 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPTZero: Robust Detection of LLM-Generated Texts
Feb 13, 2026While historical considerations surrounding text authenticity revolved primarily around plagiarism, the advent of large language models (LLMs) has introduced a new challenge: distinguishing human-authored from AI-generated text. This shift raises significant concerns, including the undermining of skill evaluations, the mass-production of low-quality content, and the proliferation of misinformation. Addressing these issues, we introduce GPTZero a state-of-the-art industrial AI detection solution, offering reliable discernment between human and LLM-generated text. Our key contributions include: introducing a hierarchical, multi-task architecture enabling a flexible taxonomy of human and AI texts, demonstrating state-of-the-art accuracy on a variety of domains with granular predictions, and achieving superior robustness to adversarial attacks and paraphrasing via multi-tiered automated red teaming. GPTZero offers accurate and explainable detection, and educates users on its responsible use, ensuring fair and transparent assessment of text.
DeTra: A Unified Model for Object Detection and Trajectory Forecasting
Jun 06, 2024The tasks of object detection and trajectory forecasting play a crucial role in understanding the scene for autonomous driving. These tasks are typically executed in a cascading manner, making them prone to compounding errors. Furthermore, there is usually a very thin interface between the two tasks, creating a lossy information bottleneck. To address these challenges, our approach formulates the union of the two tasks as a trajectory refinement problem, where the first pose is the detection (current time), and the subsequent poses are the waypoints of the multiple forecasts (future time). To tackle this unified task, we design a refinement transformer that infers the presence, pose, and multi-modal future behaviors of objects directly from LiDAR point clouds and high-definition maps. We call this model DeTra, short for object Detection and Trajectory forecasting. In our experiments, we observe that \ourmodel{} outperforms the state-of-the-art on Argoverse 2 Sensor and Waymo Open Dataset by a large margin, across a broad range of metrics. Last but not least, we perform extensive ablation studies that show the value of refinement for this task, that every proposed component contributes positively to its performance, and that key design choices were made.
GoRela: Go Relative for Viewpoint-Invariant Motion Forecasting
Nov 08, 2022The task of motion forecasting is critical for self-driving vehicles (SDVs) to be able to plan a safe maneuver. Towards this goal, modern approaches reason about the map, the agents' past trajectories and their interactions in order to produce accurate forecasts. The predominant approach has been to encode the map and other agents in the reference frame of each target agent. However, this approach is computationally expensive for multi-agent prediction as inference needs to be run for each agent. To tackle the scaling challenge, the solution thus far has been to encode all agents and the map in a shared coordinate frame (e.g., the SDV frame). However, this is sample inefficient and vulnerable to domain shift (e.g., when the SDV visits uncommon states). In contrast, in this paper, we propose an efficient shared encoding for all agents and the map without sacrificing accuracy or generalization. Towards this goal, we leverage pair-wise relative positional encodings to represent geometric relationships between the agents and the map elements in a heterogeneous spatial graph. This parameterization allows us to be invariant to scene viewpoint, and save online computation by re-using map embeddings computed offline. Our decoder is also viewpoint agnostic, predicting agent goals on the lane graph to enable diverse and context-aware multimodal prediction. We demonstrate the effectiveness of our approach on the urban Argoverse 2 benchmark as well as a novel highway dataset.
LookOut: Diverse Multi-Future Prediction and Planning for Self-Driving
Jan 16, 2021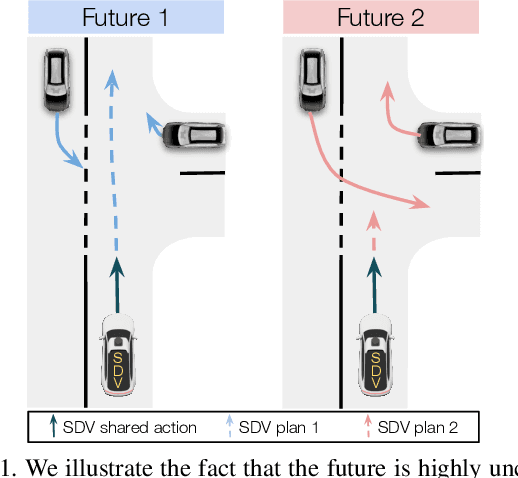
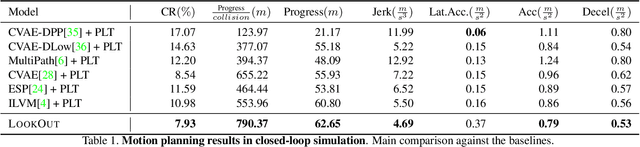

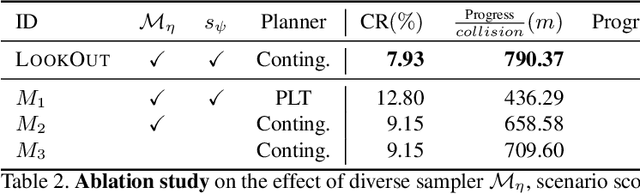
Self-driving vehicles need to anticipate a diverse set of future traffic scenarios in order to safely share the road with other traffic participants that may exhibit rare but dangerous driving. In this paper, we present LookOut, an approach to jointly perceive the environment and predict a diverse set of futures from sensor data, estimate their probability, and optimize a contingency plan over these diverse future realizations. In particular, we learn a diverse joint distribution over multi-agent future trajectories in a traffic scene that allows us to cover a wide range of future modes with high sample efficiency while leveraging the expressive power of generative models. Unlike previous work in diverse motion forecasting, our diversity objective explicitly rewards sampling future scenarios that require distinct reactions from the self-driving vehicle for improved safety. Our contingency planner then finds comfortable trajectories that ensure safe reactions to a wide range of future scenarios. Through extensive evaluations, we show that our model demonstrates significantly more diverse and sample-efficient motion forecasting in a large-scale self-driving dataset as well as safer and more comfortable motion plans in long-term closed-loop simulations than current state-of-the-art models.