 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEScore2: Retrieval Augmented Pretraining for Text Generation Evaluation
Dec 19, 2022Is it possible to leverage large scale raw and raw parallel corpora to build a general learned metric? Existing learned metrics have gaps to human judgements, are model-dependent or are limited to the domains or tasks where human ratings are available. In this paper, we propose SEScore2, a model-based metric pretrained over million-scale synthetic dataset constructed by our novel retrieval augmented data synthesis pipeline. SEScore2 achieves high correlation to human judgements without any human rating supervisions. Importantly, our unsupervised SEScore2 can outperform supervised metrics, which are trained on the News human ratings, at the TED domain. We evaluate SEScore2 over four text generation tasks across three languages. SEScore2 outperforms all prior unsupervised evaluation metrics in machine translation, speech translation, data-to-text and dialogue generation, with average Kendall improvements 0.158. SEScore2 even outperforms SOTA supervised BLEURT at data-to-text, dialogue generation and overall correlation.
PARAGEN : A Parallel Generation Toolkit
Oct 07, 2022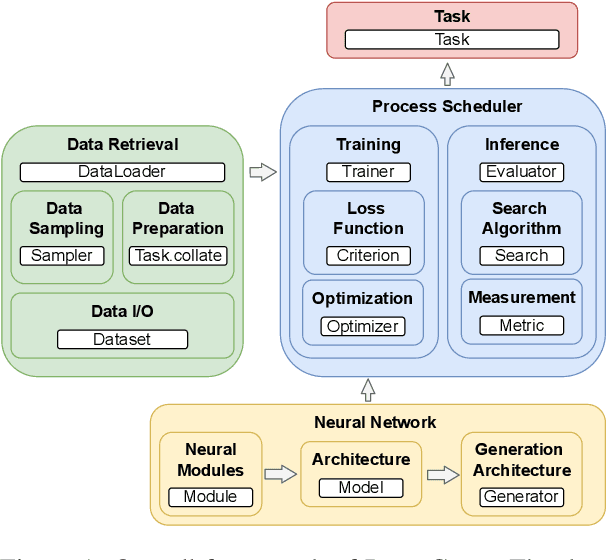

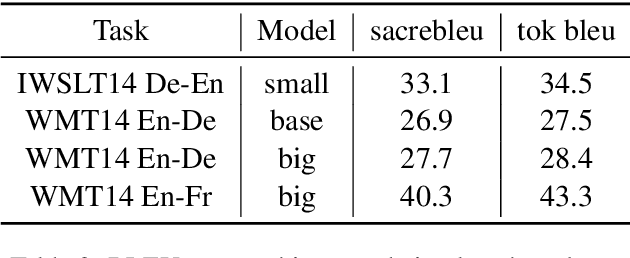
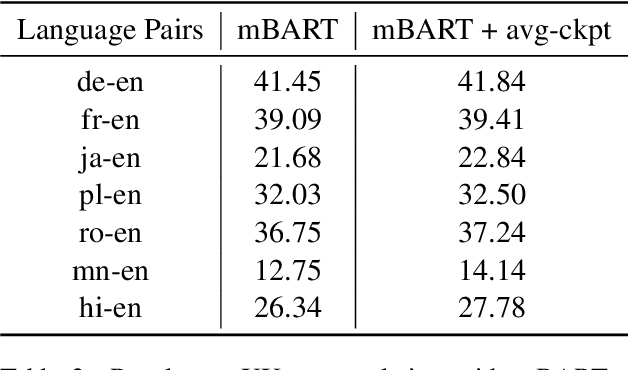
PARAGEN is a PyTorch-based NLP toolkit for further development on parallel generation. PARAGEN provides thirteen types of customizable plugins, helping users to experiment quickly with novel ideas across model architectures, optimization, and learning strategies. We implement various features, such as unlimited data loading and automatic model selection, to enhance its industrial usage. ParaGen is now deployed to support various research and industry applications at ByteDance. PARAGEN is available at https://github.com/bytedance/ParaGen.
LightSeq2: Accelerated Training for Transformer-based Models on GPUs
Oct 27, 2021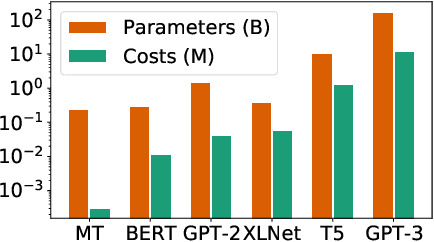

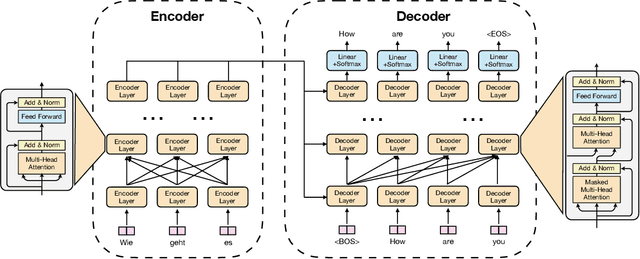
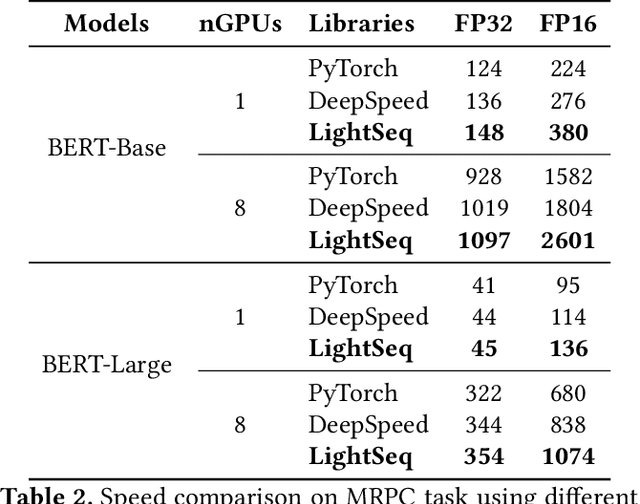
Transformer-based models have proven to be powerful in many natural language, computer vision, and speech recognition applications. It is expensive to train these types of models due to unfixed input length, complex computation, and large numbers of parameters. Existing systems either only focus on efficient inference or optimize only BERT-like encoder models. In this paper, we present LightSeq2, a system for efficient training of Transformer-based models on GPUs. We propose a series of GPU optimization techniques tailored to computation flow and memory access patterns of neural layers in Transformers. LightSeq2 supports a variety of network architectures, including BERT (encoder-only), GPT (decoder-only), and Transformer (encoder-decoder). Our experiments on GPUs with varying models and datasets show that LightSeq2 is 1.4-3.5x faster than previous systems. In particular, it gains 308% training speedup compared with existing systems on a large public machine translation benchmark (WMT14 English-German).