complement the global body features that achieves high performance on un- seen test images. Pose information is used to detect body regions that are passed through Convolutional Neural Net- works (CNN) to guide feature learning. Finally, a metric learning step enables robust distance matching on a dis- criminative subspace. Experimental results on 4 popular re-ID benchmark datasets namely VIPer, DukeMTMC-reID, Market-1501 and CUHK03 show that the proposed method achieves state-of-the-art performance in image-based per- son re-identification.