 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesizing and Adapting Error Correction Data for Mobile Large Language Model Applications
May 24, 2025Error correction is an important capability when applying large language models (LLMs) to facilitate user typing on mobile devices. In this paper, we use LLMs to synthesize a high-quality dataset of error correction pairs to evaluate and improve LLMs for mobile applications. We first prompt LLMs with error correction domain knowledge to build a scalable and reliable addition to the existing data synthesis pipeline. We then adapt the synthetic data distribution to match the mobile application domain by reweighting the samples. The reweighting model is learnt by predicting (a handful of) live A/B test metrics when deploying LLMs in production, given the LLM performance on offline evaluation data and scores from a small privacy-preserving on-device language model. Finally, we present best practices for mixing our synthetic data with other data sources to improve model performance on error correction in both offline evaluation and production live A/B testing.
Robo-DM: Data Management For Large Robot Datasets
May 21, 2025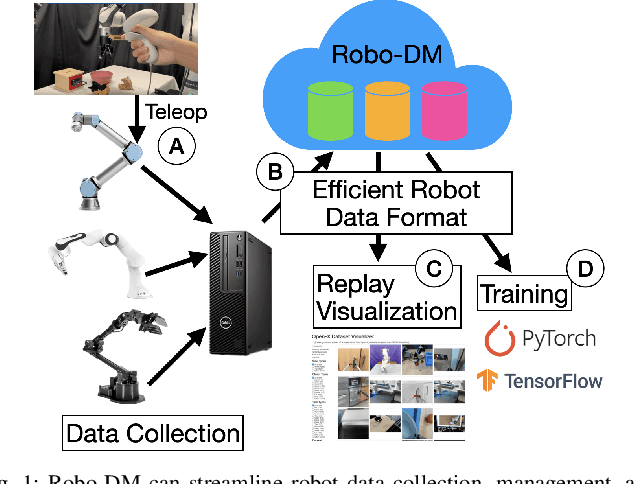
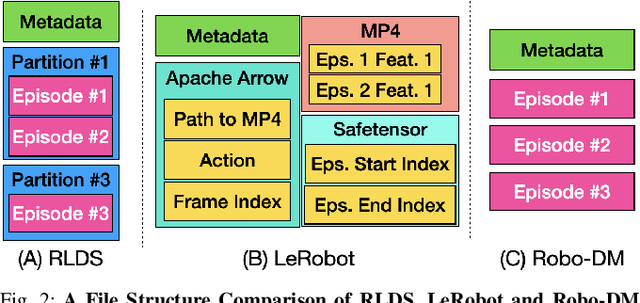
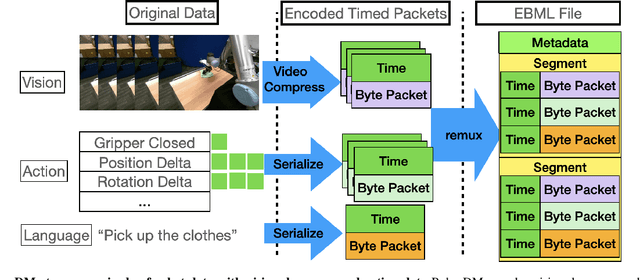
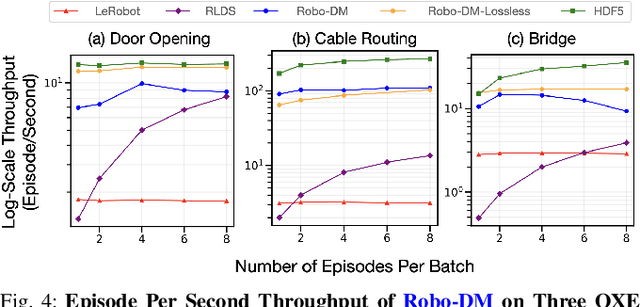
Recent results suggest that very large datasets of teleoperated robot demonstrations can be used to train transformer-based models that have the potential to generalize to new scenes, robots, and tasks. However, curating, distributing, and loading large datasets of robot trajectories, which typically consist of video, textual, and numerical modalities - including streams from multiple cameras - remains challenging. We propose Robo-DM, an efficient open-source cloud-based data management toolkit for collecting, sharing, and learning with robot data. With Robo-DM, robot datasets are stored in a self-contained format with Extensible Binary Meta Language (EBML). Robo-DM can significantly reduce the size of robot trajectory data, transfer costs, and data load time during training. Compared to the RLDS format used in OXE datasets, Robo-DM's compression saves space by up to 70x (lossy) and 3.5x (lossless). Robo-DM also accelerates data retrieval by load-balancing video decoding with memory-mapped decoding caches. Compared to LeRobot, a framework that also uses lossy video compression, Robo-DM is up to 50x faster when decoding sequentially. We physically evaluate a model trained by Robo-DM with lossy compression, a pick-and-place task, and In-Context Robot Transformer. Robo-DM uses 75x compression of the original dataset and does not suffer reduction in downstream task accuracy.
Neural Search Space in Gboard Decoder
Oct 21, 2024Gboard Decoder produces suggestions by looking for paths that best match input touch points on the context aware search space, which is backed by the language Finite State Transducers (FST). The language FST is currently an N-gram language model (LM). However, N-gram LMs, limited in context length, are known to have sparsity problem under device model size constraint. In this paper, we propose \textbf{Neural Search Space} which substitutes the N-gram LM with a Neural Network LM (NN-LM) and dynamically constructs the search space during decoding. Specifically, we integrate the long range context awareness of NN-LM into the search space by converting its outputs given context, into the language FST at runtime. This involves language FST structure redesign, pruning strategy tuning, and data structure optimizations. Online experiments demonstrate improved quality results, reducing Words Modified Ratio by [0.26\%, 1.19\%] on various locales with acceptable latency increases. This work opens new avenues for further improving keyboard decoding quality by enhancing neural LM more directly.
A Hassle-free Algorithm for Private Learning in Practice: Don't Use Tree Aggregation, Use BLTs
Aug 16, 2024



The state-of-the-art for training on-device language models for mobile keyboard applications combines federated learning (FL) with differential privacy (DP) via the DP-Follow-the-Regularized-Leader (DP-FTRL) algorithm. Two variants of DP-FTRL are used in practice, tree aggregation and matrix factorization. However, tree aggregation suffers from significantly suboptimal privacy/utility tradeoffs, while matrix mechanisms require expensive optimization parameterized by hard-to-estimate-in-advance constants, and high runtime memory costs.This paper extends the recently introduced Buffered Linear Toeplitz (BLT) mechanism to multi-participation scenarios. Our BLT-DP-FTRL maintains the ease-of-use advantages of tree aggregation, while essentially matching matrix factorization in terms of utility and privacy. We evaluate BLT-DP-FTRL on the StackOverflow dataset, serving as a re-producible simulation benchmark, and across four on-device language model tasks in a production FL system. Our empirical results highlight the advantages of the BLT mechanism and elevate the practicality and effectiveness of DP in real-world scenarios.
Proofread: Fixes All Errors with One Tap
Jun 06, 2024The impressive capabilities in Large Language Models (LLMs) provide a powerful approach to reimagine users' typing experience. This paper demonstrates Proofread, a novel Gboard feature powered by a server-side LLM in Gboard, enabling seamless sentence-level and paragraph-level corrections with a single tap. We describe the complete system in this paper, from data generation, metrics design to model tuning and deployment. To obtain models with sufficient quality, we implement a careful data synthetic pipeline tailored to online use cases, design multifaceted metrics, employ a two-stage tuning approach to acquire the dedicated LLM for the feature: the Supervised Fine Tuning (SFT) for foundational quality, followed by the Reinforcement Learning (RL) tuning approach for targeted refinement. Specifically, we find sequential tuning on Rewrite and proofread tasks yields the best quality in SFT stage, and propose global and direct rewards in the RL tuning stage to seek further improvement. Extensive experiments on a human-labeled golden set showed our tuned PaLM2-XS model achieved 85.56\% good ratio. We launched the feature to Pixel 8 devices by serving the model on TPU v5 in Google Cloud, with thousands of daily active users. Serving latency was significantly reduced by quantization, bucket inference, text segmentation, and speculative decoding. Our demo could be seen in \href{https://youtu.be/4ZdcuiwFU7I}{Youtube}.
Prompt Public Large Language Models to Synthesize Data for Private On-device Applications
Apr 05, 2024



Pre-training on public data is an effective method to improve the performance for federated learning (FL) with differential privacy (DP). This paper investigates how large language models (LLMs) trained on public data can improve the quality of pre-training data for the on-device language models trained with DP and FL. We carefully design LLM prompts to filter and transform existing public data, and generate new data to resemble the real user data distribution. The model pre-trained on our synthetic dataset achieves relative improvement of 19.0% and 22.8% in next word prediction accuracy compared to the baseline model pre-trained on a standard public dataset, when evaluated over the real user data in Gboard (Google Keyboard, a production mobile keyboard application). Furthermore, our method achieves evaluation accuracy better than or comparable to the baseline during the DP FL fine-tuning over millions of mobile devices, and our final model outperforms the baseline in production A/B testing. Our experiments demonstrate the strengths of LLMs in synthesizing data close to the private distribution even without accessing the private data, and also suggest future research directions to further reduce the distribution gap.
Efficient Language Model Architectures for Differentially Private Federated Learning
Mar 12, 2024



Cross-device federated learning (FL) is a technique that trains a model on data distributed across typically millions of edge devices without data leaving the devices. SGD is the standard client optimizer for on device training in cross-device FL, favored for its memory and computational efficiency. However, in centralized training of neural language models, adaptive optimizers are preferred as they offer improved stability and performance. In light of this, we ask if language models can be modified such that they can be efficiently trained with SGD client optimizers and answer this affirmatively. We propose a scale-invariant Coupled Input Forget Gate (SI CIFG) recurrent network by modifying the sigmoid and tanh activations in the recurrent cell and show that this new model converges faster and achieves better utility than the standard CIFG recurrent model in cross-device FL in large scale experiments. We further show that the proposed scale invariant modification also helps in federated learning of larger transformer models. Finally, we demonstrate the scale invariant modification is also compatible with other non-adaptive algorithms. Particularly, our results suggest an improved privacy utility trade-off in federated learning with differential privacy.
Federated Learning of Gboard Language Models with Differential Privacy
May 29, 2023



We train language models (LMs) with federated learning (FL) and differential privacy (DP) in the Google Keyboard (Gboard). We apply the DP-Follow-the-Regularized-Leader (DP-FTRL)~\citep{kairouz21b} algorithm to achieve meaningfully formal DP guarantees without requiring uniform sampling of client devices. To provide favorable privacy-utility trade-offs, we introduce a new client participation criterion and discuss the implication of its configuration in large scale systems. We show how quantile-based clip estimation~\citep{andrew2019differentially} can be combined with DP-FTRL to adaptively choose the clip norm during training or reduce the hyperparameter tuning in preparation for training. With the help of pretraining on public data, we train and deploy more than twenty Gboard LMs that achieve high utility and $\rho-$zCDP privacy guarantees with $\rho \in (0.2, 2)$, with two models additionally trained with secure aggregation~\citep{bonawitz2017practical}. We are happy to announce that all the next word prediction neural network LMs in Gboard now have DP guarantees, and all future launches of Gboard neural network LMs will require DP guarantees. We summarize our experience and provide concrete suggestions on DP training for practitioners.
MT-SNN: Enhance Spiking Neural Network with Multiple Thresholds
Mar 20, 2023



Spiking neural networks (SNNs), as a biology-inspired method mimicking the spiking nature of brain neurons, is a promising energy-efficient alternative to the traditional artificial neural networks (ANNs). The energy saving of SNNs is mainly from multiplication free property brought by binarized intermediate activations. In this paper, we proposed a Multiple Threshold (MT) approach to alleviate the precision loss brought by the binarized activations, such that SNNs can reach higher accuracy at fewer steps. We evaluate the approach on CIFAR10, CIFAR100 and DVS-CIFAR10, and demonstrate that MT can promote SNNs extensively, especially at early steps. For example, With MT, Parametric-Leaky-Integrate-Fire(PLIF) based VGG net can even outperform the ANN counterpart with 1 step.