 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffuSeq: Sequence to Sequence Text Generation with Diffusion Models
Oct 17, 2022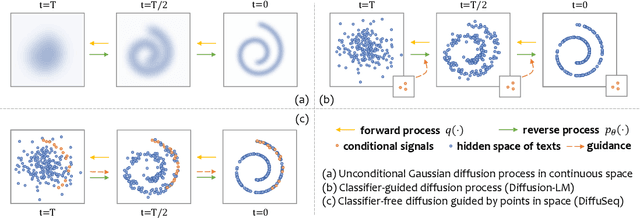
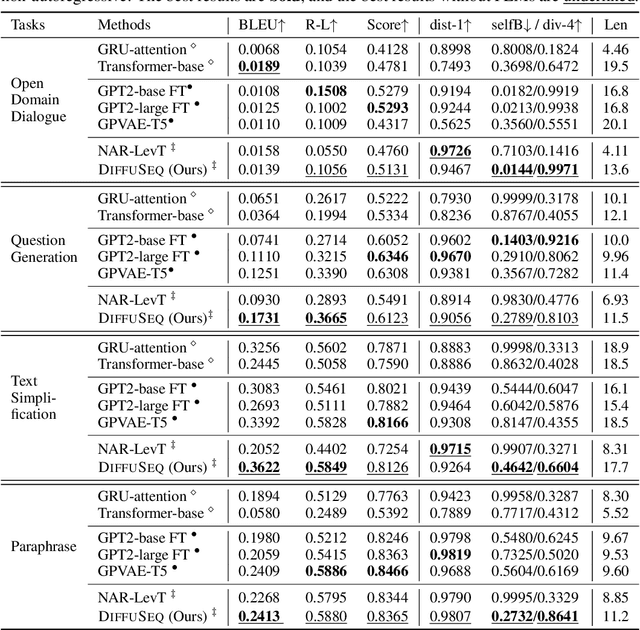
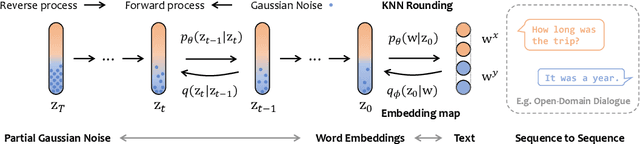

Recently, diffusion models have emerged as a new paradigm for generative models. Despite the success in domains using continuous signals such as vision and audio, adapting diffusion models to natural language is difficult due to the discrete nature of text. We tackle this challenge by proposing DiffuSeq: a diffusion model designed for sequence-to-sequence (Seq2Seq) text generation tasks. Upon extensive evaluation over a wide range of Seq2Seq tasks, we find DiffuSeq achieving comparable or even better performance than six established baselines, including a state-of-the-art model that is based on pre-trained language models. Apart from quality, an intriguing property of DiffuSeq is its high diversity during generation, which is desired in many Seq2Seq tasks. We further include a theoretical analysis revealing the connection between DiffuSeq and autoregressive/non-autoregressive models. Bringing together theoretical analysis and empirical evidence, we demonstrate the great potential of diffusion models in complex conditional language generation tasks.
PARAGEN : A Parallel Generation Toolkit
Oct 07, 2022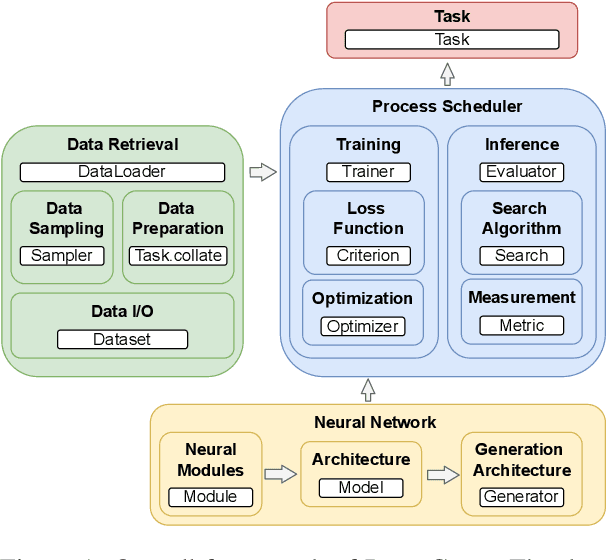

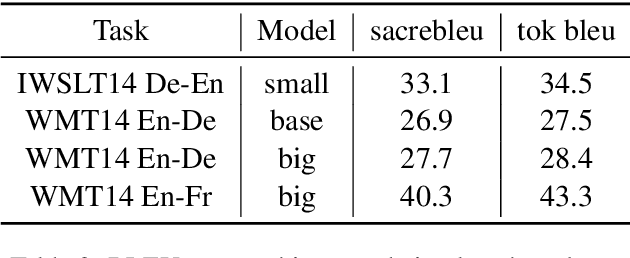
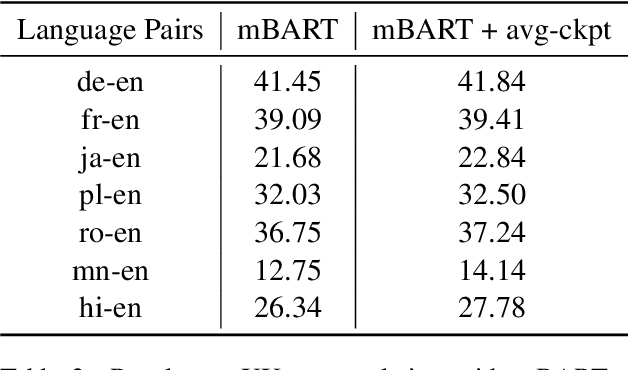
PARAGEN is a PyTorch-based NLP toolkit for further development on parallel generation. PARAGEN provides thirteen types of customizable plugins, helping users to experiment quickly with novel ideas across model architectures, optimization, and learning strategies. We implement various features, such as unlimited data loading and automatic model selection, to enhance its industrial usage. ParaGen is now deployed to support various research and industry applications at ByteDance. PARAGEN is available at https://github.com/bytedance/ParaGen.
CoNT: Contrastive Neural Text Generation
May 29, 2022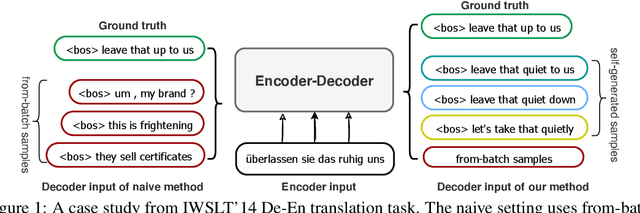
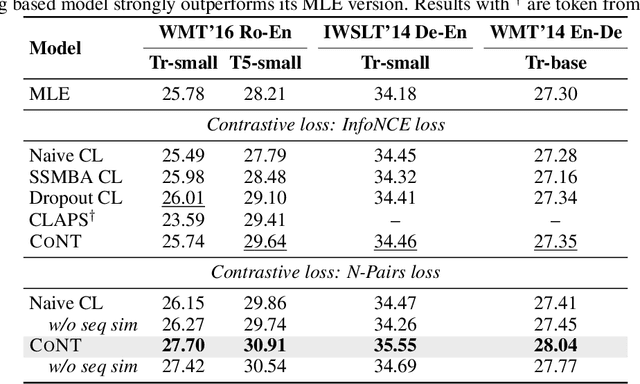
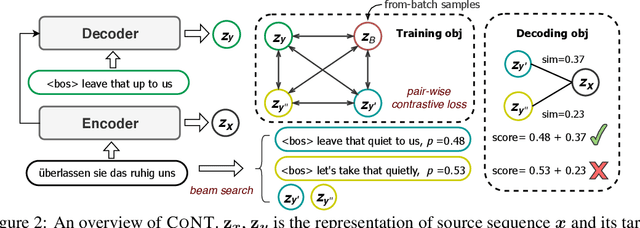
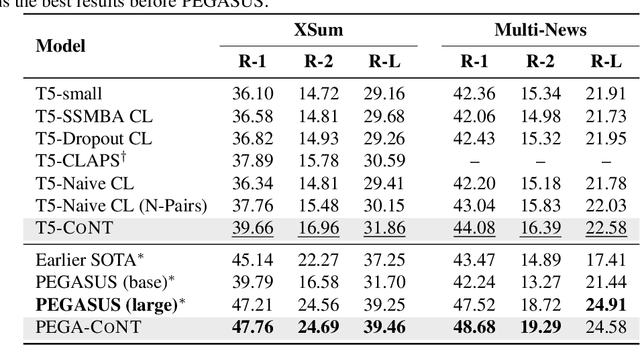
Recently, contrastive learning attracts increasing interests in neural text generation as a new solution to alleviate the exposure bias problem. It introduces a sequence-level training signal which is crucial to generation tasks that always rely on auto-regressive decoding. However, previous methods using contrastive learning in neural text generation usually lead to inferior performance. In this paper, we analyse the underlying reasons and propose a new Contrastive Neural Text generation framework, CoNT. CoNT addresses bottlenecks that prevent contrastive learning from being widely adopted in generation tasks from three aspects -- the construction of contrastive examples, the choice of the contrastive loss, and the strategy in decoding. We validate CoNT on five generation tasks with ten benchmarks, including machine translation, summarization, code comment generation, data-to-text generation and commonsense generation. Experimental results show that CoNT clearly outperforms the conventional training framework on all the ten benchmarks with a convincing margin. Especially, CoNT surpasses previous the most competitive contrastive learning method for text generation, by 1.50 BLEU on machine translation and 1.77 ROUGE-1 on summarization, respectively. It achieves new state-of-the-art on summarization, code comment generation (without external data) and data-to-text generation.
ZeroGen: Efficient Zero-shot Learning via Dataset Generation
Feb 16, 2022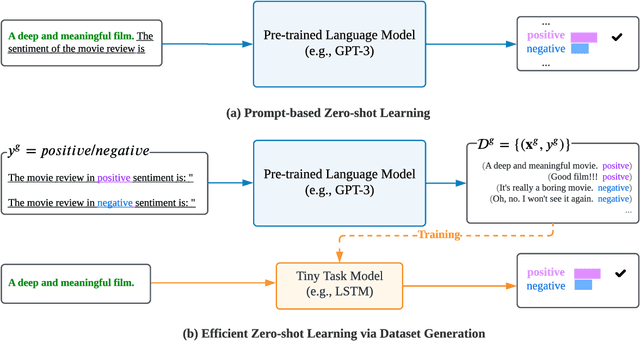
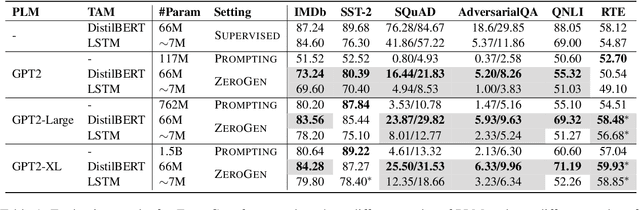
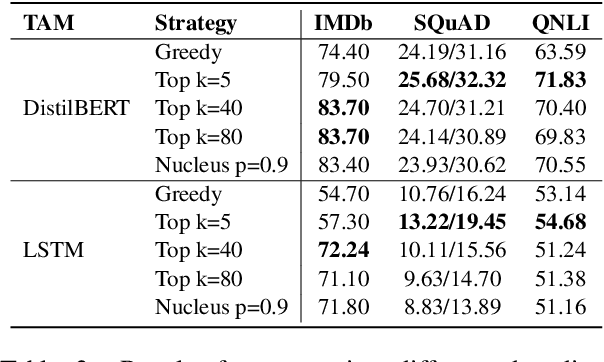
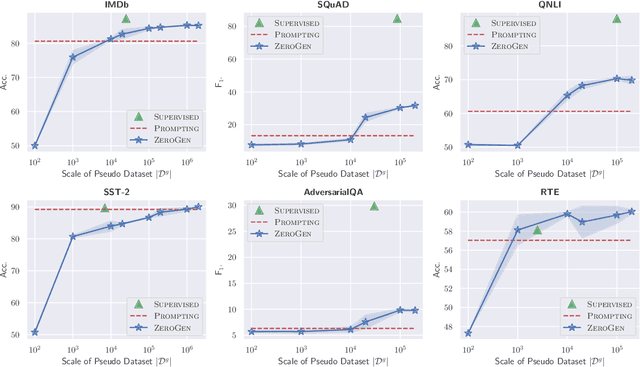
There is a growing interest in dataset generation recently due to the superior generative capacity of large pre-trained language models (PLMs). In this paper, we study a flexible and efficient zero-short learning method, ZeroGen. Given a zero-shot task, we first generate a dataset from scratch using PLMs in an unsupervised manner. Then, we train a tiny task model (e.g., LSTM) under the supervision of the synthesized dataset. This approach allows highly efficient inference as the final task model only has orders of magnitude fewer parameters comparing to PLMs (e.g., GPT2-XL). Apart from being annotation-free and efficient, we argue that ZeroGen can also provide useful insights from the perspective of data-free model-agnostic knowledge distillation, and unreferenced text generation evaluation. Experiments and analysis on different NLP tasks, namely, text classification, question answering, and natural language inference), show the effectiveness of ZeroGen.
Learning Logic Rules for Document-level Relation Extraction
Nov 09, 2021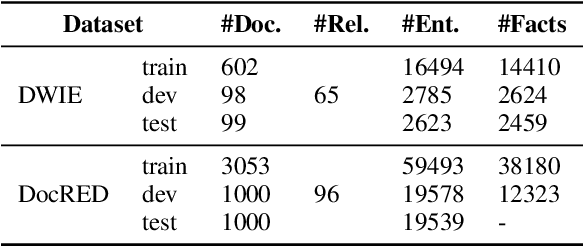

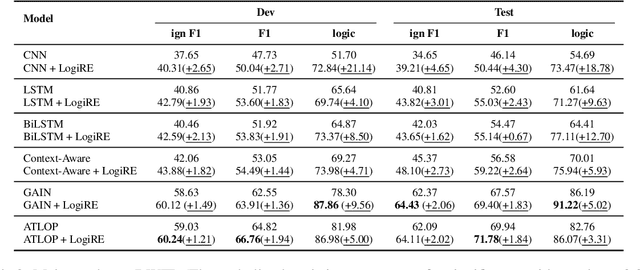

Document-level relation extraction aims to identify relations between entities in a whole document. Prior efforts to capture long-range dependencies have relied heavily on implicitly powerful representations learned through (graph) neural networks, which makes the model less transparent. To tackle this challenge, in this paper, we propose LogiRE, a novel probabilistic model for document-level relation extraction by learning logic rules. LogiRE treats logic rules as latent variables and consists of two modules: a rule generator and a relation extractor. The rule generator is to generate logic rules potentially contributing to final predictions, and the relation extractor outputs final predictions based on the generated logic rules. Those two modules can be efficiently optimized with the expectation-maximization (EM) algorithm. By introducing logic rules into neural networks, LogiRE can explicitly capture long-range dependencies as well as enjoy better interpretation. Empirical results show that LogiRE significantly outperforms several strong baselines in terms of relation performance (1.8 F1 score) and logical consistency (over 3.3 logic score). Our code is available at https://github.com/rudongyu/LogiRE.
The Volctrans GLAT System: Non-autoregressive Translation Meets WMT21
Sep 24, 2021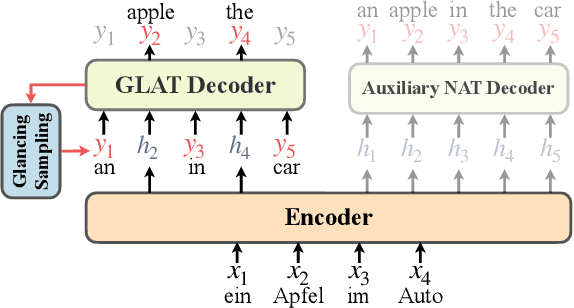
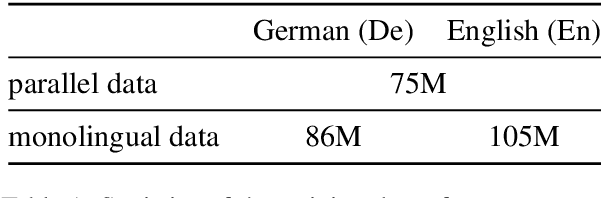
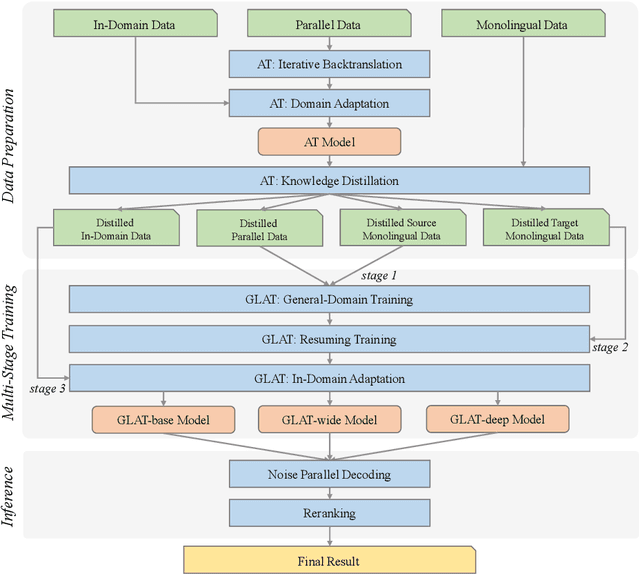
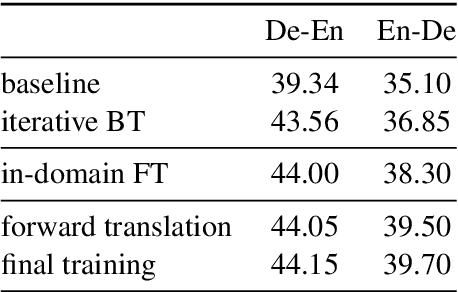
This paper describes the Volctrans' submission to the WMT21 news translation shared task for German->English translation. We build a parallel (i.e., non-autoregressive) translation system using the Glancing Transformer, which enables fast and accurate parallel decoding in contrast to the currently prevailing autoregressive models. To the best of our knowledge, this is the first parallel translation system that can be scaled to such a practical scenario like WMT competition. More importantly, our parallel translation system achieves the best BLEU score (35.0) on German->English translation task, outperforming all strong autoregressive counterparts.
Serial or Parallel? Plug-able Adapter for multilingual machine translation
Apr 16, 2021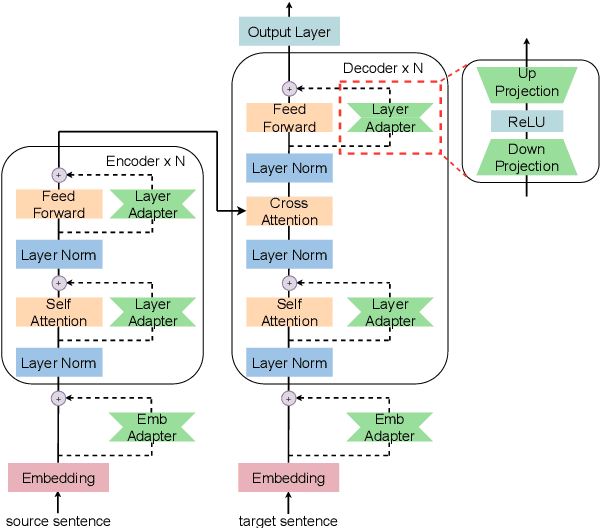

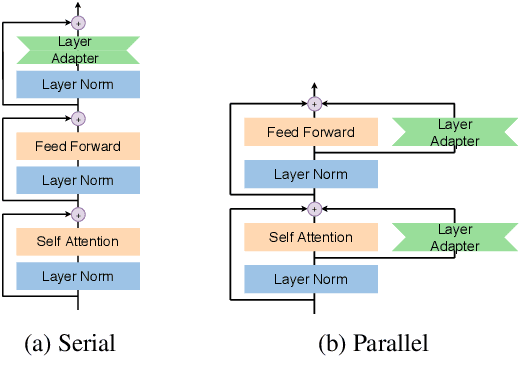
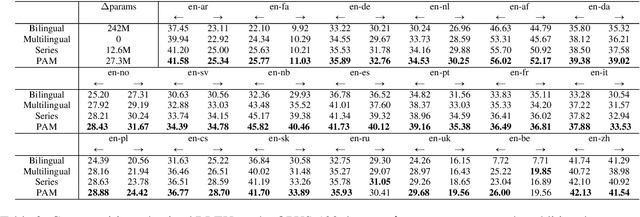
Developing a unified multilingual translation model is a key topic in machine translation research. However, existing approaches suffer from performance degradation: multilingual models yield inferior performance compared to the ones trained separately on rich bilingual data. We attribute the performance degradation to two issues: multilingual embedding conflation and multilingual fusion effects. To address the two issues, we propose PAM, a Transformer model augmented with defusion adaptation for multilingual machine translation. Specifically, PAM consists of embedding and layer adapters to shift the word and intermediate representations towards language-specific ones. Extensive experiment results on IWSLT, OPUS-100, and WMT benchmarks show that \method outperforms several strong competitors, including series adapter and multilingual knowledge distillation.
Alleviate Exposure Bias in Sequence Prediction \\ with Recurrent Neural Networks
Mar 22, 2021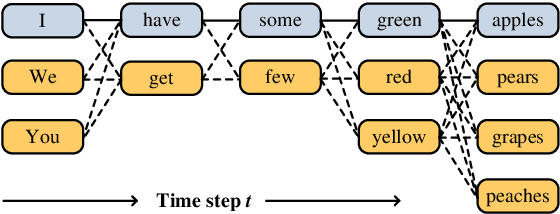
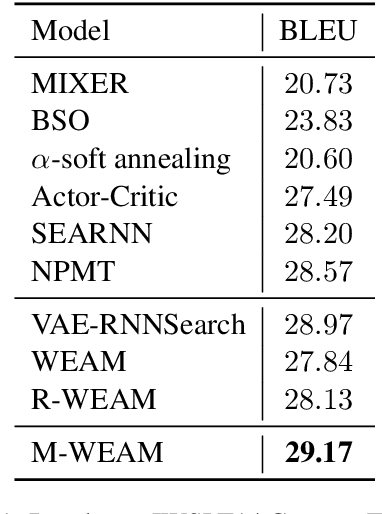
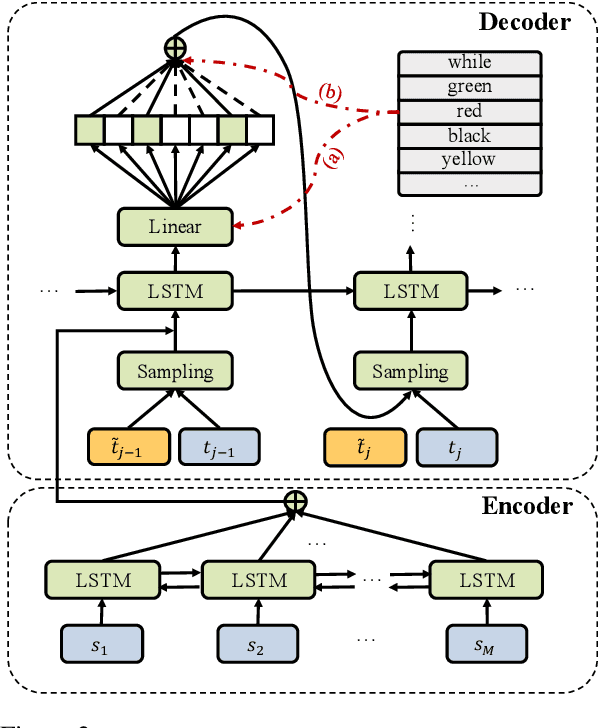
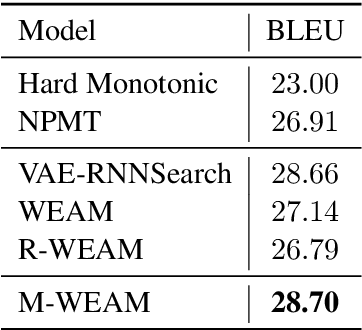
A popular strategy to train recurrent neural networks (RNNs), known as ``teacher forcing'' takes the ground truth as input at each time step and makes the later predictions partly conditioned on those inputs. Such training strategy impairs their ability to learn rich distributions over entire sequences because the chosen inputs hinders the gradients back-propagating to all previous states in an end-to-end manner. We propose a fully differentiable training algorithm for RNNs to better capture long-term dependencies by recovering the probability of the whole sequence. The key idea is that at each time step, the network takes as input a ``bundle'' of similar words predicted at the previous step instead of a single ground truth. The representations of these similar words forms a convex hull, which can be taken as a kind of regularization to the input. Smoothing the inputs by this way makes the whole process trainable and differentiable. This design makes it possible for the model to explore more feasible combinations (possibly unseen sequences), and can be interpreted as a computationally efficient approximation to the beam search. Experiments on multiple sequence generation tasks yield performance improvements, especially in sequence-level metrics, such as BLUE or ROUGE-2.
Pre-training Multilingual Neural Machine Translation by Leveraging Alignment Information
Oct 07, 2020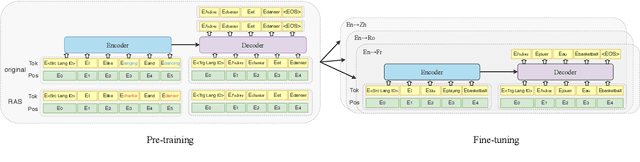
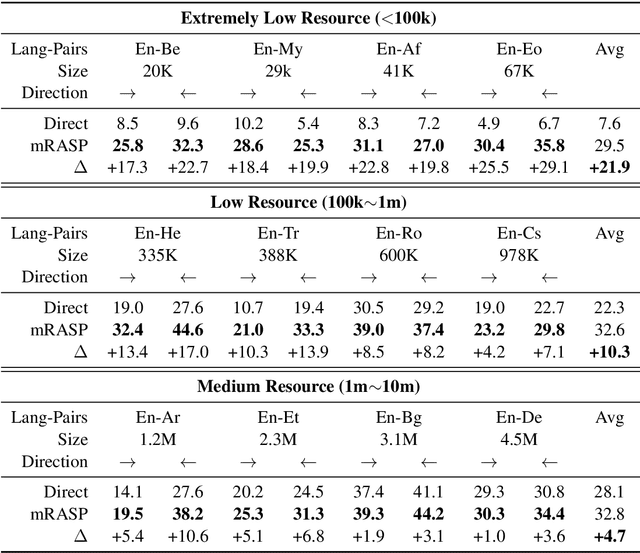
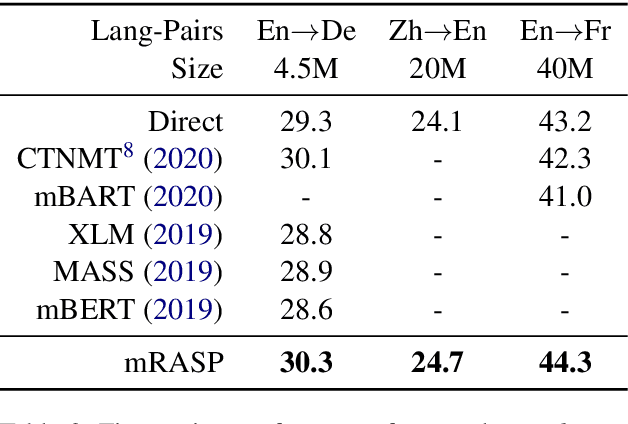
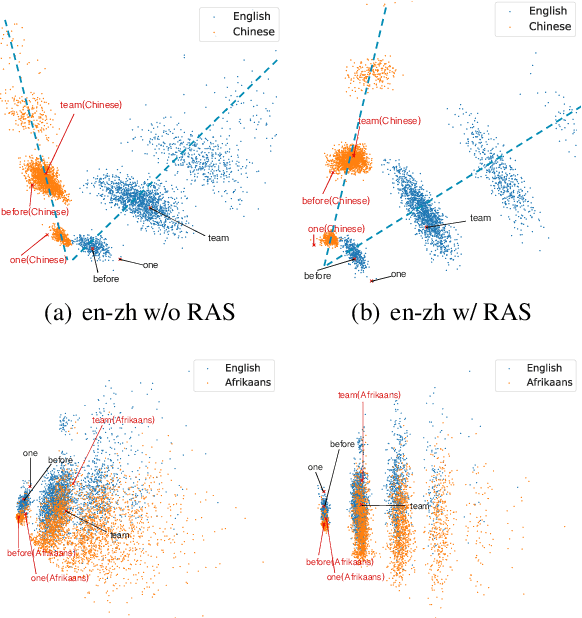
We investigate the following question for machine translation (MT): can we develop a single universal MT model to serve as the common seed and obtain derivative and improved models on arbitrary language pairs? We propose mRASP, an approach to pre-train a universal multilingual neural machine translation model. Our key idea in mRASP is its novel technique of random aligned substitution, which brings words and phrases with similar meanings across multiple languages closer in the representation space. We pre-train a mRASP model on 32 language pairs jointly with only public datasets. The model is then fine-tuned on downstream language pairs to obtain specialized MT models. We carry out extensive experiments on 42 translation directions across a diverse settings, including low, medium, rich resource, and as well as transferring to exotic language pairs. Experimental results demonstrate that mRASP achieves significant performance improvement compared to directly training on those target pairs. It is the first time to verify that multiple low-resource language pairs can be utilized to improve rich resource MT. Surprisingly, mRASP is even able to improve the translation quality on exotic languages that never occur in the pre-training corpus. Code, data, and pre-trained models are available at https://github.com/linzehui/mRASP.
Non-autoregressive Transformer by Position Learning
Nov 25, 2019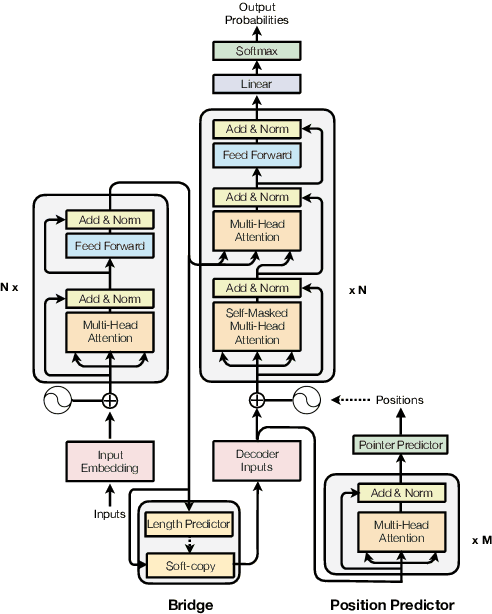
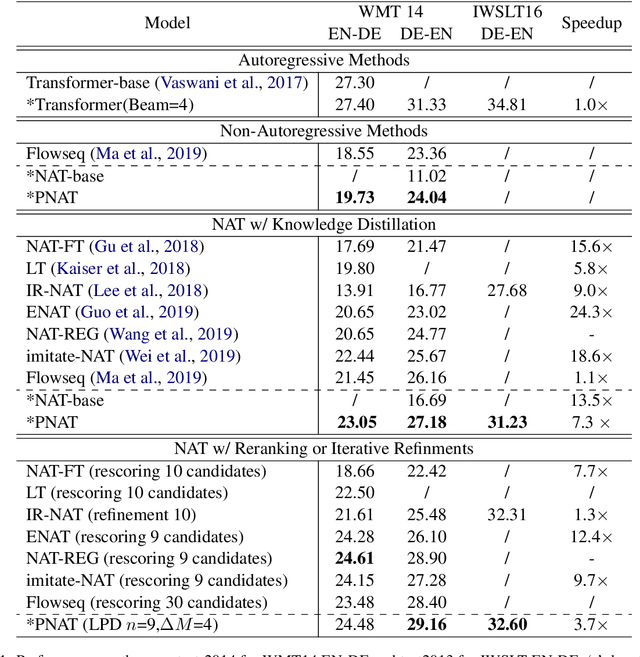
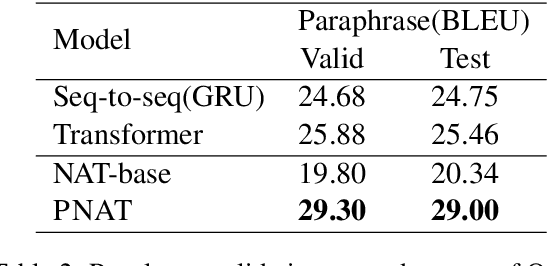
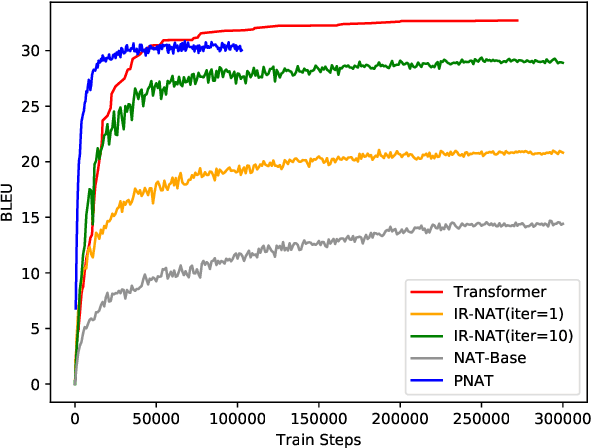
Non-autoregressive models are promising on various text generation tasks. Previous work hardly considers to explicitly model the positions of generated words. However, position modeling is an essential problem in non-autoregressive text generation. In this study, we propose PNAT, which incorporates positions as a latent variable into the text generative process. Experimental results show that PNAT achieves top results on machine translation and paraphrase generation tasks, outperforming several strong baselines.