 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJianfeng Gao
MagGAN: High-Resolution Face Attribute Editing with Mask-Guided Generative Adversarial Network
Oct 03, 2020

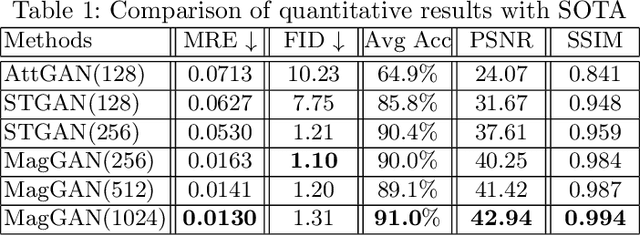

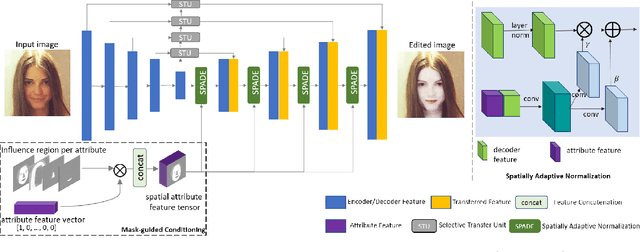
We present Mask-guided Generative Adversarial Network (MagGAN) for high-resolution face attribute editing, in which semantic facial masks from a pre-trained face parser are used to guide the fine-grained image editing process. With the introduction of a mask-guided reconstruction loss, MagGAN learns to only edit the facial parts that are relevant to the desired attribute changes, while preserving the attribute-irrelevant regions (e.g., hat, scarf for modification `To Bald'). Further, a novel mask-guided conditioning strategy is introduced to incorporate the influence region of each attribute change into the generator. In addition, a multi-level patch-wise discriminator structure is proposed to scale our model for high-resolution ($1024 \times 1024$) face editing. Experiments on the CelebA benchmark show that the proposed method significantly outperforms prior state-of-the-art approaches in terms of both image quality and editing performance.
VIVO: Surpassing Human Performance in Novel Object Captioning with Visual Vocabulary Pre-Training
Sep 28, 2020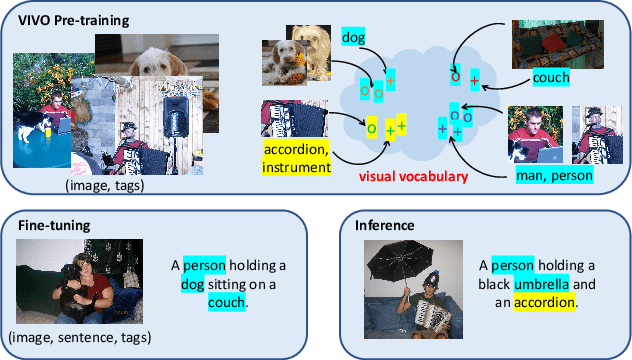
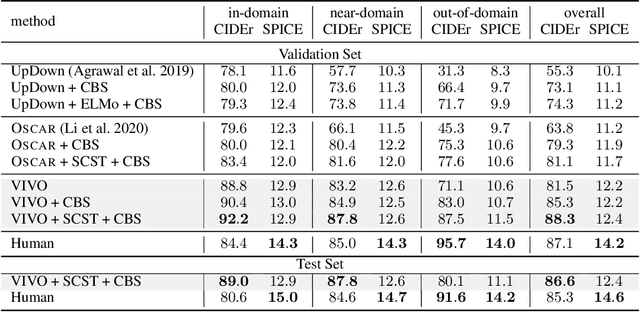
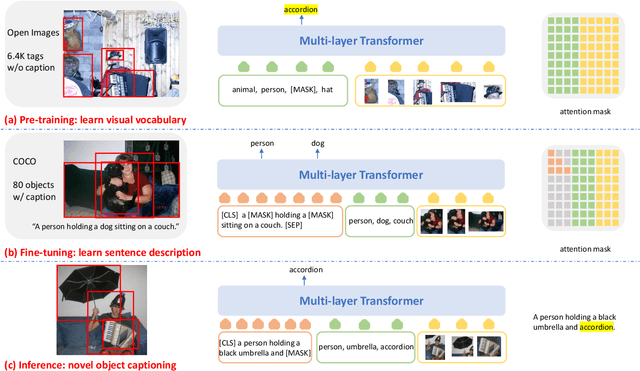

It is highly desirable yet challenging to generate image captions that can describe novel objects which are unseen in caption-labeled training data, a capability that is evaluated in the novel object captioning challenge (nocaps). In this challenge, no additional image-caption training data, other than COCO Captions, is allowed for model training. Thus, conventional Vision-Language Pre-training (VLP) methods cannot be applied. This paper presents VIsual VOcabulary pre-training (VIVO) that performs pre-training in the absence of caption annotations. By breaking the dependency of paired image-caption training data in VLP, VIVO can leverage large amounts of paired image-tag data to learn a visual vocabulary. This is done by pre-training a multi-layer Transformer model that learns to align image-level tags with their corresponding image region features. To address the unordered nature of image tags, VIVO uses a Hungarian matching loss with masked tag prediction to conduct pre-training. We validate the effectiveness of VIVO by fine-tuning the pre-trained model for image captioning. In addition, we perform an analysis of the visual-text alignment inferred by our model. The results show that our model can not only generate fluent image captions that describe novel objects, but also identify the locations of these objects. Our single model has achieved new state-of-the-art results on nocaps and surpassed the human CIDEr score.
Generation-Augmented Retrieval for Open-domain Question Answering
Sep 17, 2020
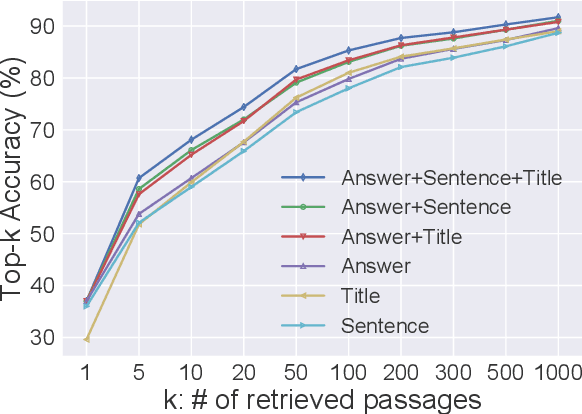
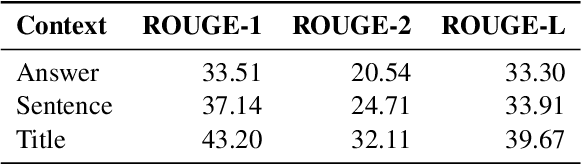
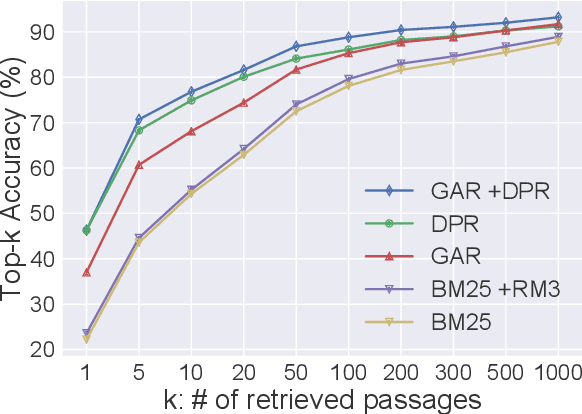
Conventional sparse retrieval methods such as TF-IDF and BM25 are simple and efficient, but solely rely on lexical overlap and fail to conduct semantic matching. Recent dense retrieval methods learn latent representations to tackle the lexical mismatch problem, while being more computationally expensive and sometimes insufficient for exact matching as they embed the entire text sequence into a single vector with limited capacity. In this paper, we present Generation-Augmented Retrieval (GAR), a query expansion method that augments a query with relevant contexts through text generation. We demonstrate on open-domain question answering (QA) that the generated contexts significantly enrich the semantics of the queries and thus GAR with sparse representations (BM25) achieves comparable or better performance than the current state-of-the-art dense method DPR \cite{karpukhin2020dense}. We show that generating various contexts of a query is beneficial as fusing their results consistently yields a better retrieval accuracy. Moreover, GAR achieves the state-of-the-art performance of extractive QA on the Natural Questions and TriviaQA datasets when equipped with an extractive reader.
Robust Conversational AI with Grounded Text Generation
Sep 07, 2020



This article presents a hybrid approach based on a Grounded Text Generation (GTG) model to building robust task bots at scale. GTG is a hybrid model which uses a large-scale Transformer neural network as its backbone, combined with symbol-manipulation modules for knowledge base inference and prior knowledge encoding, to generate responses grounded in dialog belief state and real-world knowledge for task completion. GTG is pre-trained on large amounts of raw text and human conversational data, and can be fine-tuned to complete a wide range of tasks. The hybrid approach and its variants are being developed simultaneously by multiple research teams. The primary results reported on task-oriented dialog benchmarks are very promising, demonstrating the big potential of this approach. This article provides an overview of this progress and discusses related methods and technologies that can be incorporated for building robust conversational AI systems.
HittER: Hierarchical Transformers for Knowledge Graph Embeddings
Aug 28, 2020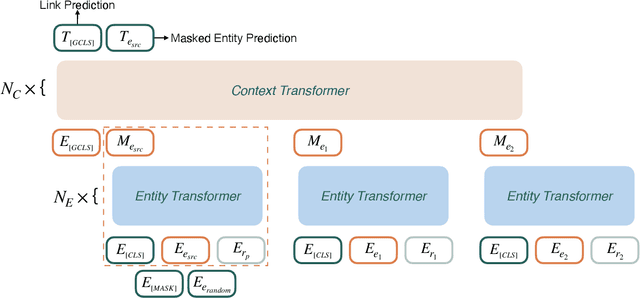
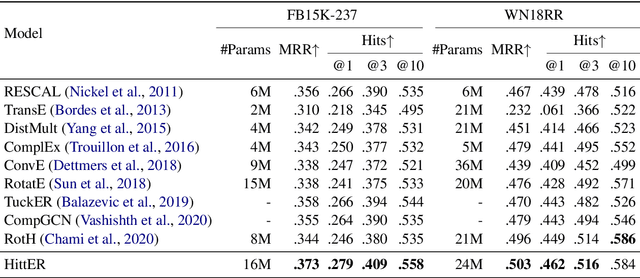
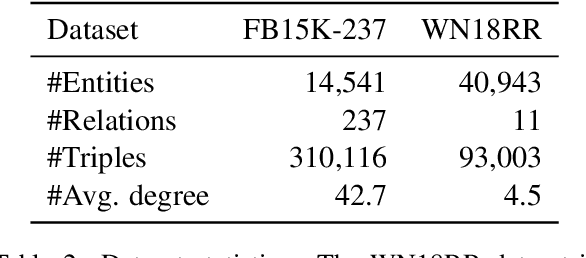

This paper examines the challenging problem of learning representations of entities and relations in a complex multi-relational knowledge graph. We propose HittER, a Hierarchical Transformer model to jointly learn Entity-relation composition and Relational contextualization based on a source entity's neighborhood. Our proposed model consists of two different Transformer blocks: the bottom block extracts features of each entity-relation pair in the local neighborhood of the source entity and the top block aggregates the relational information from the outputs of the bottom block. We further design a masked entity prediction task to balance information from the relational context and the source entity itself. Evaluated on the task of link prediction, our approach achieves new state-of-the-art results on two standard benchmark datasets FB15K-237 and WN18RR.
Domain-Specific Language Model Pretraining for Biomedical Natural Language Processing
Aug 20, 2020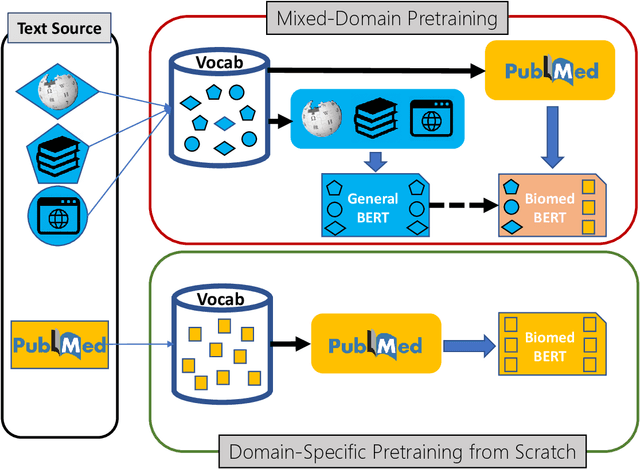
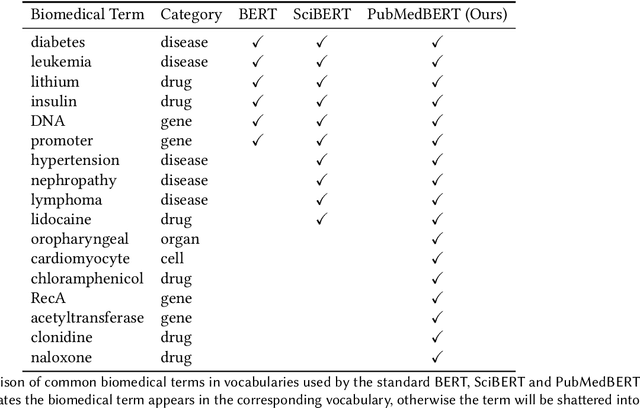
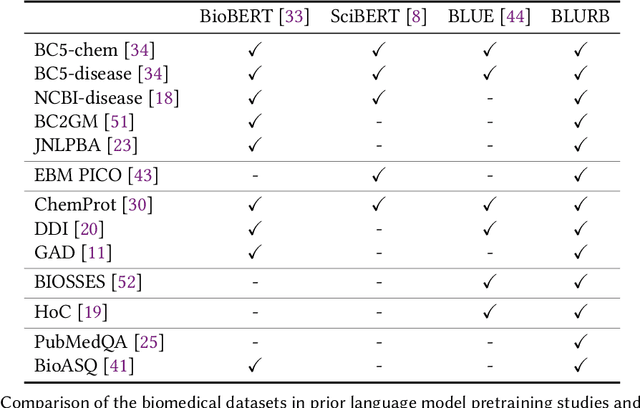
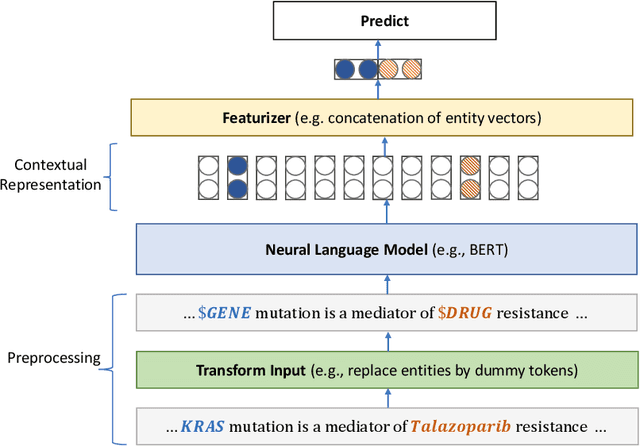
Pretraining large neural language models, such as BERT, has led to impressive gains on many natural language processing (NLP) tasks. However, most pretraining efforts focus on general domain corpora, such as newswire and Web. A prevailing assumption is that even domain-specific pretraining can benefit by starting from general-domain language models. In this paper, we challenge this assumption by showing that for domains with abundant unlabeled text, such as biomedicine, pretraining language models from scratch results in substantial gains over continual pretraining of general-domain language models. To facilitate this investigation, we compile a comprehensive biomedical NLP benchmark from publicly-available datasets. Our experiments show that domain-specific pretraining serves as a solid foundation for a wide range of biomedical NLP tasks, leading to new state-of-the-art results across the board. Further, in conducting a thorough evaluation of modeling choices, both for pretraining and task-specific fine-tuning, we discover that some common practices are unnecessary with BERT models, such as using complex tagging schemes in named entity recognition (NER). To help accelerate research in biomedical NLP, we have released our state-of-the-art pretrained and task-specific models for the community, and created a leaderboard featuring our BLURB benchmark (short for Biomedical Language Understanding & Reasoning Benchmark) at https://aka.ms/BLURB.
Very Deep Transformers for Neural Machine Translation
Aug 18, 2020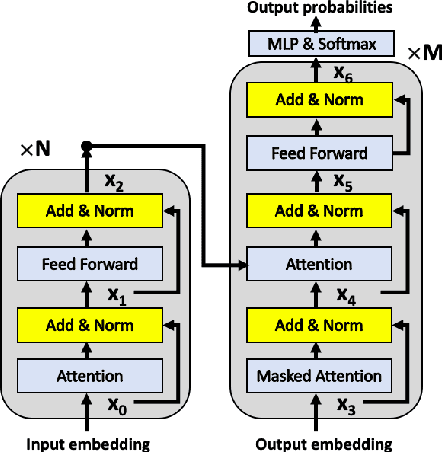
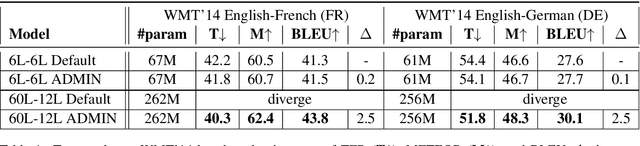
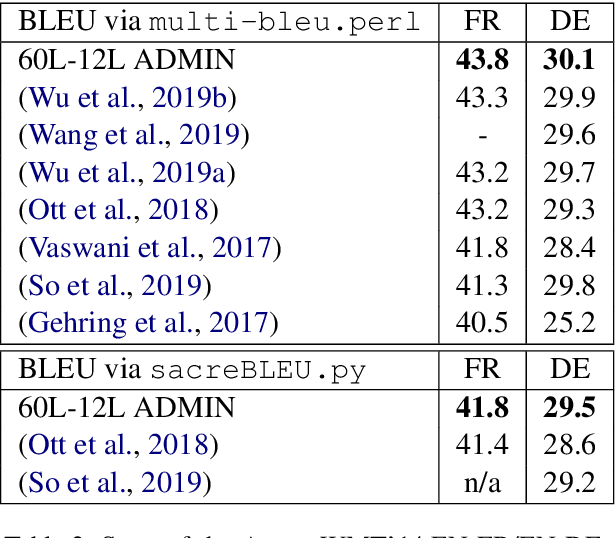
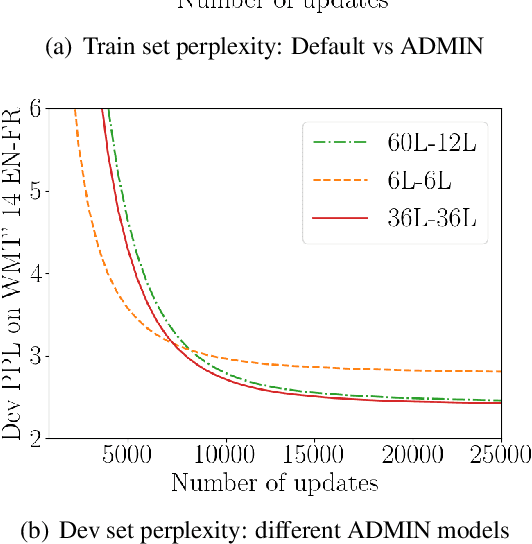
We explore the application of very deep Transformer models for Neural Machine Translation (NMT). Using a simple yet effective initialization technique that stabilizes training, we show that it is feasible to build standard Transformer-based models with up to 60 encoder layers and 12 decoder layers. These deep models outperform their baseline 6-layer counterparts by as much as 2.5 BLEU, and achieve new state-of-the-art benchmark results on WMT14 English-French (43.8 BLEU) and WMT14 English-German (30.1 BLEU).The code and trained models will be publicly available at: https://github.com/namisan/exdeep-nmt.
Evaluation of Text Generation: A Survey
Jun 26, 2020

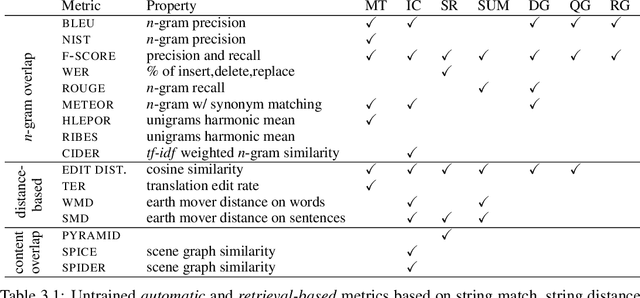
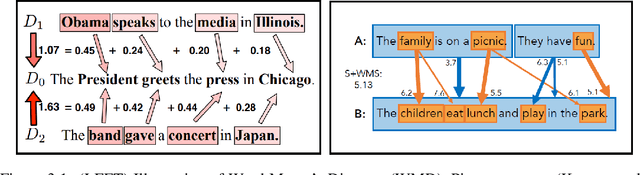
The paper surveys evaluation methods of natural language generation (NLG) systems that have been developed in the last few years. We group NLG evaluation methods into three categories: (1) human-centric evaluation metrics, (2) automatic metrics that require no training, and (3) machine-learned metrics. For each category, we discuss the progress that has been made and the challenges still being faced, with a focus on the evaluation of recently proposed NLG tasks and neural NLG models. We then present two case studies of automatic text summarization and long text generation, and conclude the paper by proposing future research directions.