 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Protein Optimization via Structure-aware Hamiltonian Dynamics
Jan 16, 2026The ability to engineer optimized protein variants has transformative potential for biotechnology and medicine. Prior sequence-based optimization methods struggle with the high-dimensional complexities due to the epistasis effect and the disregard for structural constraints. To address this, we propose HADES, a Bayesian optimization method utilizing Hamiltonian dynamics to efficiently sample from a structure-aware approximated posterior. Leveraging momentum and uncertainty in the simulated physical movements, HADES enables rapid transition of proposals toward promising areas. A position discretization procedure is introduced to propose discrete protein sequences from such a continuous state system. The posterior surrogate is powered by a two-stage encoder-decoder framework to determine the structure and function relationships between mutant neighbors, consequently learning a smoothed landscape to sample from. Extensive experiments demonstrate that our method outperforms state-of-the-art baselines in in-silico evaluations across most metrics. Remarkably, our approach offers a unique advantage by leveraging the mutual constraints between protein structure and sequence, facilitating the design of protein sequences with similar structures and optimized properties. The code and data are publicly available at https://github.com/GENTEL-lab/HADES.
Interpretable Probability Estimation with LLMs via Shapley Reconstruction
Jan 14, 2026Large Language Models (LLMs) demonstrate potential to estimate the probability of uncertain events, by leveraging their extensive knowledge and reasoning capabilities. This ability can be applied to support intelligent decision-making across diverse fields, such as financial forecasting and preventive healthcare. However, directly prompting LLMs for probability estimation faces significant challenges: their outputs are often noisy, and the underlying predicting process is opaque. In this paper, we propose PRISM: Probability Reconstruction via Shapley Measures, a framework that brings transparency and precision to LLM-based probability estimation. PRISM decomposes an LLM's prediction by quantifying the marginal contribution of each input factor using Shapley values. These factor-level contributions are then aggregated to reconstruct a calibrated final estimate. In our experiments, we demonstrate PRISM improves predictive accuracy over direct prompting and other baselines, across multiple domains including finance, healthcare, and agriculture. Beyond performance, PRISM provides a transparent prediction pipeline: our case studies visualize how individual factors shape the final estimate, helping build trust in LLM-based decision support systems.
CellMamba: Adaptive Mamba for Accurate and Efficient Cell Detection
Dec 25, 2025



Cell detection in pathological images presents unique challenges due to densely packed objects, subtle inter-class differences, and severe background clutter. In this paper, we propose CellMamba, a lightweight and accurate one-stage detector tailored for fine-grained biomedical instance detection. Built upon a VSSD backbone, CellMamba integrates CellMamba Blocks, which couple either NC-Mamba or Multi-Head Self-Attention (MSA) with a novel Triple-Mapping Adaptive Coupling (TMAC) module. TMAC enhances spatial discriminability by splitting channels into two parallel branches, equipped with dual idiosyncratic and one consensus attention map, adaptively fused to preserve local sensitivity and global consistency. Furthermore, we design an Adaptive Mamba Head that fuses multi-scale features via learnable weights for robust detection under varying object sizes. Extensive experiments on two public datasets-CoNSeP and CytoDArk0-demonstrate that CellMamba outperforms both CNN-based, Transformer-based, and Mamba-based baselines in accuracy, while significantly reducing model size and inference latency. Our results validate CellMamba as an efficient and effective solution for high-resolution cell detection.
T2AV-Compass: Towards Unified Evaluation for Text-to-Audio-Video Generation
Dec 24, 2025Text-to-Audio-Video (T2AV) generation aims to synthesize temporally coherent video and semantically synchronized audio from natural language, yet its evaluation remains fragmented, often relying on unimodal metrics or narrowly scoped benchmarks that fail to capture cross-modal alignment, instruction following, and perceptual realism under complex prompts. To address this limitation, we present T2AV-Compass, a unified benchmark for comprehensive evaluation of T2AV systems, consisting of 500 diverse and complex prompts constructed via a taxonomy-driven pipeline to ensure semantic richness and physical plausibility. Besides, T2AV-Compass introduces a dual-level evaluation framework that integrates objective signal-level metrics for video quality, audio quality, and cross-modal alignment with a subjective MLLM-as-a-Judge protocol for instruction following and realism assessment. Extensive evaluation of 11 representative T2AVsystems reveals that even the strongest models fall substantially short of human-level realism and cross-modal consistency, with persistent failures in audio realism, fine-grained synchronization, instruction following, etc. These results indicate significant improvement room for future models and highlight the value of T2AV-Compass as a challenging and diagnostic testbed for advancing text-to-audio-video generation.
EchoMotion: Unified Human Video and Motion Generation via Dual-Modality Diffusion Transformer
Dec 21, 2025Video generation models have advanced significantly, yet they still struggle to synthesize complex human movements due to the high degrees of freedom in human articulation. This limitation stems from the intrinsic constraints of pixel-only training objectives, which inherently bias models toward appearance fidelity at the expense of learning underlying kinematic principles. To address this, we introduce EchoMotion, a framework designed to model the joint distribution of appearance and human motion, thereby improving the quality of complex human action video generation. EchoMotion extends the DiT (Diffusion Transformer) framework with a dual-branch architecture that jointly processes tokens concatenated from different modalities. Furthermore, we propose MVS-RoPE (Motion-Video Syncronized RoPE), which offers unified 3D positional encoding for both video and motion tokens. By providing a synchronized coordinate system for the dual-modal latent sequence, MVS-RoPE establishes an inductive bias that fosters temporal alignment between the two modalities. We also propose a Motion-Video Two-Stage Training Strategy. This strategy enables the model to perform both the joint generation of complex human action videos and their corresponding motion sequences, as well as versatile cross-modal conditional generation tasks. To facilitate the training of a model with these capabilities, we construct HuMoVe, a large-scale dataset of approximately 80,000 high-quality, human-centric video-motion pairs. Our findings reveal that explicitly representing human motion is complementary to appearance, significantly boosting the coherence and plausibility of human-centric video generation.
Can We Predict the Next Question? A Collaborative Filtering Approach to Modeling User Behavior
Nov 17, 2025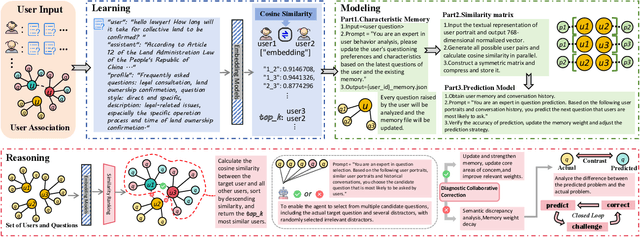
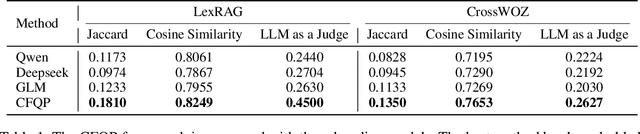


In recent years, large language models (LLMs) have excelled in language understanding and generation, powering advanced dialogue and recommendation systems. However, a significant limitation persists: these systems often model user preferences statically, failing to capture the dynamic and sequential nature of interactive behaviors. The sequence of a user's historical questions provides a rich, implicit signal of evolving interests and cognitive patterns, yet leveraging this temporal data for predictive tasks remains challenging due to the inherent disconnect between language modeling and behavioral sequence modeling. To bridge this gap, we propose a Collaborative Filtering-enhanced Question Prediction (CFQP) framework. CFQP dynamically models evolving user-question interactions by integrating personalized memory modules with graph-based preference propagation. This dual mechanism allows the system to adaptively learn from user-specific histories while refining predictions through collaborative signals from similar users. Experimental results demonstrate that our approach effectively generates agents that mimic real-user questioning patterns, highlighting its potential for building proactive and adaptive dialogue systems.
SRLF: An Agent-Driven Set-Wise Reflective Learning Framework for Sequential Recommendation
Nov 14, 2025LLM-based agents are emerging as a promising paradigm for simulating user behavior to enhance recommender systems. However, their effectiveness is often limited by existing studies that focus on modeling user ratings for individual items. This point-wise approach leads to prevalent issues such as inaccurate user preference comprehension and rigid item-semantic representations. To address these limitations, we propose the novel Set-wise Reflective Learning Framework (SRLF). Our framework operationalizes a closed-loop "assess-validate-reflect" cycle that harnesses the powerful in-context learning capabilities of LLMs. SRLF departs from conventional point-wise assessment by formulating a holistic judgment on an entire set of items. It accomplishes this by comprehensively analyzing both the intricate interrelationships among items within the set and their collective alignment with the user's preference profile. This method of set-level contextual understanding allows our model to capture complex relational patterns essential to user behavior, making it significantly more adept for sequential recommendation. Extensive experiments validate our approach, confirming that this set-wise perspective is crucial for achieving state-of-the-art performance in sequential recommendation tasks.
Enhancing the Outcome Reward-based RL Training of MLLMs with Self-Consistency Sampling
Nov 13, 2025



Outcome-reward reinforcement learning (RL) is a common and increasingly significant way to refine the step-by-step reasoning of multimodal large language models (MLLMs). In the multiple-choice setting - a dominant format for multimodal reasoning benchmarks - the paradigm faces a significant yet often overlooked obstacle: unfaithful trajectories that guess the correct option after a faulty chain of thought receive the same reward as genuine reasoning, which is a flaw that cannot be ignored. We propose Self-Consistency Sampling (SCS) to correct this issue. For each question, SCS (i) introduces small visual perturbations and (ii) performs repeated truncation and resampling of an initial trajectory; agreement among the resulting trajectories yields a differentiable consistency score that down-weights unreliable traces during policy updates. Based on Qwen2.5-VL-7B-Instruct, plugging SCS into RLOO, GRPO, and REINFORCE++ series improves accuracy by up to 7.7 percentage points on six multimodal benchmarks with negligible extra computation. SCS also yields notable gains on both Qwen2.5-VL-3B-Instruct and InternVL3-8B, offering a simple, general remedy for outcome-reward RL in MLLMs.
JointCQ: Improving Factual Hallucination Detection with Joint Claim and Query Generation
Oct 22, 2025Current large language models (LLMs) often suffer from hallucination issues, i,e, generating content that appears factual but is actually unreliable. A typical hallucination detection pipeline involves response decomposition (i.e., claim extraction), query generation, evidence collection (i.e., search or retrieval), and claim verification. However, existing methods exhibit limitations in the first two stages, such as context loss during claim extraction and low specificity in query generation, resulting in degraded performance across the hallucination detection pipeline. In this work, we introduce JointCQ https://github.com/pku0xff/JointCQ, a joint claim-and-query generation framework designed to construct an effective and efficient claim-query generator. Our framework leverages elaborately designed evaluation criteria to filter synthesized training data, and finetunes a language model for joint claim extraction and query generation, providing reliable and informative inputs for downstream search and verification. Experimental results demonstrate that our method outperforms previous methods on multiple open-domain QA hallucination detection benchmarks, advancing the goal of more trustworthy and transparent language model systems.
SpatialVID: A Large-Scale Video Dataset with Spatial Annotations
Sep 11, 2025Significant progress has been made in spatial intelligence, spanning both spatial reconstruction and world exploration. However, the scalability and real-world fidelity of current models remain severely constrained by the scarcity of large-scale, high-quality training data. While several datasets provide camera pose information, they are typically limited in scale, diversity, and annotation richness, particularly for real-world dynamic scenes with ground-truth camera motion. To this end, we collect \textbf{SpatialVID}, a dataset consists of a large corpus of in-the-wild videos with diverse scenes, camera movements and dense 3D annotations such as per-frame camera poses, depth, and motion instructions. Specifically, we collect more than 21,000 hours of raw video, and process them into 2.7 million clips through a hierarchical filtering pipeline, totaling 7,089 hours of dynamic content. A subsequent annotation pipeline enriches these clips with detailed spatial and semantic information, including camera poses, depth maps, dynamic masks, structured captions, and serialized motion instructions. Analysis of SpatialVID's data statistics reveals a richness and diversity that directly foster improved model generalization and performance, establishing it as a key asset for the video and 3D vision research community.