 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDR$^{3}$-Eval: Towards Realistic and Reproducible Deep Research Evaluation
Apr 16, 2026Deep Research Agents (DRAs) aim to solve complex, long-horizon research tasks involving planning, retrieval, multimodal understanding, and report generation, yet their evaluation remains challenging due to dynamic web environments and ambiguous task definitions. We propose DR$^{3}$-Eval, a realistic and reproducible benchmark for evaluating deep research agents on multimodal, multi-file report generation. DR$^{3}$-Eval is constructed from authentic user-provided materials and paired with a per-task static research sandbox corpus that simulates open-web complexity while remaining fully verifiable, containing supportive documents, distractors, and noise. Moreover, we introduce a multi-dimensional evaluation framework measuring Information Recall, Factual Accuracy, Citation Coverage, Instruction Following, and Depth Quality, and validate its alignment with human judgments. Experiments with our developed multi-agent system DR$^{3}$-Agent based on multiple state-of-the-art language models demonstrate that DR$^{3}$-Eval is highly challenging and reveals critical failure modes in retrieval robustness and hallucination control. Our code and data are publicly available.
T2AV-Compass: Towards Unified Evaluation for Text-to-Audio-Video Generation
Dec 24, 2025Text-to-Audio-Video (T2AV) generation aims to synthesize temporally coherent video and semantically synchronized audio from natural language, yet its evaluation remains fragmented, often relying on unimodal metrics or narrowly scoped benchmarks that fail to capture cross-modal alignment, instruction following, and perceptual realism under complex prompts. To address this limitation, we present T2AV-Compass, a unified benchmark for comprehensive evaluation of T2AV systems, consisting of 500 diverse and complex prompts constructed via a taxonomy-driven pipeline to ensure semantic richness and physical plausibility. Besides, T2AV-Compass introduces a dual-level evaluation framework that integrates objective signal-level metrics for video quality, audio quality, and cross-modal alignment with a subjective MLLM-as-a-Judge protocol for instruction following and realism assessment. Extensive evaluation of 11 representative T2AVsystems reveals that even the strongest models fall substantially short of human-level realism and cross-modal consistency, with persistent failures in audio realism, fine-grained synchronization, instruction following, etc. These results indicate significant improvement room for future models and highlight the value of T2AV-Compass as a challenging and diagnostic testbed for advancing text-to-audio-video generation.
Rectified Noise: A Generative Model Using Positive-incentive Noise
Nov 12, 2025Rectified Flow (RF) has been widely used as an effective generative model. Although RF is primarily based on probability flow Ordinary Differential Equations (ODE), recent studies have shown that injecting noise through reverse-time Stochastic Differential Equations (SDE) for sampling can achieve superior generative performance. Inspired by Positive-incentive Noise (pi-noise), we propose an innovative generative algorithm to train pi-noise generators, namely Rectified Noise (RN), which improves the generative performance by injecting pi-noise into the velocity field of pre-trained RF models. After introducing the Rectified Noise pipeline, pre-trained RF models can be efficiently transformed into pi-noise generators. We validate Rectified Noise by conducting extensive experiments across various model architectures on different datasets. Notably, we find that: (1) RF models using Rectified Noise reduce FID from 10.16 to 9.05 on ImageNet-1k. (2) The models of pi-noise generators achieve improved performance with only 0.39% additional training parameters.
Unsupervised Visible-light Images Guided Cross-Spectrum Depth Estimation from Dual-Modality Cameras
Apr 30, 2022
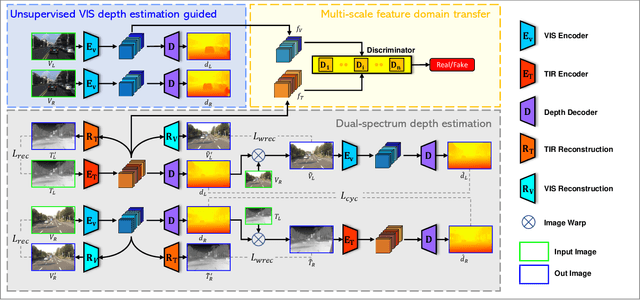


Cross-spectrum depth estimation aims to provide a depth map in all illumination conditions with a pair of dual-spectrum images. It is valuable for autonomous vehicle applications when the vehicle is equipped with two cameras of different modalities. However, images captured by different-modality cameras can be photometrically quite different. Therefore, cross-spectrum depth estimation is a very challenging problem. Moreover, the shortage of large-scale open-source datasets also retards further research in this field. In this paper, we propose an unsupervised visible-light image guided cross-spectrum (i.e., thermal and visible-light, TIR-VIS in short) depth estimation framework given a pair of RGB and thermal images captured from a visible-light camera and a thermal one. We first adopt a base depth estimation network using RGB-image pairs. Then we propose a multi-scale feature transfer network to transfer features from the TIR-VIS domain to the VIS domain at the feature level to fit the trained depth estimation network. At last, we propose a cross-spectrum depth cycle consistency to improve the depth result of dual-spectrum image pairs. Meanwhile, we release a large dual-spectrum depth estimation dataset with visible-light and far-infrared stereo images captured in different scenes to the society. The experiment result shows that our method achieves better performance than the compared existing methods. Our datasets is available at https://github.com/whitecrow1027/VIS-TIR-Datasets.