 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan We Predict the Next Question? A Collaborative Filtering Approach to Modeling User Behavior
Nov 17, 2025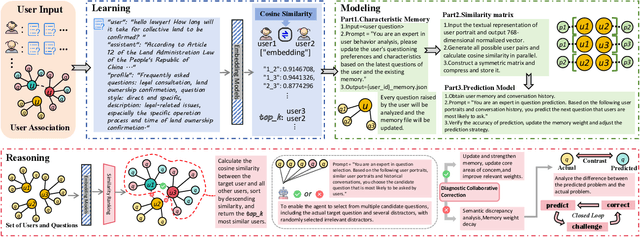


In recent years, large language models (LLMs) have excelled in language understanding and generation, powering advanced dialogue and recommendation systems. However, a significant limitation persists: these systems often model user preferences statically, failing to capture the dynamic and sequential nature of interactive behaviors. The sequence of a user's historical questions provides a rich, implicit signal of evolving interests and cognitive patterns, yet leveraging this temporal data for predictive tasks remains challenging due to the inherent disconnect between language modeling and behavioral sequence modeling. To bridge this gap, we propose a Collaborative Filtering-enhanced Question Prediction (CFQP) framework. CFQP dynamically models evolving user-question interactions by integrating personalized memory modules with graph-based preference propagation. This dual mechanism allows the system to adaptively learn from user-specific histories while refining predictions through collaborative signals from similar users. Experimental results demonstrate that our approach effectively generates agents that mimic real-user questioning patterns, highlighting its potential for building proactive and adaptive dialogue systems.
SRLF: An Agent-Driven Set-Wise Reflective Learning Framework for Sequential Recommendation
Nov 14, 2025LLM-based agents are emerging as a promising paradigm for simulating user behavior to enhance recommender systems. However, their effectiveness is often limited by existing studies that focus on modeling user ratings for individual items. This point-wise approach leads to prevalent issues such as inaccurate user preference comprehension and rigid item-semantic representations. To address these limitations, we propose the novel Set-wise Reflective Learning Framework (SRLF). Our framework operationalizes a closed-loop "assess-validate-reflect" cycle that harnesses the powerful in-context learning capabilities of LLMs. SRLF departs from conventional point-wise assessment by formulating a holistic judgment on an entire set of items. It accomplishes this by comprehensively analyzing both the intricate interrelationships among items within the set and their collective alignment with the user's preference profile. This method of set-level contextual understanding allows our model to capture complex relational patterns essential to user behavior, making it significantly more adept for sequential recommendation. Extensive experiments validate our approach, confirming that this set-wise perspective is crucial for achieving state-of-the-art performance in sequential recommendation tasks.
A Universal Sets-level Optimization Framework for Next Set Recommendation
Oct 30, 2024Next Set Recommendation (NSRec), encompassing related tasks such as next basket recommendation and temporal sets prediction, stands as a trending research topic. Although numerous attempts have been made on this topic, there are certain drawbacks: (i) Existing studies are still confined to utilizing objective functions commonly found in Next Item Recommendation (NIRec), such as binary cross entropy and BPR, which are calculated based on individual item comparisons; (ii) They place emphasis on building sophisticated learning models to capture intricate dependency relationships across sequential sets, but frequently overlook pivotal dependency in their objective functions; (iii) Diversity factor within sequential sets is frequently overlooked. In this research, we endeavor to unveil a universal and S ets-level optimization framework for N ext Set Recommendation (SNSRec), offering a holistic fusion of diversity distribution and intricate dependency relationships within temporal sets. To realize this, the following contributions are made: (i) We directly model the temporal set in a sequence as a cohesive entity, leveraging the Structured Determinantal Point Process (SDPP), wherein the probabilistic DPP distribution prioritizes collections of structures (sequential sets) instead of individual items; (ii) We introduce a co-occurrence representation to discern and acknowledge the importance of different sets; (iii) We propose a sets-level optimization criterion, which integrates the diversity distribution and dependency relations across the entire sequence of sets, guiding the model to recommend relevant and diversified set. Extensive experiments on real-world datasets show that our approach consistently outperforms previous methods on both relevance and diversity.
Pay Attention to Attention for Sequential Recommendation
Oct 28, 2024



Transformer-based approaches have demonstrated remarkable success in various sequence-based tasks. However, traditional self-attention models may not sufficiently capture the intricate dependencies within items in sequential recommendation scenarios. This is due to the lack of explicit emphasis on attention weights, which play a critical role in allocating attention and understanding item-to-item correlations. To better exploit the potential of attention weights and improve the capability of sequential recommendation in learning high-order dependencies, we propose a novel sequential recommendation (SR) approach called attention weight refinement (AWRSR). AWRSR enhances the effectiveness of self-attention by additionally paying attention to attention weights, allowing for more refined attention distributions of correlations among items. We conduct comprehensive experiments on multiple real-world datasets, demonstrating that our approach consistently outperforms state-of-the-art SR models. Moreover, we provide a thorough analysis of AWRSR's effectiveness in capturing higher-level dependencies. These findings suggest that AWRSR offers a promising new direction for enhancing the performance of self-attention architecture in SR tasks, with potential applications in other sequence-based problems as well.
Learning k-Determinantal Point Processes for Personalized Ranking
Jun 23, 2024The key to personalized recommendation is to predict a personalized ranking on a catalog of items by modeling the user's preferences. There are many personalized ranking approaches for item recommendation from implicit feedback like Bayesian Personalized Ranking (BPR) and listwise ranking. Despite these methods have shown performance benefits, there are still limitations affecting recommendation performance. First, none of them directly optimize ranking of sets, causing inadequate exploitation of correlations among multiple items. Second, the diversity aspect of recommendations is insufficiently addressed compared to relevance. In this work, we present a new optimization criterion LkP based on set probability comparison for personalized ranking that moves beyond traditional ranking-based methods. It formalizes set-level relevance and diversity ranking comparisons through a Determinantal Point Process (DPP) kernel decomposition. To confer ranking interpretability to the DPP set probabilities and prioritize the practicality of LkP, we condition the standard DPP on the cardinality k of the DPP-distributed set, known as k-DPP, a less-explored extension of DPP. The generic stochastic gradient descent based technique can be directly applied to optimizing models that employ LkP. We implement LkP in the context of both Matrix Factorization (MF) and neural networks approaches, on three real-world datasets, obtaining improved relevance and diversity performances. LkP is broadly applicable, and when applied to existing recommendation models it also yields strong performance improvements, suggesting that LkP holds significant value to the field of recommender systems.
Signed Latent Factors for Spamming Activity Detection
Sep 28, 2022
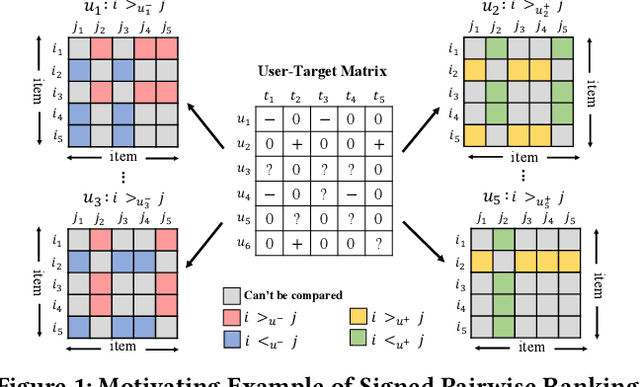
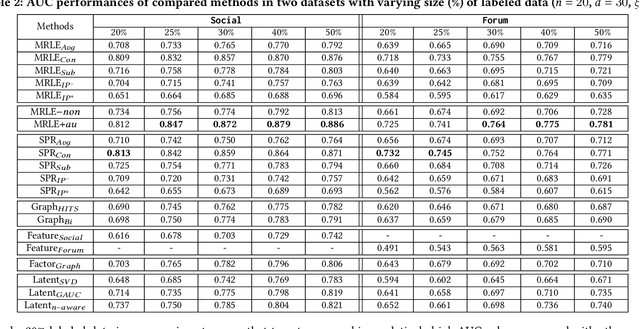
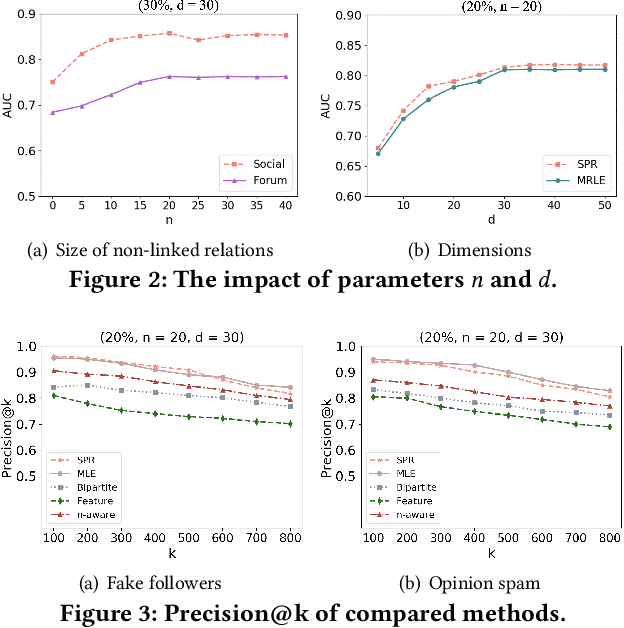
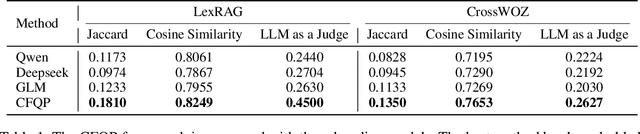
Due to the increasing trend of performing spamming activities (e.g., Web spam, deceptive reviews, fake followers, etc.) on various online platforms to gain undeserved benefits, spam detection has emerged as a hot research issue. Previous attempts to combat spam mainly employ features related to metadata, user behaviors, or relational ties. These works have made considerable progress in understanding and filtering spamming campaigns. However, this problem remains far from fully solved. Almost all the proposed features focus on a limited number of observed attributes or explainable phenomena, making it difficult for existing methods to achieve further improvement. To broaden the vision about solving the spam problem and address long-standing challenges (class imbalance and graph incompleteness) in the spam detection area, we propose a new attempt of utilizing signed latent factors to filter fraudulent activities. The spam-contaminated relational datasets of multiple online applications in this scenario are interpreted by the unified signed network. Two competitive and highly dissimilar algorithms of latent factors mining (LFM) models are designed based on multi-relational likelihoods estimation (LFM-MRLE) and signed pairwise ranking (LFM-SPR), respectively. We then explore how to apply the mined latent factors to spam detection tasks. Experiments on real-world datasets of different kinds of Web applications (social media and Web forum) indicate that LFM models outperform state-of-the-art baselines in detecting spamming activities. By specifically manipulating experimental data, the effectiveness of our methods in dealing with incomplete and imbalanced challenges is valida
Determinantal Point Process Likelihoods for Sequential Recommendation
Apr 25, 2022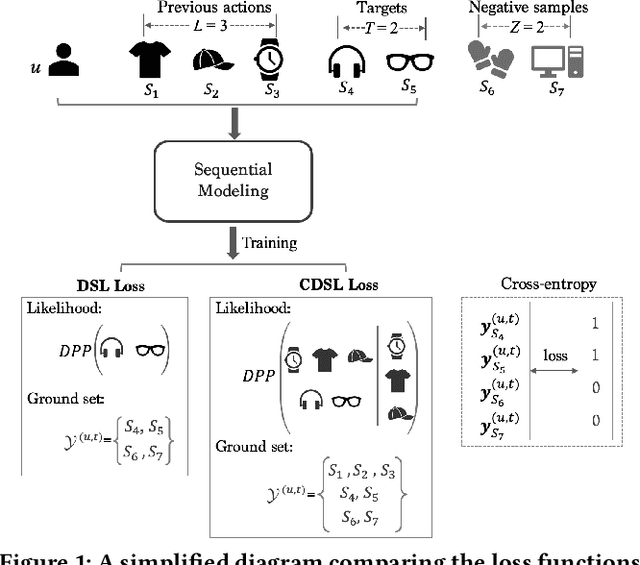
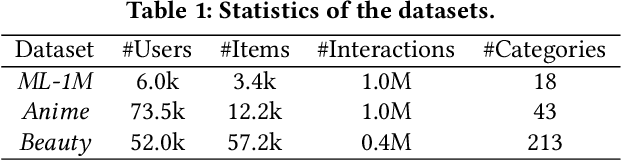
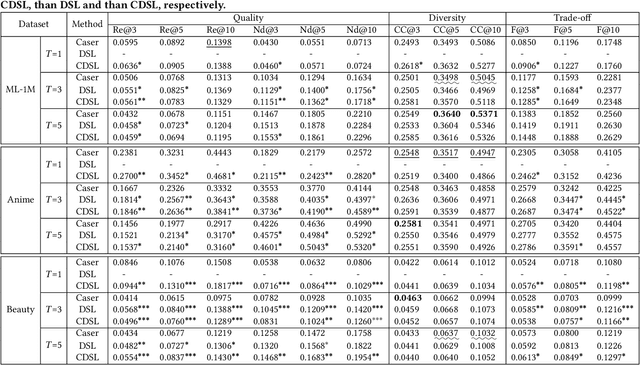
Sequential recommendation is a popular task in academic research and close to real-world application scenarios, where the goal is to predict the next action(s) of the user based on his/her previous sequence of actions. In the training process of recommender systems, the loss function plays an essential role in guiding the optimization of recommendation models to generate accurate suggestions for users. However, most existing sequential recommendation techniques focus on designing algorithms or neural network architectures, and few efforts have been made to tailor loss functions that fit naturally into the practical application scenario of sequential recommender systems. Ranking-based losses, such as cross-entropy and Bayesian Personalized Ranking (BPR) are widely used in the sequential recommendation area. We argue that such objective functions suffer from two inherent drawbacks: i) the dependencies among elements of a sequence are overlooked in these loss formulations; ii) instead of balancing accuracy (quality) and diversity, only generating accurate results has been over emphasized. We therefore propose two new loss functions based on the Determinantal Point Process (DPP) likelihood, that can be adaptively applied to estimate the subsequent item or items. The DPP-distributed item set captures natural dependencies among temporal actions, and a quality vs. diversity decomposition of the DPP kernel pushes us to go beyond accuracy-oriented loss functions. Experimental results using the proposed loss functions on three real-world datasets show marked improvements over state-of-the-art sequential recommendation methods in both quality and diversity metrics.