 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Learning of Dynamic Planar Manipulation of Free-End Cables
May 15, 2024



Dynamic manipulation of free-end cables has applications for cable management in homes, warehouses and manufacturing plants. We present a supervised learning approach for dynamic manipulation of free-end cables, focusing on the problem of getting the cable endpoint to a designated target position, which may lie outside the reachable workspace of the robot end effector. We present a simulator, tune it to closely match experiments with physical cables, and then collect training data for learning dynamic cable manipulation. We evaluate with 3 cables and a physical UR5 robot. Results over 32x5 trials on 3 cables suggest that a physical UR5 robot can attain a median error distance ranging from 22% to 35% of the cable length among cables, outperforming an analytic baseline by 21% and a Gaussian Process baseline by 7% with lower interquartile range (IQR).
Policy-Based Bayesian Experimental Design for Non-Differentiable Implicit Models
Mar 08, 2022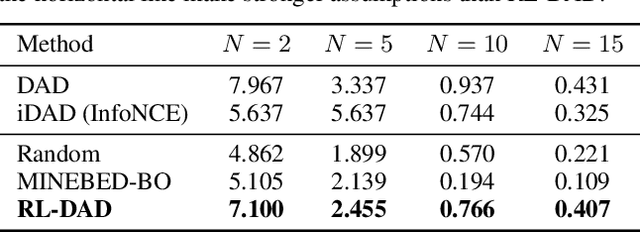
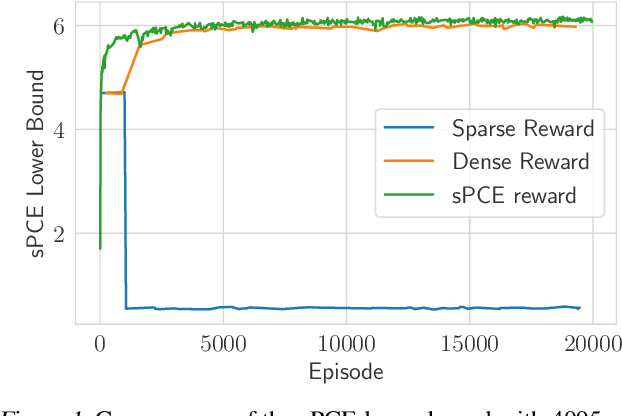
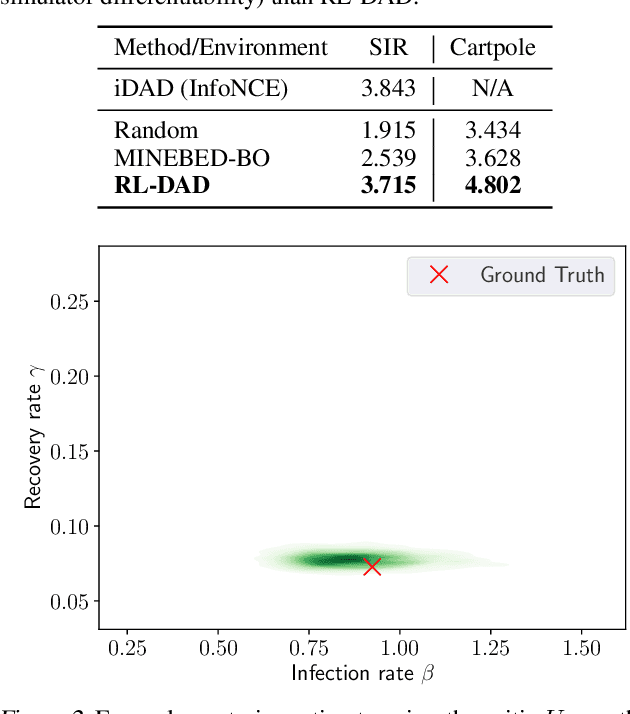
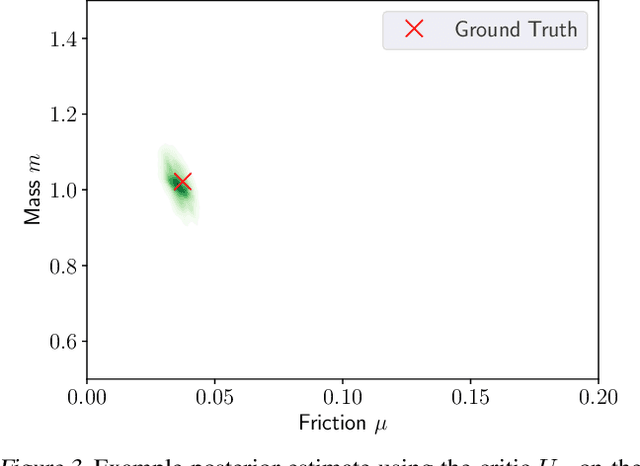
For applications in healthcare, physics, energy, robotics, and many other fields, designing maximally informative experiments is valuable, particularly when experiments are expensive, time-consuming, or pose safety hazards. While existing approaches can sequentially design experiments based on prior observation history, many of these methods do not extend to implicit models, where simulation is possible but computing the likelihood is intractable. Furthermore, they often require either significant online computation during deployment or a differentiable simulation system. We introduce Reinforcement Learning for Deep Adaptive Design (RL-DAD), a method for simulation-based optimal experimental design for non-differentiable implicit models. RL-DAD extends prior work in policy-based Bayesian Optimal Experimental Design (BOED) by reformulating it as a Markov Decision Process with a reward function based on likelihood-free information lower bounds, which is used to learn a policy via deep reinforcement learning. The learned design policy maps prior histories to experiment designs offline and can be quickly deployed during online execution. We evaluate RL-DAD and find that it performs competitively with baselines on three benchmarks.
Planar Robot Casting with Real2Sim2Real Self-Supervised Learning
Nov 08, 2021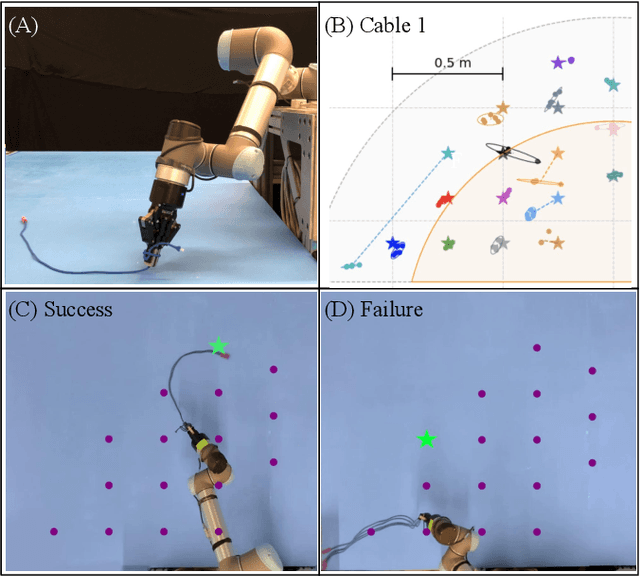
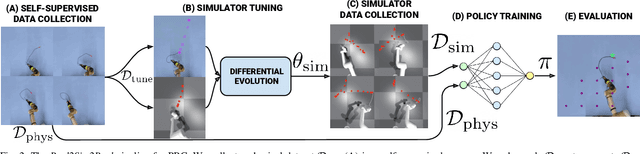
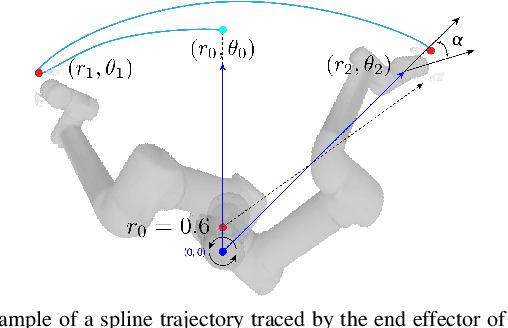

Manipulation of deformable objects using a single parameterized dynamic action can be useful for tasks such as fly fishing, lofting a blanket, and playing shuffleboard. Such tasks take as input a desired final state and output one parameterized open-loop dynamic robot action which produces a trajectory toward the final state. This is especially challenging for long-horizon trajectories with complex dynamics involving friction. This paper explores the task of Planar Robot Casting (PRC): where one planar motion of a robot wrist holding one end of a cable causes the other end to slide across the plane toward a desired target. PRC allows the cable to reach points beyond the robot's workspace and has applications for cable management in homes, warehouses, and factories. To efficiently learn a PRC policy for a given cable, we propose Real2Sim2Real, a self-supervised framework that automatically collects physical trajectory examples to tune parameters of a dynamics simulator using Differential Evolution, generates many simulated examples, and then learns a policy using a weighted combination of simulated and physical data. We evaluate Real2Sim2Real with three simulators, Isaac Gym-segmented, Isaac Gym-hybrid, and PyBullet, two function approximators, Gaussian Processes and Neural Networks (NNs), and three cables with differing stiffness, torsion, and friction. Results on 16 held-out test targets for each cable suggest that the NN PRC policies using Isaac Gym-segmented attain median error distance (as % of cable length) ranging from 8% to 14%, outperforming baselines and policies trained on only real or only simulated examples. Code, data, and videos are available at https://tinyurl.com/robotcast.
A matrix math facility for Power ISA processors
Apr 07, 2021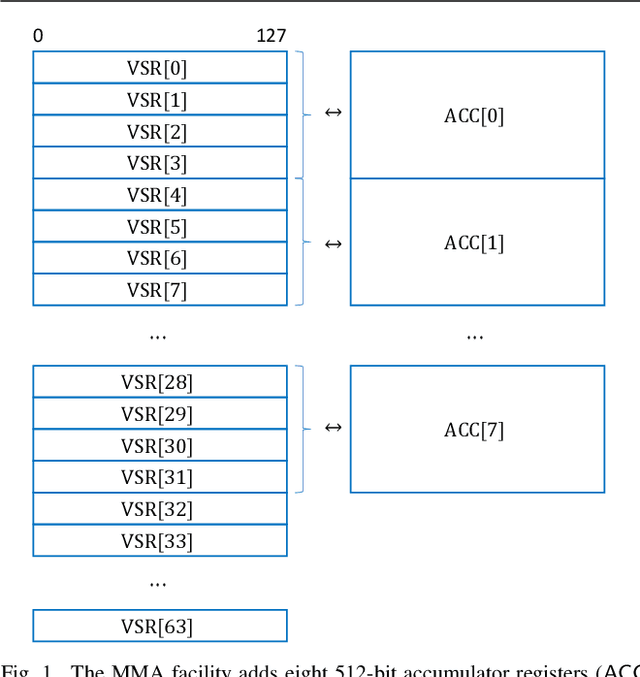
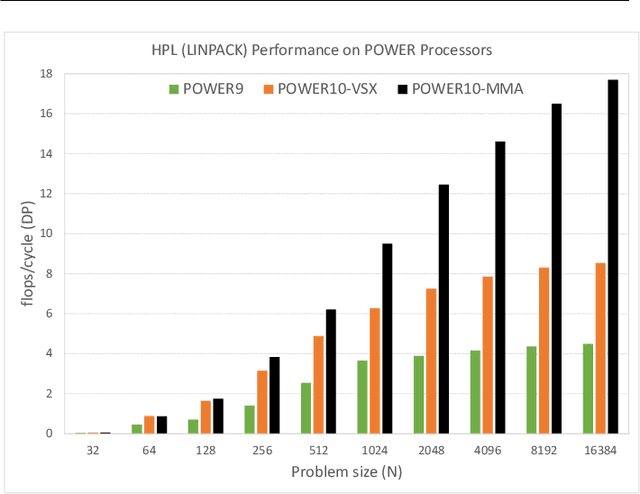
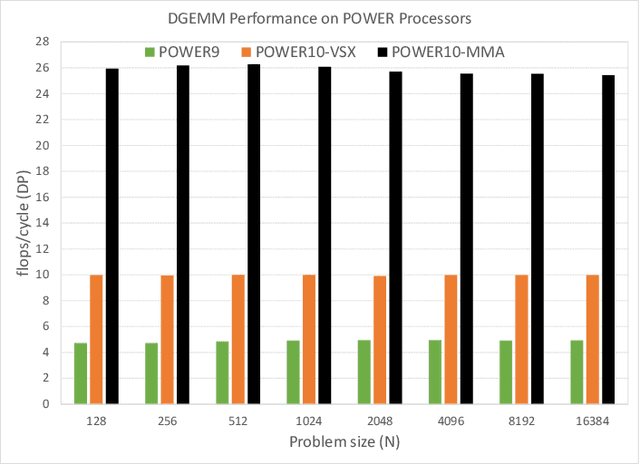
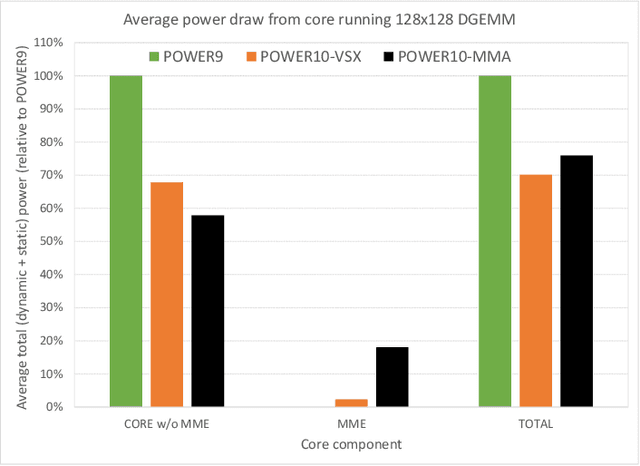
Power ISA(TM) Version 3.1 has introduced a new family of matrix math instructions, collectively known as the Matrix-Multiply Assist (MMA) facility. The instructions in this facility implement numerical linear algebra operations on small matrices and are meant to accelerate computation-intensive kernels, such as matrix multiplication, convolution and discrete Fourier transform. These instructions have led to a power- and area-efficient implementation of a high throughput math engine in the future POWER10 processor. Performance per core is 4 times better, at constant frequency, than the previous generation POWER9 processor. We also advocate the use of compiler built-ins as the preferred way of leveraging these instructions, which we illustrate through case studies covering matrix multiplication and convolution.