 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervision-by-Hallucination-and-Transfer: A Weakly-Supervised Approach for Robust and Precise Facial Landmark Detection
Jan 19, 2026High-precision facial landmark detection (FLD) relies on high-resolution deep feature representations. However, low-resolution face images or the compression (via pooling or strided convolution) of originally high-resolution images hinder the learning of such features, thereby reducing FLD accuracy. Moreover, insufficient training data and imprecise annotations further degrade performance. To address these challenges, we propose a weakly-supervised framework called Supervision-by-Hallucination-and-Transfer (SHT) for more robust and precise FLD. SHT contains two novel mutually enhanced modules: Dual Hallucination Learning Network (DHLN) and Facial Pose Transfer Network (FPTN). By incorporating FLD and face hallucination tasks, DHLN is able to learn high-resolution representations with low-resolution inputs for recovering both facial structures and local details and generating more effective landmark heatmaps. Then, by transforming faces from one pose to another, FPTN can further improve landmark heatmaps and faces hallucinated by DHLN for detecting more accurate landmarks. To the best of our knowledge, this is the first study to explore weakly-supervised FLD by integrating face hallucination and facial pose transfer tasks. Experimental results of both face hallucination and FLD demonstrate that our method surpasses state-of-the-art techniques.
CellMamba: Adaptive Mamba for Accurate and Efficient Cell Detection
Dec 25, 2025



Cell detection in pathological images presents unique challenges due to densely packed objects, subtle inter-class differences, and severe background clutter. In this paper, we propose CellMamba, a lightweight and accurate one-stage detector tailored for fine-grained biomedical instance detection. Built upon a VSSD backbone, CellMamba integrates CellMamba Blocks, which couple either NC-Mamba or Multi-Head Self-Attention (MSA) with a novel Triple-Mapping Adaptive Coupling (TMAC) module. TMAC enhances spatial discriminability by splitting channels into two parallel branches, equipped with dual idiosyncratic and one consensus attention map, adaptively fused to preserve local sensitivity and global consistency. Furthermore, we design an Adaptive Mamba Head that fuses multi-scale features via learnable weights for robust detection under varying object sizes. Extensive experiments on two public datasets-CoNSeP and CytoDArk0-demonstrate that CellMamba outperforms both CNN-based, Transformer-based, and Mamba-based baselines in accuracy, while significantly reducing model size and inference latency. Our results validate CellMamba as an efficient and effective solution for high-resolution cell detection.
FaceBench: A Multi-View Multi-Level Facial Attribute VQA Dataset for Benchmarking Face Perception MLLMs
Mar 27, 2025



Multimodal large language models (MLLMs) have demonstrated remarkable capabilities in various tasks. However, effectively evaluating these MLLMs on face perception remains largely unexplored. To address this gap, we introduce FaceBench, a dataset featuring hierarchical multi-view and multi-level attributes specifically designed to assess the comprehensive face perception abilities of MLLMs. Initially, we construct a hierarchical facial attribute structure, which encompasses five views with up to three levels of attributes, totaling over 210 attributes and 700 attribute values. Based on the structure, the proposed FaceBench consists of 49,919 visual question-answering (VQA) pairs for evaluation and 23,841 pairs for fine-tuning. Moreover, we further develop a robust face perception MLLM baseline, Face-LLaVA, by training with our proposed face VQA data. Extensive experiments on various mainstream MLLMs and Face-LLaVA are conducted to test their face perception ability, with results also compared against human performance. The results reveal that, the existing MLLMs are far from satisfactory in understanding the fine-grained facial attributes, while our Face-LLaVA significantly outperforms existing open-source models with a small amount of training data and is comparable to commercial ones like GPT-4o and Gemini. The dataset will be released at https://github.com/CVI-SZU/FaceBench.
Low-Light Enhancement Effect on Classification and Detection: An Empirical Study
Sep 22, 2024Low-light images are commonly encountered in real-world scenarios, and numerous low-light image enhancement (LLIE) methods have been proposed to improve the visibility of these images. The primary goal of LLIE is to generate clearer images that are more visually pleasing to humans. However, the impact of LLIE methods in high-level vision tasks, such as image classification and object detection, which rely on high-quality image datasets, is not well {explored}. To explore the impact, we comprehensively evaluate LLIE methods on these high-level vision tasks by utilizing an empirical investigation comprising image classification and object detection experiments. The evaluation reveals a dichotomy: {\textit{While Low-Light Image Enhancement (LLIE) methods enhance human visual interpretation, their effect on computer vision tasks is inconsistent and can sometimes be harmful. }} Our findings suggest a disconnect between image enhancement for human visual perception and for machine analysis, indicating a need for LLIE methods tailored to support high-level vision tasks effectively. This insight is crucial for the development of LLIE techniques that align with the needs of both human and machine vision.
Dynamic data sampler for cross-language transfer learning in large language models
May 17, 2024Large Language Models (LLMs) have gained significant attention in the field of natural language processing (NLP) due to their wide range of applications. However, training LLMs for languages other than English poses significant challenges, due to the difficulty in acquiring large-scale corpus and the requisite computing resources. In this paper, we propose ChatFlow, a cross-language transfer-based LLM, to address these challenges and train large Chinese language models in a cost-effective manner. We employ a mix of Chinese, English, and parallel corpus to continuously train the LLaMA2 model, aiming to align cross-language representations and facilitate the knowledge transfer specifically to the Chinese language model. In addition, we use a dynamic data sampler to progressively transition the model from unsupervised pre-training to supervised fine-tuning. Experimental results demonstrate that our approach accelerates model convergence and achieves superior performance. We evaluate ChatFlow on popular Chinese and English benchmarks, the results indicate that it outperforms other Chinese models post-trained on LLaMA-2-7B.
A Dataset and Model for Realistic License Plate Deblurring
Apr 23, 2024



Vehicle license plate recognition is a crucial task in intelligent traffic management systems. However, the challenge of achieving accurate recognition persists due to motion blur from fast-moving vehicles. Despite the widespread use of image synthesis approaches in existing deblurring and recognition algorithms, their effectiveness in real-world scenarios remains unproven. To address this, we introduce the first large-scale license plate deblurring dataset named License Plate Blur (LPBlur), captured by a dual-camera system and processed through a post-processing pipeline to avoid misalignment issues. Then, we propose a License Plate Deblurring Generative Adversarial Network (LPDGAN) to tackle the license plate deblurring: 1) a Feature Fusion Module to integrate multi-scale latent codes; 2) a Text Reconstruction Module to restore structure through textual modality; 3) a Partition Discriminator Module to enhance the model's perception of details in each letter. Extensive experiments validate the reliability of the LPBlur dataset for both model training and testing, showcasing that our proposed model outperforms other state-of-the-art motion deblurring methods in realistic license plate deblurring scenarios. The dataset and code are available at https://github.com/haoyGONG/LPDGAN.
DuAT: Dual-Aggregation Transformer Network for Medical Image Segmentation
Dec 21, 2022



Transformer-based models have been widely demonstrated to be successful in computer vision tasks by modelling long-range dependencies and capturing global representations. However, they are often dominated by features of large patterns leading to the loss of local details (e.g., boundaries and small objects), which are critical in medical image segmentation. To alleviate this problem, we propose a Dual-Aggregation Transformer Network called DuAT, which is characterized by two innovative designs, namely, the Global-to-Local Spatial Aggregation (GLSA) and Selective Boundary Aggregation (SBA) modules. The GLSA has the ability to aggregate and represent both global and local spatial features, which are beneficial for locating large and small objects, respectively. The SBA module is used to aggregate the boundary characteristic from low-level features and semantic information from high-level features for better preserving boundary details and locating the re-calibration objects. Extensive experiments in six benchmark datasets demonstrate that our proposed model outperforms state-of-the-art methods in the segmentation of skin lesion images, and polyps in colonoscopy images. In addition, our approach is more robust than existing methods in various challenging situations such as small object segmentation and ambiguous object boundaries.
Cross Language Image Matching for Weakly Supervised Semantic Segmentation
Mar 25, 2022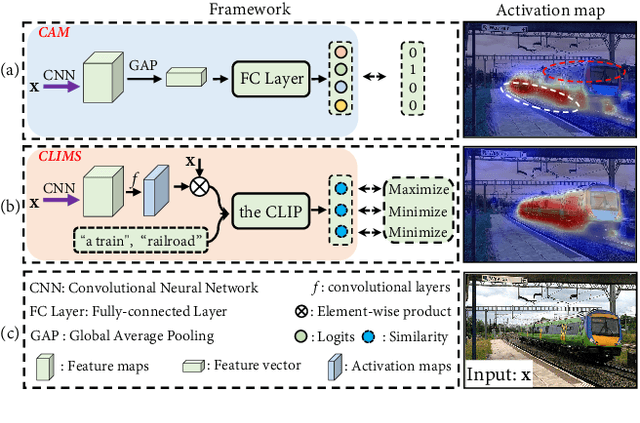
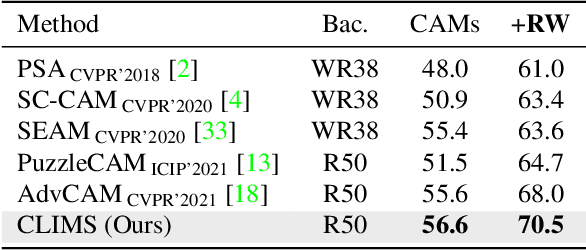
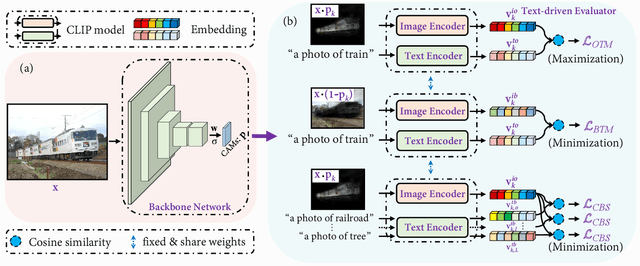

It has been widely known that CAM (Class Activation Map) usually only activates discriminative object regions and falsely includes lots of object-related backgrounds. As only a fixed set of image-level object labels are available to the WSSS (weakly supervised semantic segmentation) model, it could be very difficult to suppress those diverse background regions consisting of open set objects. In this paper, we propose a novel Cross Language Image Matching (CLIMS) framework, based on the recently introduced Contrastive Language-Image Pre-training (CLIP) model, for WSSS. The core idea of our framework is to introduce natural language supervision to activate more complete object regions and suppress closely-related open background regions. In particular, we design object, background region and text label matching losses to guide the model to excite more reasonable object regions for CAM of each category. In addition, we design a co-occurring background suppression loss to prevent the model from activating closely-related background regions, with a predefined set of class-related background text descriptions. These designs enable the proposed CLIMS to generate a more complete and compact activation map for the target objects. Extensive experiments on PASCAL VOC2012 dataset show that our CLIMS significantly outperforms the previous state-of-the-art methods.
Contrastive learning of Class-agnostic Activation Map for Weakly Supervised Object Localization and Semantic Segmentation
Mar 25, 2022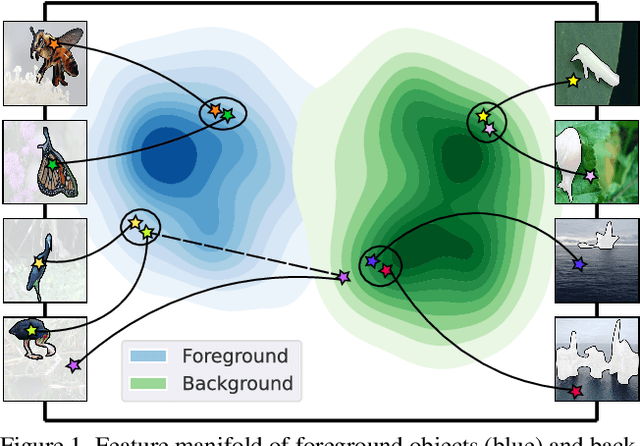
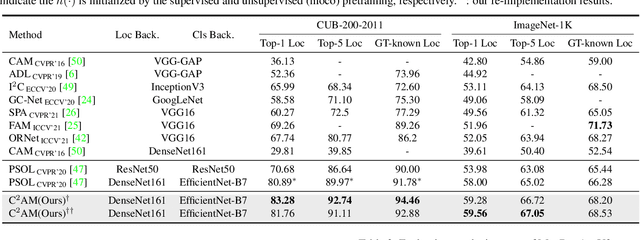
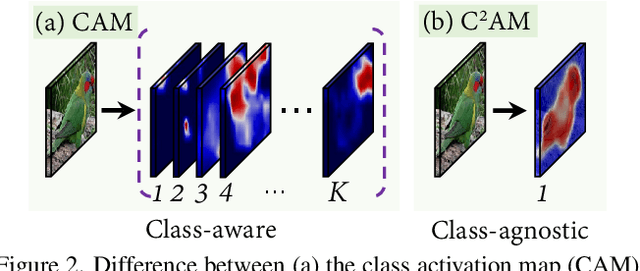
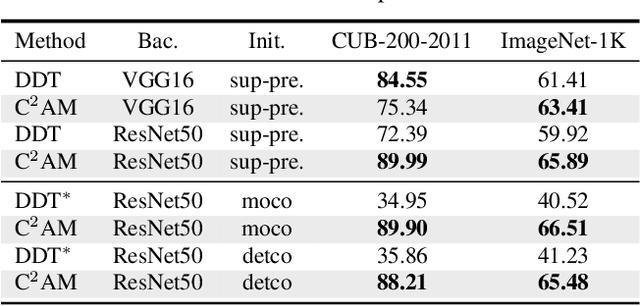
While class activation map (CAM) generated by image classification network has been widely used for weakly supervised object localization (WSOL) and semantic segmentation (WSSS), such classifiers usually focus on discriminative object regions. In this paper, we propose Contrastive learning for Class-agnostic Activation Map (C$^2$AM) generation only using unlabeled image data, without the involvement of image-level supervision. The core idea comes from the observation that i) semantic information of foreground objects usually differs from their backgrounds; ii) foreground objects with similar appearance or background with similar color/texture have similar representations in the feature space. We form the positive and negative pairs based on the above relations and force the network to disentangle foreground and background with a class-agnostic activation map using a novel contrastive loss. As the network is guided to discriminate cross-image foreground-background, the class-agnostic activation maps learned by our approach generate more complete object regions. We successfully extracted from C$^2$AM class-agnostic object bounding boxes for object localization and background cues to refine CAM generated by classification network for semantic segmentation. Extensive experiments on CUB-200-2011, ImageNet-1K, and PASCAL VOC2012 datasets show that both WSOL and WSSS can benefit from the proposed C$^2$AM.
FEAT: Face Editing with Attention
Feb 06, 2022Employing the latent space of pretrained generators has recently been shown to be an effective means for GAN-based face manipulation. The success of this approach heavily relies on the innate disentanglement of the latent space axes of the generator. However, face manipulation often intends to affect local regions only, while common generators do not tend to have the necessary spatial disentanglement. In this paper, we build on the StyleGAN generator, and present a method that explicitly encourages face manipulation to focus on the intended regions by incorporating learned attention maps. During the generation of the edited image, the attention map serves as a mask that guides a blending between the original features and the modified ones. The guidance for the latent space edits is achieved by employing CLIP, which has recently been shown to be effective for text-driven edits. We perform extensive experiments and show that our method can perform disentangled and controllable face manipulations based on text descriptions by attending to the relevant regions only. Both qualitative and quantitative experimental results demonstrate the superiority of our method for facial region editing over alternative methods.