 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnO: Unsupervised Occupancy Fields for Perception and Forecasting
Jun 12, 2024Perceiving the world and forecasting its future state is a critical task for self-driving. Supervised approaches leverage annotated object labels to learn a model of the world -- traditionally with object detections and trajectory predictions, or temporal bird's-eye-view (BEV) occupancy fields. However, these annotations are expensive and typically limited to a set of predefined categories that do not cover everything we might encounter on the road. Instead, we learn to perceive and forecast a continuous 4D (spatio-temporal) occupancy field with self-supervision from LiDAR data. This unsupervised world model can be easily and effectively transferred to downstream tasks. We tackle point cloud forecasting by adding a lightweight learned renderer and achieve state-of-the-art performance in Argoverse 2, nuScenes, and KITTI. To further showcase its transferability, we fine-tune our model for BEV semantic occupancy forecasting and show that it outperforms the fully supervised state-of-the-art, especially when labeled data is scarce. Finally, when compared to prior state-of-the-art on spatio-temporal geometric occupancy prediction, our 4D world model achieves a much higher recall of objects from classes relevant to self-driving.
DeTra: A Unified Model for Object Detection and Trajectory Forecasting
Jun 06, 2024The tasks of object detection and trajectory forecasting play a crucial role in understanding the scene for autonomous driving. These tasks are typically executed in a cascading manner, making them prone to compounding errors. Furthermore, there is usually a very thin interface between the two tasks, creating a lossy information bottleneck. To address these challenges, our approach formulates the union of the two tasks as a trajectory refinement problem, where the first pose is the detection (current time), and the subsequent poses are the waypoints of the multiple forecasts (future time). To tackle this unified task, we design a refinement transformer that infers the presence, pose, and multi-modal future behaviors of objects directly from LiDAR point clouds and high-definition maps. We call this model DeTra, short for object Detection and Trajectory forecasting. In our experiments, we observe that \ourmodel{} outperforms the state-of-the-art on Argoverse 2 Sensor and Waymo Open Dataset by a large margin, across a broad range of metrics. Last but not least, we perform extensive ablation studies that show the value of refinement for this task, that every proposed component contributes positively to its performance, and that key design choices were made.
QuAD: Query-based Interpretable Neural Motion Planning for Autonomous Driving
Apr 01, 2024



A self-driving vehicle must understand its environment to determine the appropriate action. Traditional autonomy systems rely on object detection to find the agents in the scene. However, object detection assumes a discrete set of objects and loses information about uncertainty, so any errors compound when predicting the future behavior of those agents. Alternatively, dense occupancy grid maps have been utilized to understand free-space. However, predicting a grid for the entire scene is wasteful since only certain spatio-temporal regions are reachable and relevant to the self-driving vehicle. We present a unified, interpretable, and efficient autonomy framework that moves away from cascading modules that first perceive, then predict, and finally plan. Instead, we shift the paradigm to have the planner query occupancy at relevant spatio-temporal points, restricting the computation to those regions of interest. Exploiting this representation, we evaluate candidate trajectories around key factors such as collision avoidance, comfort, and progress for safety and interpretability. Our approach achieves better highway driving quality than the state-of-the-art in high-fidelity closed-loop simulations.
Toward Globally Optimal State Estimation Using Automatically Tightened Semidefinite Relaxations
Aug 10, 2023In recent years, semidefinite relaxations of common optimization problems in robotics have attracted growing attention due to their ability to provide globally optimal solutions. In many cases, specific handcrafted redundant constraints are added to the relaxation in order to improve its tightness, which is usually a requirement for obtaining or certifying globally optimal solutions. These constraints are formulation-dependent and typically require a lengthy manual process to find. Instead, the present paper suggests an automatic method to find a set of sufficient redundant constraints to obtain tightness, if they exist. We first propose an efficient feasibility check to determine if a given set of variables can lead to a tight formulation. Secondly, we show how to scale the method to problems of bigger size. At no point of the entire process do we have to manually find redundant constraints. We showcase the effectiveness of the approach by providing new insights on two classical robotics problems: range-based localization and stereo-based pose estimation. Finally, we reproduce semidefinite relaxations presented in recent literature and show that our automatic method finds a smaller set of constraints sufficient for tightness than previously considered.
Implicit Occupancy Flow Fields for Perception and Prediction in Self-Driving
Aug 02, 2023



A self-driving vehicle (SDV) must be able to perceive its surroundings and predict the future behavior of other traffic participants. Existing works either perform object detection followed by trajectory forecasting of the detected objects, or predict dense occupancy and flow grids for the whole scene. The former poses a safety concern as the number of detections needs to be kept low for efficiency reasons, sacrificing object recall. The latter is computationally expensive due to the high-dimensionality of the output grid, and suffers from the limited receptive field inherent to fully convolutional networks. Furthermore, both approaches employ many computational resources predicting areas or objects that might never be queried by the motion planner. This motivates our unified approach to perception and future prediction that implicitly represents occupancy and flow over time with a single neural network. Our method avoids unnecessary computation, as it can be directly queried by the motion planner at continuous spatio-temporal locations. Moreover, we design an architecture that overcomes the limited receptive field of previous explicit occupancy prediction methods by adding an efficient yet effective global attention mechanism. Through extensive experiments in both urban and highway settings, we demonstrate that our implicit model outperforms the current state-of-the-art. For more information, visit the project website: https://waabi.ai/research/implicito.
* 19 pages, 13 figures
Learning to Search in Task and Motion Planning with Streams
Nov 25, 2021
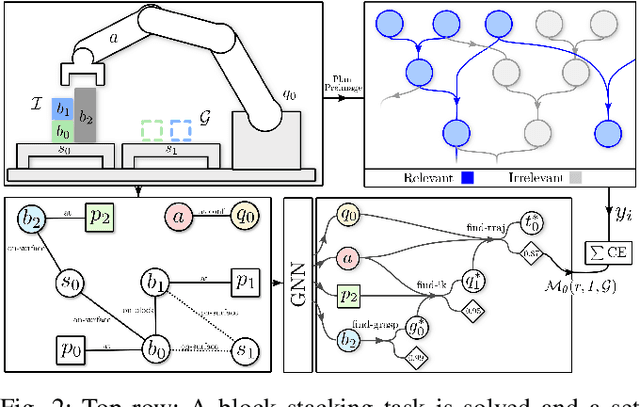
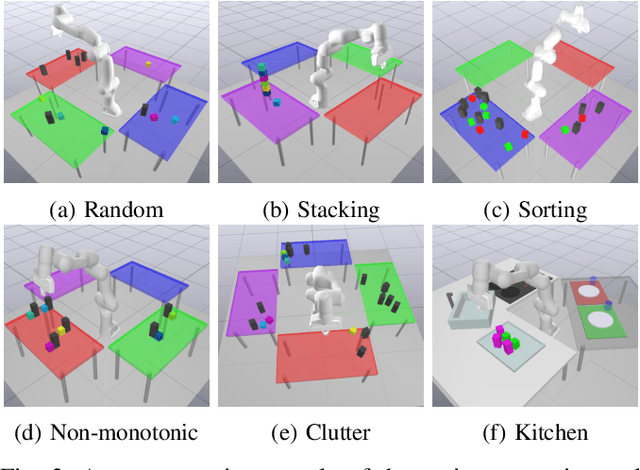
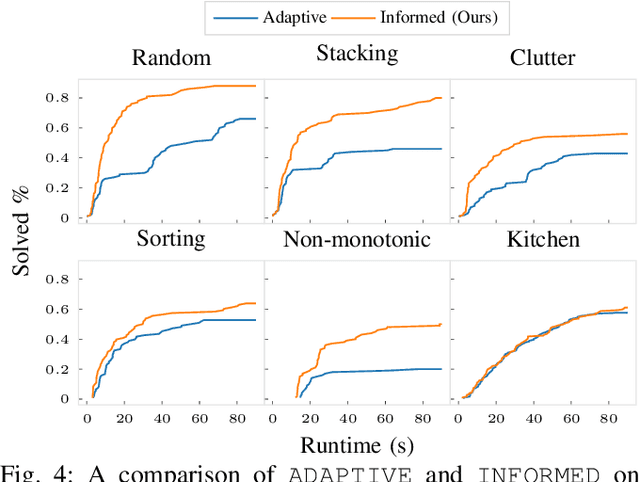
Task and motion planning problems in robotics typically combine symbolic planning over discrete task variables with motion optimization over continuous state and action variables, resulting in trajectories that satisfy the logical constraints imposed on the task variables. Symbolic planning can scale exponentially with the number of task variables, so recent works such as PDDLStream have focused on optimistic planning with an incrementally growing set of objects and facts until a feasible trajectory is found. However, this set is exhaustively and uniformly expanded in a breadth-first manner, regardless of the geometric structure of the problem at hand, which makes long-horizon reasoning with large numbers of objects prohibitively time-consuming. To address this issue, we propose a geometrically informed symbolic planner that expands the set of objects and facts in a best-first manner, prioritized by a Graph Neural Network based score that is learned from prior search computations. We evaluate our approach on a diverse set of problems and demonstrate an improved ability to plan in large or difficult scenarios. We also apply our algorithm on a 7DOF robotic arm in several block-stacking manipulation tasks.
Self-Supervised Learning of Lidar Segmentation for Autonomous Indoor Navigation
Dec 10, 2020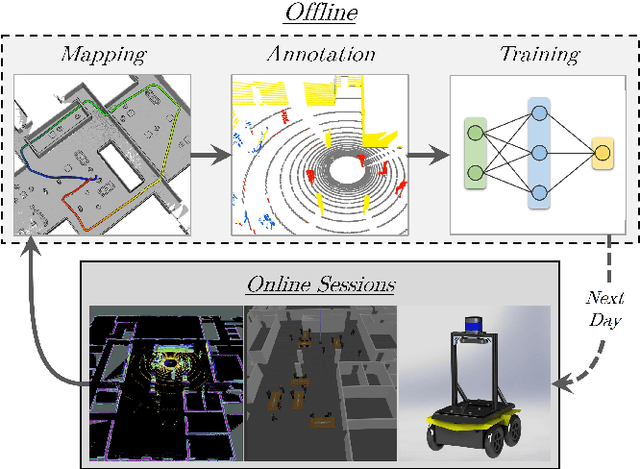
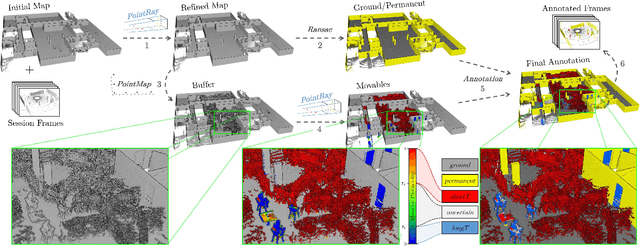
We present a self-supervised learning approach for the semantic segmentation of lidar frames. Our method is used to train a deep point cloud segmentation architecture without any human annotation. The annotation process is automated with the combination of simultaneous localization and mapping (SLAM) and ray-tracing algorithms. By performing multiple navigation sessions in the same environment, we are able to identify permanent structures, such as walls, and disentangle short-term and long-term movable objects, such as people and tables, respectively. New sessions can then be performed using a network trained to predict these semantic labels. We demonstrate the ability of our approach to improve itself over time, from one session to the next. With semantically filtered point clouds, our robot can navigate through more complex scenarios, which, when added to the training pool, help to improve our network predictions. We provide insights into our network predictions and show that our approach can also improve the performances of common localization techniques.