 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManipBench: Benchmarking Vision-Language Models for Low-Level Robot Manipulation
May 14, 2025Vision-Language Models (VLMs) have revolutionized artificial intelligence and robotics due to their commonsense reasoning capabilities. In robotic manipulation, VLMs are used primarily as high-level planners, but recent work has also studied their lower-level reasoning ability, which refers to making decisions about precise robot movements. However, the community currently lacks a clear and common benchmark that can evaluate how well VLMs can aid low-level reasoning in robotics. Consequently, we propose a novel benchmark, ManipBench, to evaluate the low-level robot manipulation reasoning capabilities of VLMs across various dimensions, including how well they understand object-object interactions and deformable object manipulation. We extensively test 33 representative VLMs across 10 model families on our benchmark, including variants to test different model sizes. Our evaluation shows that the performance of VLMs significantly varies across tasks, and there is a strong correlation between this performance and trends in our real-world manipulation tasks. It also shows that there remains a significant gap between these models and human-level understanding. See our website at: https://manipbench.github.io.
GPT-Fabric: Folding and Smoothing Fabric by Leveraging Pre-Trained Foundation Models
Jun 14, 2024



Fabric manipulation has applications in folding blankets, handling patient clothing, and protecting items with covers. It is challenging for robots to perform fabric manipulation since fabrics have infinite-dimensional configuration spaces, complex dynamics, and may be in folded or crumpled configurations with severe self-occlusions. Prior work on robotic fabric manipulation relies either on heavily engineered setups or learning-based approaches that create and train on robot-fabric interaction data. In this paper, we propose GPT-Fabric for the canonical tasks of fabric folding and smoothing, where GPT directly outputs an action informing a robot where to grasp and pull a fabric. We perform extensive experiments in simulation to test GPT-Fabric against prior state of the art methods for folding and smoothing. We obtain comparable or better performance to most methods even without explicitly training on a fabric-specific dataset (i.e., zero-shot manipulation). Furthermore, we apply GPT-Fabric in physical experiments over 12 folding and 10 smoothing rollouts. Our results suggest that GPT-Fabric is a promising approach for high-precision fabric manipulation tasks.
Efficient inference of interventional distributions
Jul 27, 2021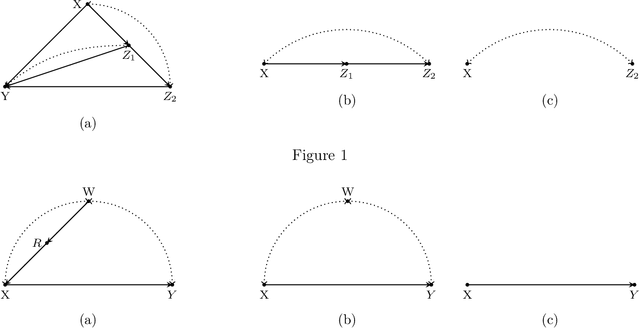
We consider the problem of efficiently inferring interventional distributions in a causal Bayesian network from a finite number of observations. Let $\mathcal{P}$ be a causal model on a set $\mathbf{V}$ of observable variables on a given causal graph $G$. For sets $\mathbf{X},\mathbf{Y}\subseteq \mathbf{V}$, and setting ${\bf x}$ to $\mathbf{X}$, let $P_{\bf x}(\mathbf{Y})$ denote the interventional distribution on $\mathbf{Y}$ with respect to an intervention ${\bf x}$ to variables ${\bf x}$. Shpitser and Pearl (AAAI 2006), building on the work of Tian and Pearl (AAAI 2001), gave an exact characterization of the class of causal graphs for which the interventional distribution $P_{\bf x}({\mathbf{Y}})$ can be uniquely determined. We give the first efficient version of the Shpitser-Pearl algorithm. In particular, under natural assumptions, we give a polynomial-time algorithm that on input a causal graph $G$ on observable variables $\mathbf{V}$, a setting ${\bf x}$ of a set $\mathbf{X} \subseteq \mathbf{V}$ of bounded size, outputs succinct descriptions of both an evaluator and a generator for a distribution $\hat{P}$ that is $\varepsilon$-close (in total variation distance) to $P_{\bf x}({\mathbf{Y}})$ where $Y=\mathbf{V}\setminus \mathbf{X}$, if $P_{\bf x}(\mathbf{Y})$ is identifiable. We also show that when $\mathbf{Y}$ is an arbitrary set, there is no efficient algorithm that outputs an evaluator of a distribution that is $\varepsilon$-close to $P_{\bf x}({\mathbf{Y}})$ unless all problems that have statistical zero-knowledge proofs, including the Graph Isomorphism problem, have efficient randomized algorithms.